This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Its mounted at /fsx on the head and compute nodes. Scheduler : SLURM is used as the job scheduler for the cluster.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
It is important to consider the massive amount of compute often required to train these models. When using computeclusters of massive size, a single failure can often throw a training job off course and may require multiple hours of discovery and remediation from customers.
In this post, we seek to separate a time series dataset into individual clusters that exhibit a higher degree of similarity between its data points and reduce noise. The purpose is to improve accuracy by either training a global model that contains the cluster configuration or have local models specific to each cluster.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
Machine Learning is a subset of Artificial Intelligence and ComputerScience that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of Data Science, the use of statistical methods are crucial in training algorithms in order to make classification.
With technological developments occurring rapidly within the world, ComputerScience and Data Science are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in Data Science job roles, transitioning your career from ComputerScience to Data Science can be quite interesting.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. In this blog, we will use Amazon Bedrock Guardrails to introduce safeguards, prevent harmful content, and evaluate models against key safety criteria.
For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training. We also used AWS ParallelCluster to manage cluster orchestration. Before moving to industry, Tahir earned an M.S.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
ML is a computerscience, data science and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
Set up the CloudWatch Observability EKS add-on Refer to Install the Amazon CloudWatch Observability EKS add-on for instructions to create the amazon-cloudwatch-observability add-on in your EKS cluster. The Container Insights dashboard also shows cluster status and alarms. os operator: In values: - linux - key: node.kubernetes.io/instance-type
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. Breanne holds a Bachelor of Science in Computer Engineering from University of Illinois at Urbana Champaign.
Apart from the ability to easily provision compute, there are other factors such as cluster resiliency, cluster management (CRUD operations), and developer experience, which can impact LLM training. It provides resilient and persistent clusters for large-scale deep learning training of FMs on long-running computeclusters.
In this blog, you’ll get a clear view of how to evaluate LLMs. Developed by OpenAI, it’s one of the most extensive benchmarks available, containing 57 subjects that range from general knowledge areas like history and geography to specialized fields like law, medicine, and computerscience. What is its Purpose?
Asheesh holds a wide portfolio of hardware and software patents, including a real-time C++ DSL, IoT hardware devices, Computer Vision and Edge AI prototypes. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing, and Artificial Intelligence.
Training setup We provisioned a managed computecluster comprised of 16 dl1.24xlarge instances using AWS Batch. We developed an AWS Batch workshop that illustrates the steps to set up the distributed training cluster with AWS Batch. More specifically, a fully managed AWS Batch compute environment is created with DL1 instances.
In this blog, we will step on a journey through the corridors of mathematical and scientific history, where we encounter the most influential equations that have shaped the course of human knowledge and innovation. Information theory is used in many different areas of communication, computerscience, and statistics.
With Trainium available in AWS Regions worldwide, developers don’t have to take expensive, long-term compute reservations just to get access to clusters of GPUs to build their models. In this part, we used the AWS pcluster command to run a.yaml file to generate the cluster. 32xlarge instance featuring 32 GB of VRAM.
In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. It then replaces any faulty instances, if necessary, to make sure the training script starts running on a healthy cluster of instances.
Whether you’re a seasoned tech professional looking to switch lanes, a fresh graduate planning your career trajectory, or simply someone with a keen interest in the field, this blog post will walk you through the exciting journey towards becoming a data scientist. Machine learning Machine learning is a key part of data science.
Organizations that want to build their own models or want granular control are choosing Amazon Web Services (AWS) because we are helping customers use the cloud more efficiently and leverage more powerful, price-performant AWS capabilities such as petabyte-scale networking capability, hyperscale clustering, and the right tools to help you build.
In this blog, we will take a deep dive into LLMs, including their building blocks, such as embeddings, transformers, and attention. To test your knowledge, we have included a crossword or quiz at the end of the blog. They are typically trained on clusters of computers or even on cloud computing platforms.
Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. In the processing job API, provide this path to the parameter of submit_jars to the node of the Spark cluster that the processing job creates. We attached the IAM role to the Redshift cluster that we created earlier.
Delete your ECS cluster. Delete your EKS cluster. He holds a Bachelor’s degree in ComputerScience and Bioinformatics. Amazon ECS configuration For Amazon ECS, create a task definition that references your custom Docker image. Clean up your SageMaker resources. Refer to the following resources to get started: Neuron 2.18
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. The managed infrastructure of SageMaker and features like processing jobs, training jobs, and hyperparameter tuning jobs can use Ray libraries underneath for distributed computing. You can specify resource requirements in actors too.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning.
These computerscience terms are often used interchangeably, but what differences make each a unique technology? This blog post will clarify some of the ambiguity. Observing patterns in the data allows a deep-learning model to cluster inputs appropriately. appeared first on IBM Blog. Learn more about watsonx.ai
Introduction Hash functions are crucial in computerscience and cryptography. In this blog, we will explore hash functions in detail, their properties, types, and real-world applications. Hash functions are essential tools in computerscience and information security. They convert data into fixed-size outputs.
Solution overview We deploy FedML into multiple EKS clusters integrated with SageMaker for experiment tracking. EKS Blueprints helps compose complete EKS clusters that are fully bootstrapped with the operational software that is needed to deploy and operate workloads. Chaoyang He is Co-founder and CTO of FedML, Inc.,
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. The State of AI Report gives the size and owners of the largest A100 clusters, the top few being Meta with 21,400, Tesla with 16,000, XTX with 10,000, and Stability AI with 5,408.
In this blog post, we will learn how CCC leveraged Amazon SageMaker hosting and other AWS services to deploy or host multiple multi-modal models into an ensemble inference pipeline. Christopher earned his Bachelor of Science in ComputerScience from Northeastern Illinois University.
Botnets Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Read more to learn about the data flow, the challenges, and the way we get successful results of botnet detection. Here’s how.
This can be especially useful when recommending blogs, news articles, and other text-based content. Figure 8: K-nearest neighbor algorithm (source: Towards Data Science ). Several clustering algorithms (e.g., means and spectral clustering) can be used in recommendation engines. Or requires a degree in computerscience?
Hey guys, we will see some of the Best and Unique Machine Learning Projects for final year engineering students in today’s blog. This is going to be a very interesting blog, so without any further due, let’s do it… 1. Self-Organizing Maps In this blog, we will see how we can implement self-organizing maps in Python.
She is a technologist with a PhD in ComputerScience, a master’s degree in Education Psychology, and years of experience in data science and independent consulting in AI/ML. This post proposes Auto-CoT, which samples questions with diversity and generates reasoning chains to construct the demonstrations.
As an example, in the following figure, we separate Cover 3 Zone (green cluster on the left) and Cover 1 Man (blue cluster in the middle). We design an algorithm that automatically identifies the ambiguity between these two classes as the overlapping region of the clusters.
In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases. Clustered under visual encoding , we have topics of self-service analysis , authoring , and computer assistance.
These models may include regression, classification, clustering, and more. Data Engineering: Laying the Foundation for Data Success While Data Science deals with data analysis and insights, Data Engineering focuses on the design, construction, and maintenance of robust data pipelines and infrastructure.
Figure 8: Architecture of variational autoencoder (source: Yadav, “Variational Autoencoders,” Data-Science-Blog , 2022 ). Feature Learning Autoencoders can learn meaningful features from input data, which can be used for downstream machine learning tasks like classification, clustering, or regression. That’s not the case.
If you spend even a few minutes on KNIME’s website or browsing through their whitepapers and blog posts, you’ll notice a common theme: a strong emphasis on data science and predictive modeling. Building a Time Series ARIMA Model The final predictive model that we will look at in this blog post is the ARIMA time series model.
Training involved a dataset of over 15 trillion tokens across two GPU clusters, significantly more than Meta Llama 2. In the SageMaker notebook, navigate to the Meta-Llama-on-AWS/blob/text2sql-blog/RAG-recipes directory and open llama3-chromadb-text2sql.ipynb. Outside of work, he loves to spend time with his wife and kids.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






