This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. IoT, Web 3.0,
We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. K-NearestNeighbors (KNN) is a supervised ML algorithm for classification and regression. I’m trying out a new thing: I draw illustrations of graphs, etc., Join thousands of data leaders on the AI newsletter.
This blog delves into the technical details of how vec t o r d a ta b a s e s empower patient sim i l a r i ty searches and pave the path for improved diagnosis. Exploring Disease Mechanisms : Vector databases facilitate the identification of patient clusters that share similar disease progression patterns.
The following image uses these embeddings to visualize how topics are clustered based on similarity and meaning. You can then say that if an article is clustered closely to one of these embeddings, it can be classified with the associated topic. This is the k-nearestneighbor (k-NN) algorithm.
This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples. k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset.
This blog explores types of classification tasks, popular algorithms, methods for evaluating performance, real-world applications, and why classifiers are indispensable in Machine Learning. K-NearestNeighbors (KNN) KNN assigns class labels based on the majority vote of nearestneighbors in the dataset.
The implementation included a provisioned three-node sharded OpenSearch Service cluster. Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. Each provisioned node was r7g.4xlarge, FloTorch used HSNW indexing in OpenSearch Service.
If you haven’t set up a SageMaker Studio domain, see this Amazon SageMaker blog post for instructions on setting up SageMaker Studio for individual users. To search against the database, you can use a vector search, which is performed using the k-nearestneighbors (k-NN) algorithm.
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service. For data handling, 24 data nodes (r6gd.2xlarge.search
Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. There are different kinds of unsupervised learning algorithms, including clustering, anomaly detection, neural networks, etc. K-Means Clustering: K-means is a popular and widely used clustering algorithm.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
This can be especially useful when recommending blogs, news articles, and other text-based content. K-NearestNeighborK-nearestneighbor (KNN) ( Figure 8 ) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g.,
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
In this short blog, were diving deep into vector databases what they are, how they work, and, most importantly, how to use them like a pro. But heres the catch scanning millions of vectors one by one (a brute-force k-NearestNeighbors or KNN search) is painfully slow. Traditional databases? They tap out. 💡 Why?
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
OpenSearch Service currently has tens of thousands of active customers with hundreds of thousands of clusters under management processing trillions of requests per month. The IMDb-Knowledge-Graph-Blog/part3-out-of-catalog/run_imdb_demo.py versions), as well as visualization capabilities powered by OpenSearch Dashboards and Kibana (1.5
out" embeddings.append(json.load(open(embedding_file))[0]) Create an ML-powered unified search engine This section discusses how to create a search engine that that uses k-NN search with embeddings. This includes configuring an OpenSearch Service cluster, ingesting item embedding, and performing free text and image search queries.
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
Hey guys, we will see some of the Best and Unique Machine Learning Projects for final year engineering students in today’s blog. This is going to be a very interesting blog, so without any further due, let’s do it… 1. Self-Organizing Maps In this blog, we will see how we can implement self-organizing maps in Python.
Hey guys, we will see some of the Best and Unique Machine Learning Projects with Source Codes in today’s blog. Youtube Comments Extraction and Sentiment Analysis Flask App Hey, guys in this blog we will implement Youtube Comments Extraction and Sentiment Analysis in Python using Flask. This is going to be a very short blog.
The following blog will provide you a thorough evaluation on how Anomaly Detection Machine Learning works, emphasising on its types and techniques. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm.
We design a K-NearestNeighbors (KNN) classifier to automatically identify these plays and send them for expert review. As an example, in the following figure, we separate Cover 3 Zone (green cluster on the left) and Cover 1 Man (blue cluster in the middle).
In today’s blog, we will see some very interesting Python Machine Learning projects with source code. Doctor-Patient Appointment System in Python using Flask Hey guys, in this blog we will see a Doctor-Patient Appointment System for Hospitals built in Python using Flask. I myself made this as my final year major project.
Spotify also establishes a taste profile by grouping the music users often listen into clusters. These clusters are not based on explicit attributes (e.g., Check out the complete blog series and dive deeper into recommendation systems with lessons that explore various recommendation engines (e.g., genre, artist, etc.)
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. Clustering and dimensionality reduction are common tasks in unSupervised Learning. customer segmentation), clustering algorithms like K-means or hierarchical clustering might be appropriate.
A set of classes sometimes forms a group/cluster. So, we can plot the high-dimensional vector space into lower dimensions and evaluate the integrity at the cluster level. index.add(xb) # xq are query vectors, for which we need to search in xb to find the knearestneighbors. # Creating the index.
This blog aims to clarify the concept of inductive bias and its impact on model generalisation, helping practitioners make better decisions for their Machine Learning solutions. k-NearestNeighbors (k-NN) The k-NN algorithm assumes that similar data points are close to each other in feature space.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. The K-NearestNeighbor Algorithm is a good example of an algorithm with low bias and high variance.
Lee, Chris De Sa, Karthik Sridharan On the Global Convergence Rates of Decentralized Softmax Gradient Play in Markov Potential Games Runyu Zhang, Jincheng Mei , Bo Dai , Dale Schuurmans , Na Li Matryoshka Representation Learning Aditya Kusupati , Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha , Vivek Ramanujan, William Howard-Snyder, (..)
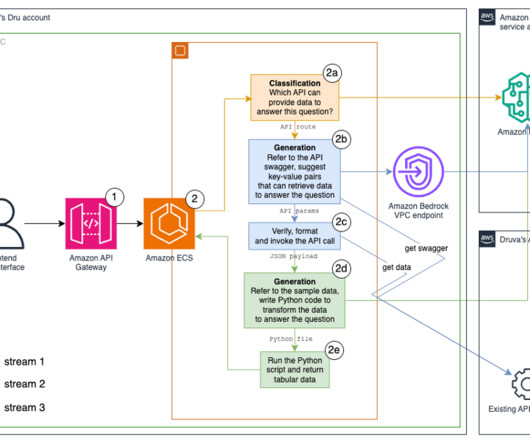
We tried different methods, including k-nearestneighbor (k-NN) search of vector embeddings, BM25 with synonyms , and a hybrid of both across fields including API routes, descriptions, and hypothetical questions. The request arrives at the microservice on our existing Amazon Elastic Container Service (Amazon ECS) cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content