This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Underpinning most artificial intelligence (AI) deeplearning is a subset of machine learning that uses multi-layered neural networks to simulate the complex decision-making power of the human brain. Deeplearning requires a tremendous amount of computing power.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. The reasons for this range from wrongly connected model components to misconfigured optimizers.
Although setting up a processing cluster is an alternative, it introduces its own set of complexities, from data distribution to infrastructure management. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster. format("/".join(tile_prefix),
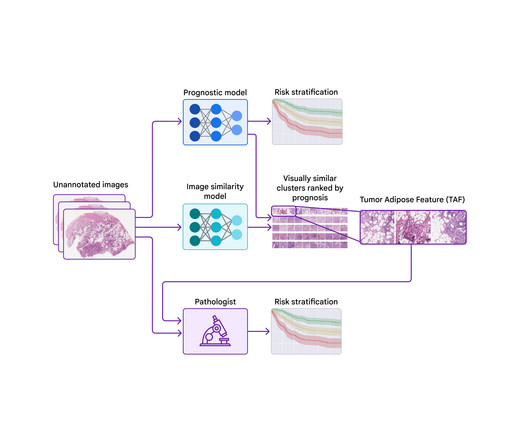
To our knowledge, this is the first demonstration that medical experts can learn new prognostic features from machine learning, a promising start for the future of this “learning from deeplearning” paradigm. We then used the prognostic model to compute the average ML-predicted risk score for each cluster.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deeplearning workloads in the cloud.
This blog lists down-trending data science, analytics, and engineering GitHub repositories that can help you with learning data science to build your own portfolio. What is GitHub? It provides a range of algorithms for classification, regression, clustering, and more.
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. supports the Llama 3.1 (and Outside of work, he enjoys running, hiking, and cooking.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves.
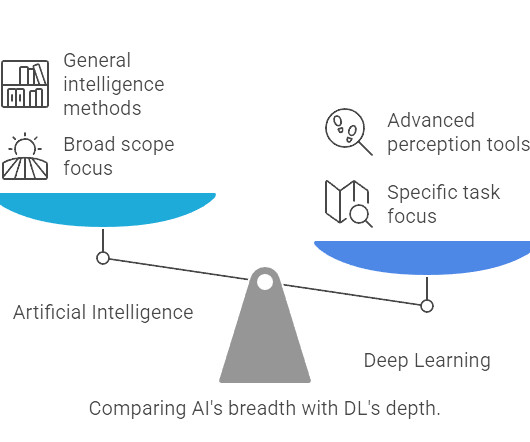
While artificial intelligence (AI), machine learning (ML), deeplearning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. This blog post will clarify some of the ambiguity. Machine learning is a subset of AI.
Summary: Artificial Intelligence (AI) and DeepLearning (DL) are often confused. AI vs DeepLearning is a common topic of discussion, as AI encompasses broader intelligent systems, while DL is a subset focused on neural networks. Is DeepLearning just another name for AI? Is all AI DeepLearning?
Summary: Machine Learning and DeepLearning are AI subsets with distinct applications. Introduction In todays world of AI, both Machine Learning (ML) and DeepLearning (DL) are transforming industries, yet many confuse the two. Clustering and anomaly detection are examples of unsupervised learning tasks.
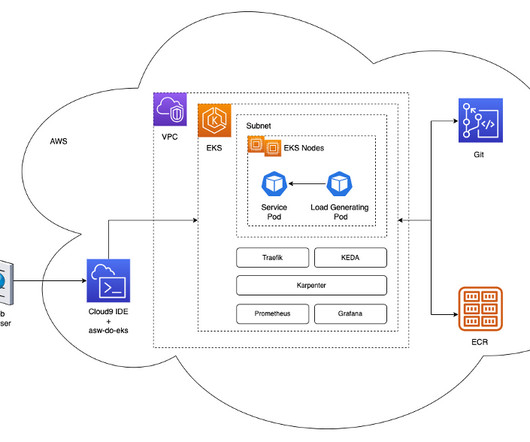
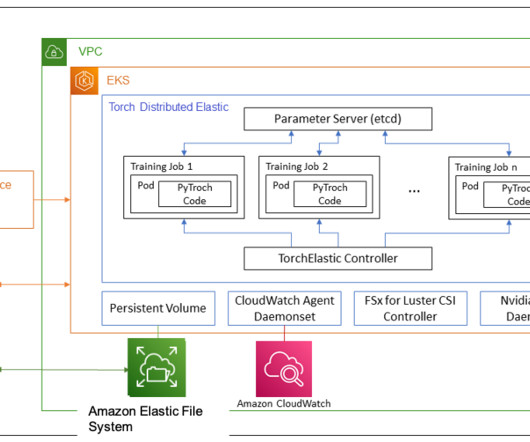
Distributed model training requires a cluster of worker nodes that can scale. In this blog post, AWS collaborates with Meta’s PyTorch team to discuss how to use the PyTorch FSDP library to achieve linear scaling of deeplearning models on AWS seamlessly using Amazon EKS and AWS DeepLearning Containers (DLCs).
