
5 Portfolio Projects for Final Year Data Science Students
KDnuggets
SEPTEMBER 5, 2023
From cleaning data to wowing recruiters - this blog shares 5 killer data science projects to launch your data science career and get hired!

KDnuggets
SEPTEMBER 5, 2023
From cleaning data to wowing recruiters - this blog shares 5 killer data science projects to launch your data science career and get hired!

Analytics Vidhya
SEPTEMBER 4, 2021
This article was published as a part of the Data Science Blogathon Image 1In this blog, We are going to talk about some of the advanced and most used charts in Plotly while doing analysis. Table of content Description of Dataset Data Exploration Data Cleaning Data visualization […].
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
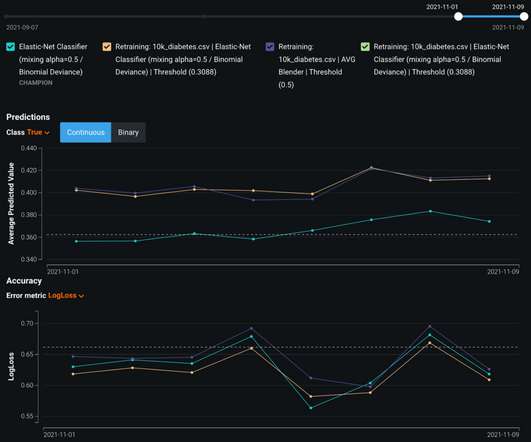
DataRobot Blog
DECEMBER 6, 2022
With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies. Explore these 10 popular blogs that help data scientists drive better data decisions. Read the blog. Read the blog.

Data Science Dojo
JANUARY 31, 2023
Big data is conventionally understood in terms of its scale. This one-dimensional approach, however, runs the risk of simplifying the complexity of big data. In this blog, we discuss the 10 Vs as metrics to gauge the complexity of big data.

Data Science Dojo
OCTOBER 23, 2023
In this blog post, we are going to share the top 10 YouTube videos for learning about LLMs. ChatGPT is a large language model that can be used for a variety of tasks, including data analysis and visualization. LLMs can be used to build a variety of applications, such as chatbots, virtual assistants, and translation tools.
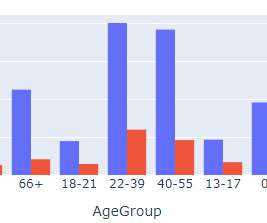
Data Science Dojo
JANUARY 22, 2023
In this blog, we will discuss exploratory data analysis, also known as EDA, and why it is important. This can be useful for identifying patterns and trends in the data. We will also be sharing code snippets so you can try out different analysis techniques yourself. So, without any further ado let’s dive right in.

phData
NOVEMBER 4, 2024
Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machine learning models. Together they create a powerful, flexible, and scalable foundation for modern data applications.

Expert insights. Personalized for you.








































Let's personalize your content