
Announcing General Availability of Liquid Clustering
databricks
MAY 22, 2024
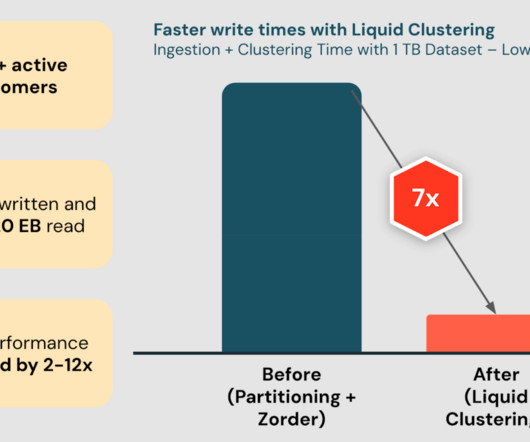
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.
This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
databricks
MAY 22, 2024
We’re excited to announce the General Availability of Delta Lake Liquid Clustering in the Databricks Data Intelligence Platform. Liquid Clustering is an innovative.

databricks
APRIL 7, 2023
We are excited to announce that cluster policies are now generally available. Why Databricks cluster policies? Databricks cluster policies enable administrators to: limit.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

databricks
MAY 10, 2023
We're excited to announce the general availability of Databricks Fleet clusters on AWS. What are Fleet clusters? Databricks Fleet clusters unlock the potential.

databricks
SEPTEMBER 4, 2023
We are thrilled to announce great enhancements to onboard more workloads to Unity Catalog clusters in shared access mode, Databricks' highly efficient, secure.

databricks
MAY 1, 2023
This blog was co-authored by Elia Florio, Sr. Director of Detection & Response at Databricks and Florian Roth and Marius Bartholdy, security researchers.

databricks
MAY 11, 2023
Introduction This blog is part of our Admin Essentials series, where we'll focus on topics important to those managing and maintaining Databricks environments.

databricks
FEBRUARY 27, 2023
Ray is a prominent compute framework for running scalable AI and Python workloads, offering a variety of distributed machine learning tools, large-scale hyperparameter.
Data Science Dojo
OCTOBER 8, 2023
In such a scenario, most men tend to cluster around the average height, with fewer individuals being exceptionally tall or short. Normal distribution The normal distribution, characterized by its bell-shaped curve, is prevalent in various natural phenomena.

databricks
MARCH 19, 2024
Lilac is a scalable, user-friendly tool for data scientists to search, cluster. Today, we are thrilled to announce that Lilac is joining Databricks.
DataRobot Blog
DECEMBER 6, 2022
With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies. Explore these 10 popular blogs that help data scientists drive better data decisions. Read the blog. Read the blog. Read the blog.

Data Science Dojo
SEPTEMBER 26, 2023
Learn about 33 tools to visualize data with this blog In this blog post, we will delve into some of the most important plots and concepts that are indispensable for any data scientist. Elbow curve: In unsupervised learning, particularly clustering, the elbow curve aids in determining the optimal number of clusters for a dataset.

Towards AI
FEBRUARY 23, 2024
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. This is called clustering. In Data Science, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.

Data Science Dojo
MARCH 8, 2023
These libraries will help you with data manipulation, data analysis, and visualization. This blog lists some of the top Python libraries for data science that can help you get started. Step 3. By learning Python, you can effectively clean and manipulate data, create visualizations, and build machine-learning models.

AWS Machine Learning Blog
DECEMBER 24, 2024
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.

databricks
JUNE 28, 2023
We are excited to announce Delta Lake 3.0, the next major release of the Linux Foundation open source Delta Lake Project, available in.

databricks
SEPTEMBER 4, 2023
We are thrilled to announce that you can run even more workloads on Databricks’ highly efficient multi-user clusters thanks to new security and g.

Towards AI
OCTOBER 19, 2024
Time Series Clustering Using Auto-Regressive Models, Moving Averages, and Nonlinear Trend Functions Photo by Ricardo Gomez Angel on Unsplash Clustering time series data, like stock prices or gene expression, is often difficult. This member-only story is on us. Upgrade to access all of Medium.

NOVEMBER 27, 2024
The CloudFormation template provisions the following components An Aurora MySQL provisioned cluster (source) An Amazon Redshift Serverless data warehouse (target) Zero-ETL integration between the source (Aurora MySQL) and target (Amazon Redshift Serverless) To create your resources: Sign in to the console.

Data Science Dojo
MARCH 8, 2024
This blog delves into a detailed comparison between the two data management techniques. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process. A file records vectors that belong to each cluster.

