This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Electronic design automation (EDA) is a market segment consisting of software, hardware and services with the goal of assisting in the definition, planning, design, implementation, verification and subsequent manufacturing of semiconductor devices (or chips). The primary providers of this service are semiconductor foundries or fabs.
This blog post introduces a series of upcoming […] The post Unleash Your Data Insights: Learn from the Experts in Our DataHour Sessions appeared first on Analytics Vidhya. Introduction Analytics Vidhya DataHour is designed to provide valuable insights and knowledge to individuals looking to build a career in the data-tech industry.
Becoming a real-time enterprise Businesses often go on a journey that traverses several stages of maturity when they establish an EDA. Kafka clusters can be automatically scaled based on demand, with full encryption and access control. Flexible and customizable Kafka configurations can be automated by using a simple user interface.
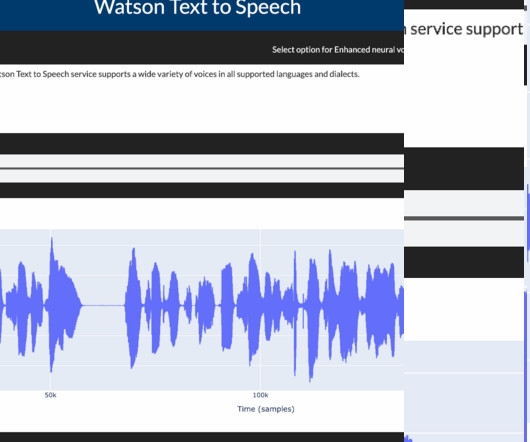
This blog gives an overview of how to convert text data into speech and how to control speech rate & voice pitch using Watson Speech libraries. Data Processing and EDA (Exploratory Data Analysis) Speech synthesis services require that the data be in a JSON format. Speech data output 3.
And annotations would be an effective way for exploratory data analysis (EDA) , so I recommend you to immediately start annotating about 10 random samples at any rate. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them. “Shut up and annotate!”
Some of the Data Science Projects on Github that you work upon have been listed in this blog. Using Netflix user data, you need to undertake Data Analysis for running workflows like EDA, Data Visualisation and interpretation. You will need to use the K-clustering method for this GitHub data mining project. Let’s take a look!
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. EDA provides insights into the data distribution and informs the selection of appropriate preprocessing techniques.
Exploratory Data Analysis (EDA) EDA is a crucial step where Data Scientists visually explore and analyze the data to identify patterns, trends, and potential correlations. These models may include regression, classification, clustering, and more.
For Data Analysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as Exploratory Data Analysis. First learn the basics of Feature Engineering, and EDA then take some different-different data sheets (data frames) and apply all the techniques you have learned to date.
Load and Explore Data We load the Telco Customer Churn dataset and perform exploratory data analysis (EDA). EDA is essential for gaining insights into the dataset’s characteristics and identifying any data preprocessing requirements. Are there clusters of customers with different spending patterns? #3.
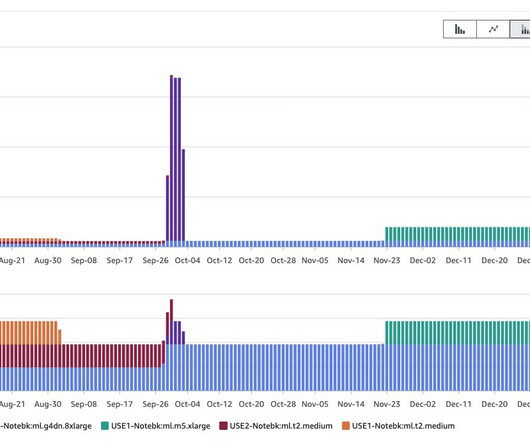
For ML model development, the size of a SageMaker notebook instance depends on the amount of data you need to load in-memory for meaningful exploratory data analyses (EDA) and the amount of computation required. We recommend starting small with general-purpose instances (such as T or M families) and scaling up as needed. For example, ml.t2.medium
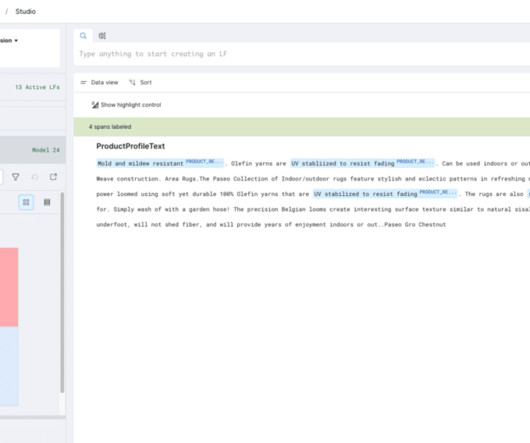
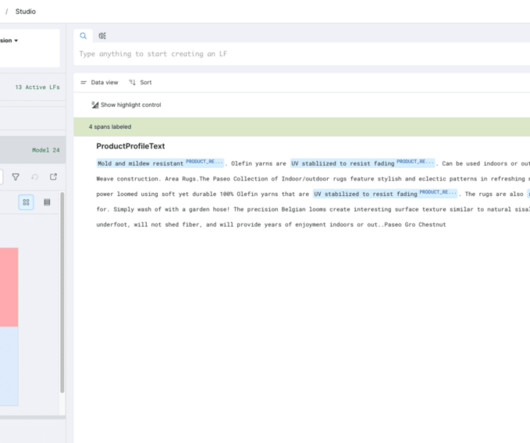
In this blog post, we walk through an anonymized real-world use case comparing a variety of state-of-the-art LLMs (GPT 4, GPT 3.5, In this blog post, we’ll look specifically at the task of extracting “product resistances” for rugs. Built-in tools for EDA (filtering, sorting, clustering, tagging, etc.)
In this blog post, we walk through an anonymized real-world use case comparing a variety of state-of-the-art LLMs (GPT 4, GPT 3.5, In this blog post, we’ll look specifically at the task of extracting “product resistances” for rugs. Built-in tools for EDA (filtering, sorting, clustering, tagging, etc.)
In this blog post, we walk through an anonymized real-world use case comparing a variety of state-of-the-art LLMs (GPT 4, GPT 3.5, In this blog post, we’ll look specifically at the task of extracting “product resistances” for rugs. Built-in tools for EDA (filtering, sorting, clustering, tagging, etc.)
This blog will explore “Factor Analysis vs Principal Component Analysis,” highlighting their key distinctions and helping you choose the right approach for your Data Analysis objectives. Read Blog: Statistical Tools for Data-Driven Research. What is Principal Component Analysis?
Then they use these patterns to understand the public’s behavior and predict the election results, thus making more informed political strategies based on population clusters. Now you need to perform some EDA and cleaning on the data after loading it into the notebook. We pay our contributors, and we don’t sell ads.
Solvers submitted a wide range of methodologies to this end, including using open-source and third party LLMs (GPT, LLaMA), clustering (DBSCAN, K-Means), dimensionality reduction (PCA), topic modeling (LDA, BERT), sentence transformers, semantic search, named entity recognition, and more. and DistilBERT.
Event-driven architecture (EDA) has become more crucial for organizations that want to strengthen their competitive advantage through real-time data processing and responsiveness. Register to attend today and come with questions to learn more on how event management is critical for your organization’s EDA strategy.
EDA, as it is popularly called, is the pivotal phase of the project where discoveries are made. Team collaboration Its team composition presents a great case wherein they have emphasized building robust data and model pipelines, such as the capacity expansion of prediction clusters, refining codebase, and retraining models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content