Introduction to DeepLearning Algorithms: Deeplearning algorithms are a subset of machine learning techniques that are designed to automatically learn and represent data in multiple layers of abstraction. How DeepLearning Algorithms Work?
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Integrating tensor parallelism to enable training on massive clusters This release of SMP also expands PyTorch FSDP’s capabilities to include tensor parallelism techniques.
In this blog post, we’ll explain how Multichannel transcription and Speaker Diarization work, what their outputs look like, and how you can implement them using AssemblyAI. Speaker Embeddings with DeepLearning models : Once the audio is segmented, each segment is processed using a deeplearning model to extract speaker embeddings.
In this blog post, we will delve into the mechanics of the Grubbs test, its application in anomaly detection, and provide a practical guide on how to implement it using real-world data. The core of the blog post focuses on the Grubbs test, a powerful statistical method for detecting outliers in normally distributed data. Thakur, eds.,
Recent developments in deeplearning have led to increasingly large models such as GPT-3, BLOOM, and OPT, some of which are already in excess of 100 billion parameters. Many enterprise customers choose to deploy their deeplearning workloads using Kubernetes—the de facto standard for container orchestration in the cloud.
Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. PyTorch and TensorFlow These are commonly used deeplearning frameworks that offer immense flexibility in building RAG models. Content creation It primarily deals with writing articles and blogs.
Our deeplearning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. xlarge nodes is included to run system pods that are needed by the cluster.
release , you can now launch Neuron DLAMIs (AWS DeepLearning AMIs) and Neuron DLCs (AWS DeepLearning Containers) with the latest released Neuron packages on the same day as the Neuron SDK release. AWS DLCs provide a set of Docker images that are pre-installed with deeplearning frameworks.
The skill clusters are formed via the discipline of Topic Modelling , a method from unsupervised machine learning , which show the differences in the distribution of requirements between them. The post Monitoring of Jobskills with Data Engineering & AI appeared first on Data Science Blog.
Libraries such as DeepSpeed (an open-source deeplearning optimization library for PyTorch) address some of these challenges, and can help accelerate model development and training. Training setup We provisioned a managed compute cluster comprised of 16 dl1.24xlarge instances using AWS Batch. Pre-training of a 1.5-billion-parameter
With containers, scaling on a cluster becomes much easier. In late 2022, AWS announced the general availability of Amazon EC2 Trn1 instances powered by AWS Trainium accelerators, which are purpose built for high-performance deeplearning training. On the Amazon ECS console, choose Clusters in the navigation pane.
In this blog post, we will discuss three popular word embedding techniques, namely Word2Vec , Doc2Vec , and Top2Vec. Image taken from Efficient Estimation of Word Representation in Vector Space Top2Vec Top2Vec is an unsupervised machine-learning model designed for topic modelling and document clustering.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
Hyperparameter optimization is highly computationally demanding for deeplearning models. In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. to launch the cluster. eks-create.sh
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. It removes the undifferentiated heavy lifting involved in building and optimizing machine learning (ML) infrastructure for training foundation models (FMs).
For example, on a commercially available cluster of 3,584 H100 GPUs co-developed by startup Inflection AI and operated by CoreWeave , a cloud service provider specializing in GPU-accelerated workloads, the system completed the massive GPT-3-based training benchmark in less than eleven minutes.
AWS Trainium instances for training workloads SageMaker ml.trn1 and ml.trn1n instances, powered by Trainium accelerators, are purpose-built for high-performance deeplearning training and offer up to 50% cost-to-train savings over comparable training optimized Amazon Elastic Compute Cloud (Amazon EC2) instances.
