This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With a goal to help data science teams learn about the application of AI and ML, DataRobot shares helpful, educational blogs based on work with the world’s most strategic companies. Explore these 10 popular blogs that help data scientists drive better data decisions. Read the blog. Read the blog. Read the blog.
At the time, I knew little about AI or machine learning (ML). But AWS DeepRacer instantly captured my interest with its promise that even inexperienced developers could get involved in AI and ML. Panic set in as we realized we would be competing on stage in front of thousands of people while knowing little about ML.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. We use the purpose-built geospatial container with SageMaker Processing jobs for a simplified, managed experience to create and run a cluster.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. For this post we’ll use a provisioned Amazon Redshift cluster.
Let’s discuss two popular ML algorithms, KNNs and K-Means. We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. They are both ML Algorithms, and we’ll explore them more in detail in a bit. They are both ML Algorithms, and we’ll explore them more in detail in a bit.
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
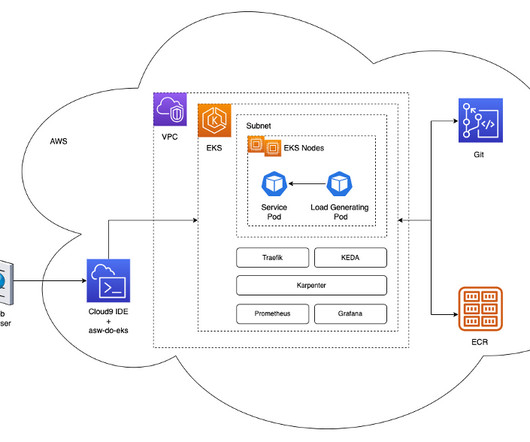
Solution overview The steps to implement the solution are as follows: Create the EKS cluster. Create the EKS cluster If you don’t have an existing EKS cluster, you can create one using eksctl. Adjust the following configuration to suit your needs, such as the Amazon EKS version, cluster name, and AWS Region.
This blog delves into a detailed comparison between the two data management techniques. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process. A file records vectors that belong to each cluster.
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. # install.sh
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Recent developments in machine learning (ML) have led to increasingly large models, some of which require hundreds of billions of parameters. In such distributed environments, observability of both instances and ML chips becomes key to model performance fine-tuning and cost optimization.
AWS provides various services catered to time series data that are low code/no code, which both machine learning (ML) and non-ML practitioners can use for building ML solutions. We use the Time Series Clustering using TSFresh + KMeans notebook, which is available on our GitHub repo.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
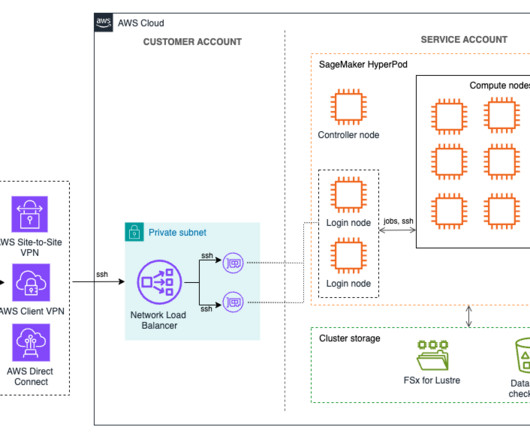
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
That world is not science fiction—it’s the reality of machine learning (ML). In this blog post, we’ll break down the end-to-end ML process in business, guiding you through each stage with examples and insights that make it easy to grasp. Formatting the data in a way that ML algorithms can understand.
Posted by Vincent Cohen-Addad and Alessandro Epasto, Research Scientists, Google Research, Graph Mining team Clustering is a central problem in unsupervised machine learning (ML) with many applications across domains in both industry and academic research more broadly. When clustering is applied to personal data (e.g.,
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. Machine learning (ML) is the technology that automates tasks and provides insights. Machine learning (ML) is the technology that automates tasks and provides insights. It also has ML algorithms built into the platform.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
This solution simplifies the integration of advanced monitoring tools such as Prometheus and Grafana, enabling you to set up and manage your machine learning (ML) workflows with AWS AI Chips. By deploying the Neuron Monitor DaemonSet across EKS nodes, developers can collect and analyze performance metrics from ML workload pods.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. The training data, securely stored in Amazon Simple Storage Service (Amazon S3), is copied to the cluster.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
Their impact on ML tasks has made them a cornerstone of AI advancements. In this blog, we will focus on these embeddings in LLM and explore how they have evolved over time within the world of NLP, each transformation being a result of technological advancement and progress. It allows ML models to work with data but in a limited manner.