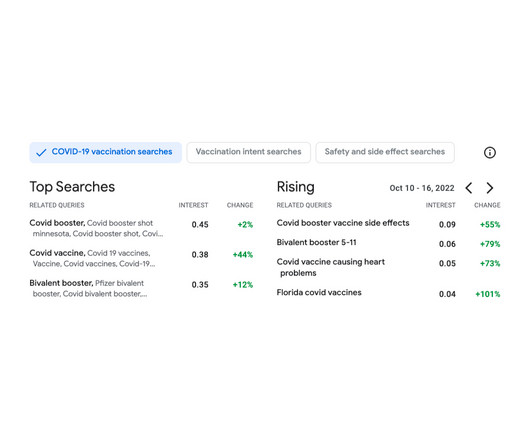











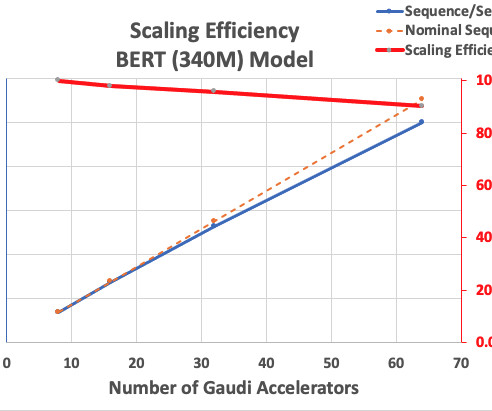
































Let's personalize your content