Unsupervised machine learning Unsupervised learning algorithms—like Apriori, Gaussian Mixture Models (GMMs) and principal component analysis (PCA)—draw inferences from unlabeled datasets, facilitating exploratory data analysis and enabling pattern recognition and predictive modeling. Explore the watsonx.ai
Since then, this feature has been integrated into many of our managed Amazon Machine Images (AMIs), such as the DeepLearning AMI and the AWS ParallelCluster AMI. Create an EKS cluster with a node group This group includes a GPU instance family of your choice; in this example, we use the g5.2xlarge instance type. env-config.sh
In this blog, we will focus on one such developed aspect of AI called adaptive AI. Unsupervised Learning : The system learns patterns and structures in unlabeled data, often identifying hidden relationships or clustering similar data points. It has led to enhanced use of AI in various real-world applications.
The underlying DeepLearning Container (DLC) of the deployment is the Large Model Inference (LMI) NeuronX DLC. He focuses on developing scalable machine learning algorithms. 32xlarge Meta Llama 3.1 32xlarge Meta Llama 3.1 70B Neuron meta-textgenerationneuron-llama-3-1-70b ml.trn1.32xlarge ml.trn1.32xlarge, ml.trn1n.32xlarge,
We continued our efforts in developing new algorithms for handling large datasets in various areas, including unsupervised and semi-supervised learning , graph-based learning , clustering , and large-scale optimization. Inspired by the success of multi-core processing (e.g., The big challenge here is to achieve fast (e.g.,
bashrc conda activate ft-embedding-blog Add the newly created Conda environment to Jupyter: python -m ipykernel install --user --name=ft-embedding-blog From the Launcher, open the repository folder named embedding-finetuning-blog and open the file Embedding Blog.ipynb.
This integration can help you better understand the traffic impact on your distributed deeplearning algorithms. Set up the CloudWatch Observability EKS add-on Refer to Install the Amazon CloudWatch Observability EKS add-on for instructions to create the amazon-cloudwatch-observability add-on in your EKS cluster.
Figure 5: Architecture of Convolutional Autoencoder for Image Segmentation (source: Bandyopadhyay, “Autoencoders in DeepLearning: Tutorial & Use Cases [2023],” V7Labs , 2023 ). VAEs can generate new samples from the learned latent distribution, making them ideal for image generation and style transfer tasks.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. He focuses on developing scalable machine learning algorithms. Youngsuk Park is a Sr.
For more details on how Webex is harnessing generative AI to enhance collaboration and customer engagement, see Webex | Exceptional Experiences for Every Interaction on the Webex blog. The topic clustering model achieves this by clustering all the individually extracted call drivers from a large batch of calls into different topic clusters.
For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training. We also used AWS ParallelCluster to manage cluster orchestration.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deeplearning training. In this post, we showed cost-efficient training of LLMs on AWS deeplearning hardware. Ben Snyder is an applied scientist with AWS DeepLearning.
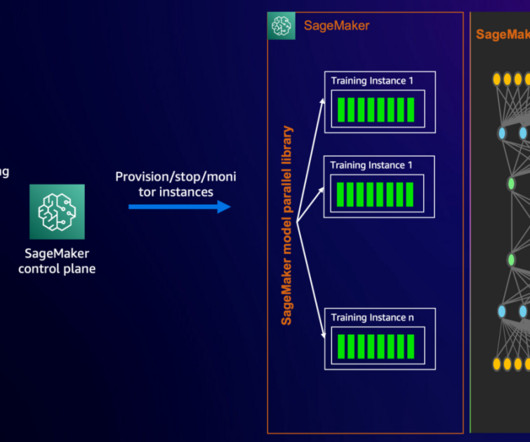
You can use SageMaker to scale your training cluster to thousands of accelerators, with your own choice of compute and optimize your workloads for performance with SageMaker distributed training libraries. After the training is complete, SageMaker spins down the cluster and the customer is billed for the net training time in seconds.
Apart from the ability to easily provision compute, there are other factors such as cluster resiliency, cluster management (CRUD operations), and developer experience, which can impact LLM training. It provides resilient and persistent clusters for large-scale deeplearning training of FMs on long-running compute clusters.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content