This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learn about 33 tools to visualize data with this blog In this blog post, we will delve into some of the most important plots and concepts that are indispensable for any data scientist. Entropy: These plots are critical in the field of decisiontrees and ensemble learning.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. IoT, Web 3.0,
Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples.
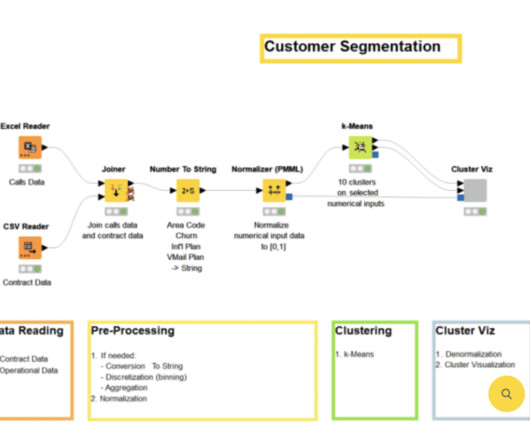
Summary: Classifier in Machine Learning involves categorizing data into predefined classes using algorithms like Logistic Regression and DecisionTrees. It’s crucial for applications like spam detection, disease diagnosis, and customer segmentation, improving decision-making and operational efficiency across various sectors.
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning. What is DecisionTree in Machine Learning?
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the DecisionTree. This often occurs in Cluster Analysis, where we identify clusters without prior information. Before we start, please consider following me on Medium or LinkedIn.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. Consequently, each brand of the decisiontree will yield a distinct result.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive.
Imagine a world where your business could make smarter decisions, predict customer behavior with astonishing accuracy, and automate tasks that used to take hours of manual labor. Popular choices include: Supervised learning algorithms like linear regression or decisiontrees for problems with labeled data.
Naïve Bayes algorithms include decisiontrees , which can actually accommodate both regression and classification algorithms. Random forest algorithms —predict a value or category by combining the results from a number of decisiontrees.
Meanwhile, many predictive AI models apply these statistical algorithms and machine learning models: Clustering classifies different data points or observations into groups or clusters based on similarities to understand underlying data patterns. appeared first on IBM Blog.
This blog post features a predictive maintenance use case within a connected car infrastructure, but the discussed components and architecture are helpful in any industry. Tiered Storage enables long-term storage with low cost and the ability to more easily operate large Kafka clusters.
In data mining, popular algorithms include decisiontrees, support vector machines, and k-means clustering. For beginners, it can seem daunting to dive into the world of data mining, but by following the tips outlined in this blog post, they can start their journey on the right foot.
If you spend even a few minutes on KNIME’s website or browsing through their whitepapers and blog posts, you’ll notice a common theme: a strong emphasis on data science and predictive modeling. In this blog post, we will visit a few types of predictive models that are available in either the base KNIME installation or via a free extension.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decisiontree.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decisiontree.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Linear Regression DecisionTrees Support Vector Machines Neural Networks Clustering Algorithms (e.g., Machine learning(ML) is evolving at a very fast pace.
In this blog, we will delve into the fundamental concepts of data model for Machine Learning, exploring their types. A data model for Machine Learning is a mathematical representation or algorithm that learns patterns and relationships from data to make predictions or decisions without being explicitly programmed.
Accordingly, Examples of Supervised learning include linear regression, logistic regression , decisiontrees, random forests and neural networks. Significantly, there are two types of Unsupervised Learning: Clustering: which involves grouping similar data points together. Additionally, Supervised learning predicts the output.
The blog delves into their applications, emphasizing real-world examples in healthcare, finance, retail, and technology. From predicting patient outcomes to optimizing inventory management, these techniques empower decision-makers to navigate data landscapes confidently, fostering informed and strategic decision-making.
Whether you’re a seasoned tech professional looking to switch lanes, a fresh graduate planning your career trajectory, or simply someone with a keen interest in the field, this blog post will walk you through the exciting journey towards becoming a data scientist. It’s time to turn your question into a quest.
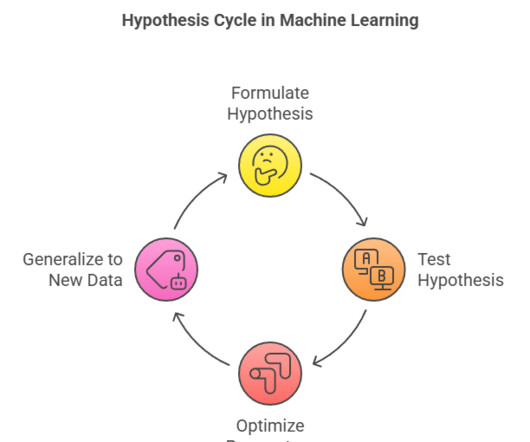
Introduction Machine Learning is revolutionizing industries by enabling systems to learn from data and make predictions or decisions. This blog explores the role of hypothesis in Machine Learning , their formulation, representation, testing, and optimization. DecisionTrees: Represent hypothesis as conditional rules.
This blog aims to clarify the concept of inductive bias and its impact on model generalisation, helping practitioners make better decisions for their Machine Learning solutions. In contrast, decisiontrees assume data can be split into homogeneous groups through feature thresholds.
In Data Analysis, Statistical Modeling is essential for drawing meaningful conclusions and guiding decision-making. This blog aims to explain what Statistical Modeling is, highlight its key components, and explore its applications across various sectors. Popular clustering algorithms include k-means and hierarchical clustering.
In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in. Clustering Metrics Clustering is an unsupervised learning technique where data points are grouped into clusters based on their similarities or proximity.
