This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies. Explore these 10 popular blogs that help data scientists drive better data decisions. Read the blog. Read the blog.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis.
A provisioned or serverless Amazon Redshift data warehouse. For this post we’ll use a provisioned Amazon Redshift cluster. Set up the Amazon Redshift cluster We’ve created a CloudFormation template to set up the Amazon Redshift cluster. A SageMaker domain. A QuickSight account (optional). Database name : Enter dev.
It is a cloud-native approach, and it suits a small team that does not want to host, maintain, and operate a Kubernetes cluster alonewith all the resulting responsibilities (and costs). The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. It provides a large cluster of clusters on a single machine. AWS SageMaker is useful for creating basic models, including regression, classification, and clustering. Are you struggling with managing MLOps tools?
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can view and create EMR clusters directly through the SageMaker notebook.
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service. For data handling, 24 data nodes (r6gd.2xlarge.search
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine. Conclusion.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Solution workflow In this section, we discuss how the different components work together, from data acquisition to spatial modeling and forecasting, serving as the core of the UHI solution. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
Solution overview In brief, the solution involved building three pipelines: Datapipeline – Extracts the metadata of the images Machine learning pipeline – Classifies and labels images Human-in-the-loop review pipeline – Uses a human team to review results The following diagram illustrates the solution architecture.
Please provide this image (and any other images and GIFs) in the blog to the BAIR Blog editors directly. The `static/blog` directory is a location on the blog server which permanently stores the images/GIFs in BAIR Blog posts. The text directly below gets tweets to work. Please adjust according to your post.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Here we use RedshiftDatasetDefinition to retrieve the dataset from the Redshift cluster. We attached the IAM role to the Redshift cluster that we created earlier.
As an active contributor to the emerging fields of Generative AI and Edge AI, Asheesh shares his knowledge and insights through tech blogs and as a speaker at various industry conferences and forums. He currently is working on Generative AI for data integration. Dhawal Patel is a Principal Machine Learning Architect at AWS.
This blog was originally written by Keith Smith and updated for 2024 by Justin Delisi. Snowflake’s Data Cloud has emerged as a leader in cloud data warehousing. Snowflake also acts as a serverless compute layer, where the virtual warehouses being used to do work can be turned on or off many times over the course of the day.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
PII Detected tagged documents are fed into Logikcull’s search index cluster for their users to quickly identify documents that contain PII entities. The request is handled by Logikcull’s application servers hosted on Amazon EC2 and the servers communicates with the search index cluster to find the documents.
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. In this case, the max cluster count should also be two.
Dreaming of a Data Science career but started as an Analyst? This guide unlocks the path from Data Analyst to Data Scientist Architect. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. It’s a programming model that allows you to create distributed objects that maintain an internal state and can be accessed concurrently by multiple tasks running on different nodes in a Ray cluster.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning.
In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in. ML model evaluation is an essential part of the MLOps pipeline. It quantifies how well each sample fits within its assigned cluster compared to other clusters.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know. Cloud Platforms: AWS, Azure, Google Cloud, etc.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Kafka helps simplify the communication between customers and businesses, using its datapipeline to accurately record events and keep records of orders and cancellations—alerting all relevant parties in real-time.
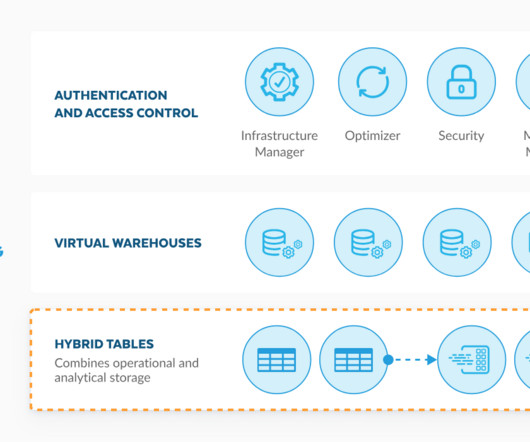
What insights could you derive from having your transactional and analytical data in one place? In this blog, we’ll go over what Hybrid tables are, how they differ from standard Snowflake tables, and some real-world scenarios where using Hybrid tables in your Snowflake account would be beneficial. appeared first on phData.
At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration.
Then we needed to Dockerize the application, write a deployment YAML file, deploy the gRPC server to our Kubernetes cluster, and make sure it’s reliable and auto scalable. After reading a few blog posts and DJL’s official documentation, we were sure DJL would provide the best solution to our problem.
If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics. In this blog, we’ll show you step-by-step how to achieve real-time analytics with Snowflake via the Kafka Connector and Snowpipe.
Data, technology, and improved trade execution could all be utilized by businesses to increase investment returns, spur innovation, and provide better investor experiences. Data movements lead to high costs of ETL and rising data management TCO.
In this blog, our focus will be on exploring the data lifecycle along with several Design Patterns, delving into their benefits and constraints. Data architects can leverage these patterns as starting points or reference models when designing and implementing data vault architectures.
Artifacts due to data augmentation: In NLP processes, data augmentation techniques like back translation and synonym replacement can sometimes inadvertently introduce near duplicate data points. Image data Datasets naturally contain duplicate images due to several interrelated processes. Clustering Techniques (e.g.,
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Python : Great for including AI in Python-based software or datapipelines.
In this blog, we’re going to answer these questions and more. Walking you through the biggest challenges we have found when migrating our customer’s data from a legacy system to Snowflake. You’re in luck because this blog is for anyone ready to move or thinking about moving to Snowflake who wants to know what’s in store for them.
We’ll explore how factors like batch size, framework selection, and the design of your datapipeline can profoundly impact the efficient utilization of GPUs. One way to lower the percentage here is to increase the batch size so that the GPU spends less time fetching the data. The pipeline involves several steps.
With its user-friendly interface and robust architecture, NiFi simplifies the complexities of data integration, making it an essential component for modern data-driven enterprises. This blog delves into the fundamentals of Apache NiFi, its architecture, and how it can leverage for effective data flow management.
The system’s architecture ensures the data flows through the different systems effectively. First, the data lake is fed from a number of data sources. These include conversational data, ATS Data and more. Sense onboarded Iguazio as an MLOps solution for the ML training and serving component of the pipeline.
Use SageMaker Processing Jobs to easily run inference on your large Dataset with Hugging Face’s Transformer Models Photo by Alex Kulikov on Unsplash This blog will give you a complete walk through of running a distributed batch inference on large data in production. It also requires a minimum change in our existing code.
The system’s architecture ensures the data flows through the different systems effectively. First, the data lake is fed from a number of data sources. These include conversational data, ATS data, and more. Sense onboarded Iguazio as an MLOps platform for the ML training and serving component of the pipeline.
In this blog, we’ll explore the phData Toolkit, why the Advisor Tool is an integral part of it, and the top 5 use cases for the Advisor Tool. While working on many data engineering projects, phData found patterns of issues that would come up regularly when migrating clients’ data. What is the phData Toolkit?
Whenever anyone talks about data lineage and how to achieve it, the spotlight tends to shine on automation. This is expected, as automating the process of calculating and establishing lineage is crucial to understanding and maintaining a trustworthy system of datapipelines. Contact your IBM representative for more information.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content