Hacker News
NOVEMBER 24, 2024
Drawing from Kuaishou's experience in implementing cloud-native Redis at scale, this blog delves into practical solutions and critical considerations for managing stateful services in Kubernetes environments.

Towards AI
SEPTEMBER 3, 2024
We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. The black line running through the data points is the regression line, which represents the… Read the full blog for free on Medium. I’m trying out a new thing: I draw illustrations of graphs, etc., Join thousands of data leaders on the AI newsletter.

Towards AI
MAY 8, 2024
K-means is probably one of the most clustering algorithms out there. In a nutshell, what K-means does to produce its clusters is to find the centers of data, called as centroids, and assign data points to the center where they are closest. Join thousands of data leaders on the AI newsletter. From research to projects and ideas.

Data Science Blog
FEBRUARY 28, 2023
Clustering, unterzogen, bei dem die Website-Besucher:innen aufgrund ihrer Ähnlichkeiten in verschiedenen Eigenschaften in Gruppen („Cluster“) eingeteilt wurden. Dieses Clustering lieferte dem Unternehmen bereits wertvolle Informationen. The post Praxisbeispiel: Data Science im Marketing appeared first on Data Science Blog.

AWS Machine Learning Blog
APRIL 22, 2024
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.

Towards AI
NOVEMBER 1, 2024
Key Details: Meta is training Llama 4 on a massive setup with over 100,000 H100 GPUs, one of the largest AI clusters reported, aiming for faster and more capable models than ever.The new Llama 4 will introduce advanced capabilities like expanded memory, support for multiple data types, and seamless third-party integrations.AI

AWS Machine Learning Blog
NOVEMBER 26, 2024
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
AWS Machine Learning Blog
JULY 25, 2024
Solution overview The solution is based on the node problem detector and recovery DaemonSet, a powerful tool designed to automatically detect and report various node-level problems in a Kubernetes cluster. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. #

AWS Machine Learning Blog
SEPTEMBER 18, 2024
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
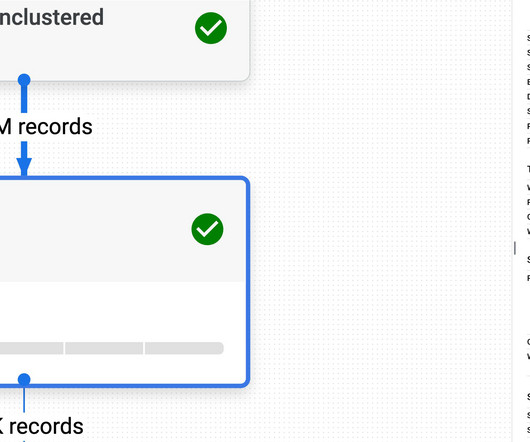
Hacker News
FEBRUARY 5, 2024
In this blog post, we'll do a deep-dive into a simple trick that can reduce BigQuery costs by orders of magnitude. Specifically, we'll explore how clustering (similar to indexing in BigQuery world) large tables can significantly impact costs.
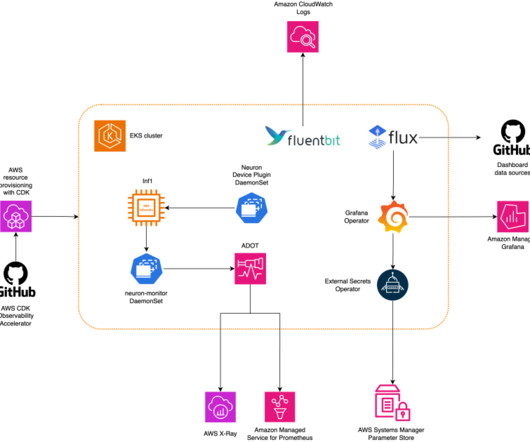
AWS Machine Learning Blog
APRIL 17, 2024
This post walks you through the Open Source Observability pattern for AWS Inferentia , which shows you how to monitor the performance of ML chips, used in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster, with data plane nodes based on Amazon Elastic Compute Cloud (Amazon EC2) instances of type Inf1 and Inf2.

Hacker News
DECEMBER 9, 2023
In this blog post, we explore Spotify's journey from using the Fisher-Yates shuffle to a more sophisticated song shuffling algorithm that prevents clustering of tracks by the same artist. We then connect this challenge to Fibonacci hashing, and propose a novel, evenly distributed artist shuffling method.

Data Science Dojo
FEBRUARY 1, 2023
In this blog, we will explore how to optimize performance and reduce costs when using dedicated SQL pools in Azure Synapse Analytics. A clustered column store index is created on a table with a clustered column store architecture. DWUs (Data Warehouse Units) can customize resources and optimize performance and costs.