However, if you are new to the tech domain and want to learn Machine Learning for free, then in this blog, we will take you through the 3 best options to start your ML learning journey. Moreover, you will also learn the use of clustering and dimensionality reduction algorithms. Why pursue a career in the ML domain? Lakhs to ₹ 28.4
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. Clustering and dimensionality reduction are common tasks in unSupervised Learning. Decisiontrees are easy to interpret but prone to overfitting. For a regression problem (e.g.,
A separate blog post describes the results and winners of the Hindcast Stage , all of whom won prizes in subsequent phases. This blog post presents the winners of all remaining stages: Forecast Stage where models made near-real-time forecasts for the 2024 forecast season. Won by rasyidstat.
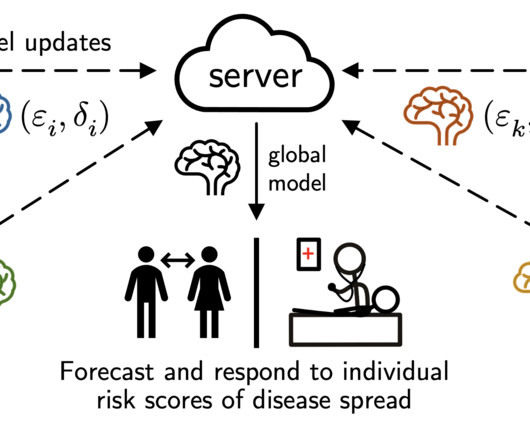
Finetune : a common baseline for model personalization; IFCA / HypCluster : hard clustering of client models; Ditto : a recently proposed method for personalized FL. Scalable, private, and federated trees for tabular data. MR-MTL : mean-regularized multi-task learning, which consistently outperform other baselines.
The following blog will provide you a thorough evaluation on how Anomaly Detection Machine Learning works, emphasising on its types and techniques. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm.
These embeddings are useful for various natural language processing (NLP) tasks such as text classification, clustering, semantic search, and information retrieval. Sentence transformers are powerful deep learning models that convert sentences into high-quality, fixed-length embeddings, capturing their semantic meaning.
Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decisiontrees, and support vector machines. It includes regression, classification, clustering, decisiontrees, and more.
In this blog, we will delve into three specific use cases where the KNIME-Snowflake combination is effectively deployed in the financial services industry. This could involve a range of techniques, such as logistic regression, decisiontrees, or even more advanced methods like neural networks. What is KNIME & Snowflake?
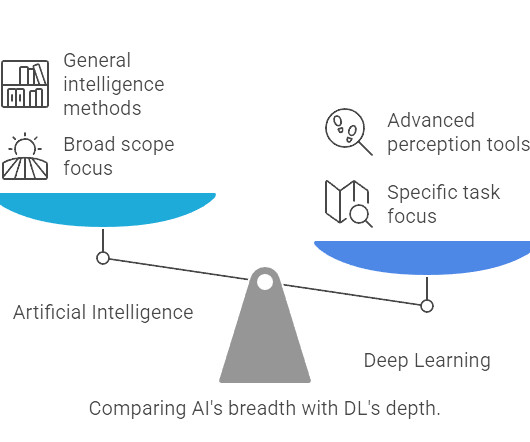
This blog post aims to demystify these powerful concepts. AI is a broad field focused on simulating human intelligence, encompassing techniques like decisiontrees and rule-based systems. Is Deep Learning just another name for AI? Is all AI Deep Learning? What sets them apart?
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. On Lines 21-27 , we define a Node class, which represents a node in a decisiontree. We first start by defining the Node of an iTree.
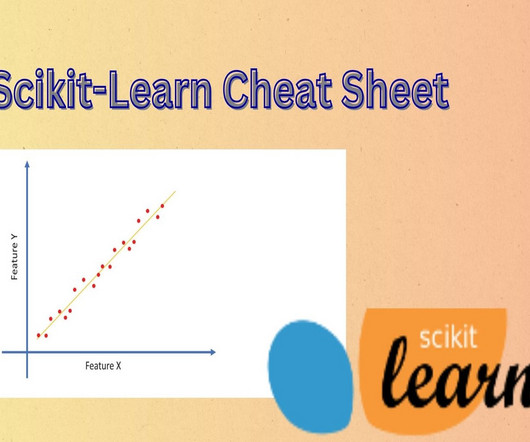
DecisionTree) Making Predictions Evaluating Model Accuracy (Classification) Feature Scaling (Standardization) Getting Started Before diving into the intricacies of Scikit-Learn, let’s start with the basics. The cheat sheet helps you select the right one for your specific task, be it regression, classification, or clustering.
Hence, you can use R for classification, clustering, statistical tests and linear and non-linear modelling. Packages like caret, random Forest, glmnet, and xgboost offer implementations of various machine learning algorithms, including classification, regression, clustering, and dimensionality reduction. How is R Used in Data Science?
It’s also much more difficult to see how the intricate network of neurons processes the input data than to comprehend, say, a decisiontree. That said, many of the machine learning visualization techniques I covered in my last blog post apply to deep learning models as well.
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. Decisiontrees are more prone to overfitting. Some algorithms that have low bias are DecisionTrees, SVM, etc.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. This blog outlines essential Machine Learning Engineer skills to help you thrive in this fast-evolving field. The global Machine Learning market was valued at USD 35.80
1 KNN 2 DecisionTree 3 Random Forest 4 Naive Bayes 5 Deep Learning using Cross Entropy Loss To some extent, Logistic Regression and SVM can also be leveraged to solve a multi-class classification problem by fitting multiple binary classifiers using a one-vs-all or one-vs-one strategy. A set of classes sometimes forms a group/cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content