This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This retrieval mechanism solves a critical problem in enterprise businessintelligence (BI) environments—discovering which report or dataset has information to answer the user’s question. Lakshdeep Vatsa is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Choose Delete stack.
Orchestration platform Orq noted in a blog post that AI management systems include four key components: prompt management for consistent model interaction, integration tools, state management and monitoring tools to track performance. What do they need the AI application or agents to do, and how are these planned to support their work?
The fusion of data in a central platform enables smooth analysis to optimize processes and increase business efficiency in the world of Industry 4.0 using methods from businessintelligence , process mining and data science. Or maybe you are interested in an individual data strategy ?
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
The analyst can easily pull in the data they need, use natural language to clean up and fill any missing data, and finally build and deploy a machine learning model that can accurately predict the loan status as an output, all without needing to become a machine learning expert to do so.
The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements. A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. This blog talks about the basics of ETL and ETL tools.
Data must be combined and harmonized from multiple sources into a unified, coherent format before being used with AI models. This process is known as data integration , one of the key components to improving the usability of data for AI and other use cases, such as businessintelligence (BI) and analytics.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
With users executing over 450,000 SQL queries annually against our petabyte-scale Amazon Redshift data warehouses, our businessintelligence and analytics teams had become a critical bottleneck. The results: 90% faster query resolution (from hours to minutes) with zero dependency on businessintelligence teams.
Embracing generative AI with Amazon Bedrock The company has identified several use cases where generative AI can significantly impact operations, particularly in analytics and businessintelligence (BI). This tool democratizes data access across the organization, enabling even nontechnical users to gain valuable insights.
SageMaker Unified Studio combines various AWS services, including Amazon Bedrock , Amazon SageMaker , Amazon Redshift , Amazon Glue , Amazon Athena , and Amazon Managed Workflows for Apache Airflow (MWAA) , into a comprehensive data and AI development platform. Consider a global retail site operating across multiple regions and countries.
A well-designed data architecture should support businessintelligence and analysis, automation, and AI—all of which can help organizations to quickly seize market opportunities, build customer value, drive major efficiencies, and respond to risks such as supply chain disruptions.
Self-service analytics tools have been democratizing data-driven decision making, but also increasing the risk of inaccurate analysis and misinterpretation. A “catalog-first” approach to businessintelligence enables both empowerment and accuracy; and Alation has long enabled this combination over Tableau.
What is BusinessIntelligence? BusinessIntelligence (BI) refers to the technology, techniques, and practises that are used to gather, evaluate, and present information about an organisation in order to assist decision-making and generate effective administrative action. billion in 2015 and reached around $26.50
Data analytics is a task that resides under the data science umbrella and is done to query, interpret and visualize datasets. Data scientists will often perform data analysis tasks to understand a dataset or evaluate outcomes.
This blog was originally written by Keith Smith and updated for 2024 by Justin Delisi. Snowflake’s Data Cloud has emerged as a leader in cloud data warehousing. What is a Data Lake? A Data Lake is a location to store raw data that is in any format that an organization may produce or collect.
In the breakneck world of data, which I have been privy to since the mid 1990s, businessintelligence remains one of the most enduring terms. So I was surprised to learn from my colleague Myles Suer’s blog piece about Self-Service vs. Traditional BI that it was first referenced in 1865. Modern BusinessIntelligence.
Google Analytics 4 (GA4) is a powerful tool for collecting and analyzing website and app data that many businesses rely heavily on to make informed business decisions. It enables us to create, schedule, and monitor the datapipeline, ensuring seamless movement of data between the various sources and destinations.
It also lets you choose the right engine for the right workload at the right cost, potentially reducing your data warehouse costs by optimizing workloads. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and businessintelligence.
If you are a data scientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that data scientists already have that are transferable to data engineering. In this blog post, we will discuss how you can become a data engineer if you are a data scientist.
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for businessintelligence and data science use cases. What does a modern data architecture do for your business?
Introduction Dimensional modelling is crucial for organising data to enhance query performance and reporting efficiency. Effective schema design is essential for optimising data retrieval and analysis in data warehousing. Must Read Blogs: Exploring the Power of Data Warehouse Functionality.
In this blog, we’ll show you how to build a robust energy price forecasting solution within the Snowflake Data Cloud ecosystem. We’ll cover how to get the data via the Snowflake Marketplace, how to apply machine learning with Snowpark , and then bring it all together to create an automated ML model to forecast energy prices.
RAG optimizes language model outputs by extending the models’ capabilities to specific domains or an organization’s internal data for tailored responses. This post highlights how Twilio enabled natural language-driven data exploration of businessintelligence (BI) data with RAG and Amazon Bedrock.
How to Optimize Power BI and Snowflake for Advanced Analytics Spencer Baucke May 25, 2023 The world of businessintelligence and data modernization has never been more competitive than it is today. Microsoft Power BI has been the leader in the analytics and businessintelligence platforms category for several years running.