AWS Machine Learning Blog
OCTOBER 24, 2024
For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. Implementation steps Load data to the Amazon Redshift cluster Connect to your Amazon Redshift cluster using Query Editor v2.

AWS Machine Learning Blog
OCTOBER 16, 2024
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),

AWS Machine Learning Blog
MARCH 3, 2025
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Hacker News
MARCH 2, 2025
Fang-Pen Lin's blog about programming

Towards AI
JANUARY 29, 2025
clustering, dimensionality reduction)Model Evaluation and SelectionData Preprocessing and Feature Engineering With a simple and consistent API, Scikit-learn is widely regarded as the go-to library for fast prototyping and efficient deployment of machine learning models. Scikit-learn is an open-source machine learning library built on Python.

Analytics Vidhya
APRIL 11, 2023
This blog post introduces a series of upcoming […] The post Unleash Your Data Insights: Learn from the Experts in Our DataHour Sessions appeared first on Analytics Vidhya. Introduction Analytics Vidhya DataHour is designed to provide valuable insights and knowledge to individuals looking to build a career in the data-tech industry.

Data Science Dojo
MAY 3, 2023
This blog will aim to clear concepts of how this additional tool can help you efficiently access data, especially when there are clear patterns involved. Clustered Indexes : have ordered files and built on non-unique columns. You may only build a single Primary or Clustered index on a table.
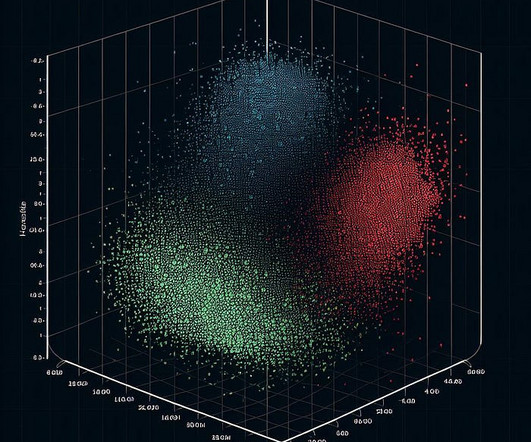
Towards AI
OCTOBER 20, 2023
Using n_init and K-Means++ image by Flo K-Means is a widely-used clustering algorithm in Machine Learning, boasting numerous benefits but also presenting significant challenges. K-Means is a clustering algorithm that partitions data into K clusters. Each cluster is represented by a color.

Data Science Dojo
FEBRUARY 15, 2023
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. IoT, Web 3.0,

Data Science Blog
JUNE 13, 2023
Das Vorgehen Um die verschiedenen Kundengruppen zu identifizieren, sollten die Kund:innen mithilfe einer Clustering-Analyse in klar voneinander abgegrenzte Segmente eingeteilt werden. Der Vorteil an diesem Vorgehen ist, dass bei einer Clustering-Analyse eine Vielzahl an Eigenschaften gleichzeitig betrachtet werden kann.

Hacker News
JUNE 12, 2024
Meta is currently operating many data centers with GPU training clusters across the world. Meta’s training infrastructure comprises dozens of AI clusters of varying sizes, with a plan to scale to 600,000 GPUs in the next year. In this blog we will discuss only one of these transformations. And what do we mean by maintaining?
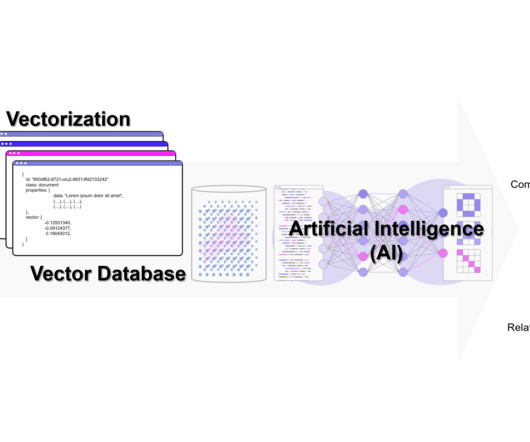
Data Science Blog
MAY 22, 2023
der k-Nächste-Nachbarn -Prädiktionsalgorithmus (Regression/Klassifikation) oder K-Means-Clustering. Die Texte müssen in diese transformiert werden, eventuell auch nach diesen in Cluster eingeteilt und für verschiedene Trainingsszenarien separiert werden. appeared first on Data Science Blog.

Expert insights. Personalized for you.
We have resent the email to
Are you sure you want to cancel your subscriptions?





Let's personalize your content