In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, BusinessIntelligence and Analytics tools, Data Governance , and Metadata Management solutions. The most important reason for using DBT in Data Vault 2.0
Events Data + AI Summit Data + AI World Tour DataIntelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
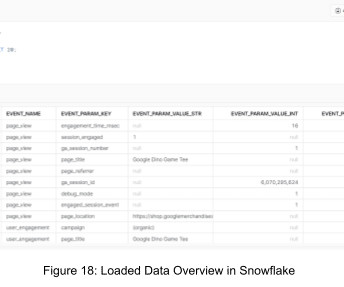
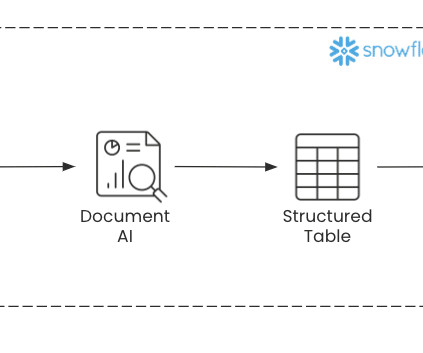
With Document AI from the Snowflake Data Cloud , organizations can utilize the power of LLMs to automate the process of converting unstructured documents into organized tables with ease! In this blog, we’ll cover what the Document AI tool is, what use cases it solves, and how to integrate it with document processing pipelines.
The more complete, accurate and consistent a dataset is, the more informed businessintelligence and business processes become. With data observability capabilities, IBM can help organizations detect and resolve issues within datapipelines faster. appeared first on IBM Blog.
AWS data engineering pipeline The adaptable approach detailed in this post starts with an automated data engineering pipeline to make data stored in Splunk available to a wide range of personas, including businessintelligence (BI) analysts, data scientists, and ML practitioners, through a SQL interface.
IBM software products are embedding watsonx capabilities across digital labor, IT automation, security, sustainability, and application modernization to help unlock new levels of business value for clients. In this blog, I will cover: What is watsonx.ai? ” Vitaly Tsivin, EVP BusinessIntelligence at AMC Networks.
Summary : This blog provides a comprehensive overview of statistical tools for data-driven research. Researchers across disciplines will find valuable insights to enhance their Data Analysis skills and produce credible, impactful findings.
. ; there has to be a business context, and the increasing realization of this context explains the rise of information stewardship applications.” – May 2018 Gartner Market Guide for Information Stewardship Applications. The rise of data lakes, IOT analytics, and big datapipelines has introduced a new world of fast, big data.
Instead of handling extract, transform and load (ETL) operations within a data lake, a data mesh defines the data as a product in multiple repositories, each given its own domain for managing its datapipeline. This lets users across the organization treat the data like a product with widespread access.
A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Data orchestration tools. Businessintelligence (BI) platforms. These tools are used to manage big data, which is defined as data that is too large or complex to be processed by traditional means.
It seamlessly integrates with IBM’s data integration, data observability, and data virtualization products as well as with other IBM technologies that analysts and data scientists use to create businessintelligence reports, conduct analyses and build AI models. Everybody wins with a data catalog.
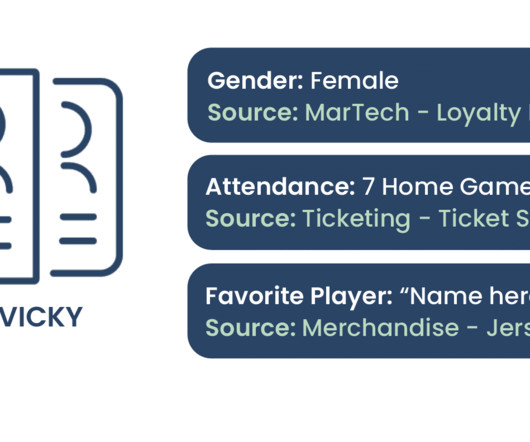
This blog was written by Sara Price and edited by Sunny Yan. In this blog, we’ll demonstrate how to utilize data to drive successful targeted and personalized campaigns for your fanbase to increase revenue, boost operational efficiency, and improve cross-departmental collaboration—all while providing an enriched fan experience.
From now on, we will launch a retraining every 3 months and, as soon as possible, will use up to 1 year of data to account for the environmental condition seasonality. When deploying this system on other assets, we will be able to reuse this automated process and use the initial training to validate our sensor datapipeline.
Data Scientists and Data Analysts have been using ChatGPT for Data Science to generate codes and answers rapidly. In the following blog, let’s look at how ChatGPT changes human function. The entire process involves cleaning, Merging and changing the data format. This data can help in building the project pipeline.
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of datapipelines. This made things simple.
Under this category, tools with pre-built connectors for popular data sources and visual tools for data transformation are better choices. This setting ensures that the datapipeline adapts to changes in the Source schema according to user-specific needs. Another way is to add the Snowflake details through Fivetran.
Datapipeline orchestration. Moving/integrating data in the cloud/data exploration and quality assessment. There are four critical components needed for a successful migration: AI/ML models to automate the discovery and semantics of the data. On-premises businessintelligence and databases.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content