They use real-time data and machine learning (ML) to offer customized loans that fuel sustainable growth and solve the challenges of accessing capital. This approach combines the efficiency of machine learning with human judgment in the following way: The ML model processes and classifies transactions rapidly.
Machine learning (ML) research has proven that large language models (LLMs) trained with significantly large datasets result in better model quality. Distributed model training requires a cluster of worker nodes that can scale. The following figure shows how FSDP works for two data parallel processes.
Meta is currently operating many data centers with GPU training clusters across the world. Meta’s training infrastructure comprises dozens of AI clusters of varying sizes, with a plan to scale to 600,000 GPUs in the next year. In this blog we will discuss only one of these transformations. And what do we mean by maintaining?
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
Amazon SageMaker Feature Store provides an end-to-end solution to automate feature engineering for machine learning (ML). For many ML use cases, raw data like log files, sensor readings, or transaction records need to be transformed into meaningful features that are optimized for model training. SageMaker Studio set up.
The architecture deploys a simple service in a Kubernetes pod within an EKS cluster. Karpenter monitors for any pending pods that can’t run due to lack of sufficient resources in the cluster. If such pods are detected, Karpenter adds more nodes to the cluster to provide the necessary resources. A managed node group with two c5.xlarge
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
These experiences are made possible by our machine learning (ML) backend engine, with ML models built for video understanding, search, recommendation, advertising, and novel visual effects. By using sophisticated ML algorithms, the platform efficiently scans billions of videos each day.
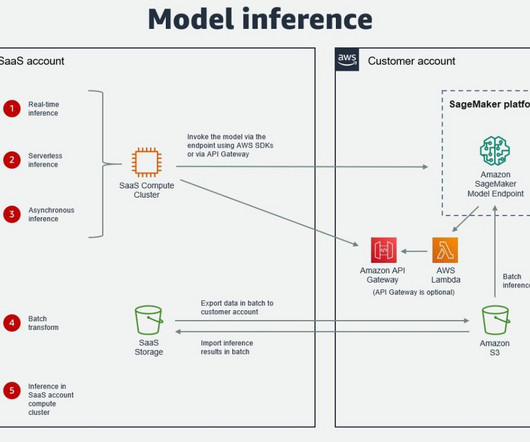
Many organizations choose SageMaker as their ML platform because it provides a common set of tools for developers and data scientists. There are a few different ways in which authentication across AWS accounts can be achieved when data in the SaaS platform is accessed from SageMaker and when the ML model is invoked from the SaaS platform.
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
This blog was originally written by Travis Hegner and updated for 2024 by Vinicius Olivera. Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. Sign up today for unbiased AI/ML advice!
This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples. K-Means Clustering K-means clustering partitions data into k distinct clusters based on feature similarity. Which ML Algorithm Is Best for Prediction?
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. kubectl for working with Kubernetes clusters.
Amazon SageMaker HyperPod is designed to support large-scale machine learning (ML) operations, providing a robust environment for training foundation models (FMs) over extended periods. This blog post specifically applies to HyperPod clusters using Slurm as the orchestrator.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Data Storage and Processing: All compute is done as Spark jobs inside of a Hadoop cluster using Apache Livy and Spark. Apache HBase was employed to offer real-time key-based access to data.
Scikit-learn can be used for a variety of data analysis tasks, including: Classification Regression Clustering Dimensionality reduction Feature selection Leveraging Scikit-learn in data analysis projects Scikit-learn can be used in a variety of data analysis projects. It is a cloud-based platform, so it can be accessed from anywhere.
SageMaker geospatial capabilities make it straightforward for data scientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Now, with the specialized geospatial container in SageMaker, managing and running clusters for geospatial processing has become more straightforward.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

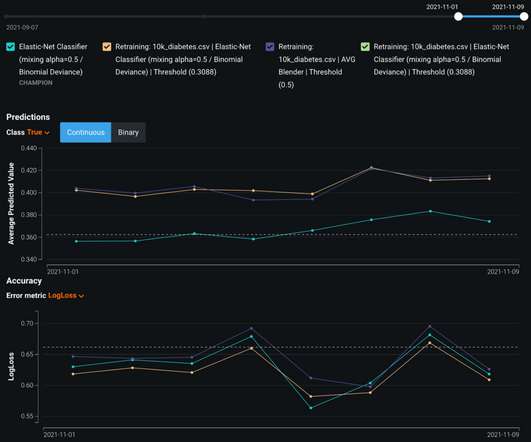








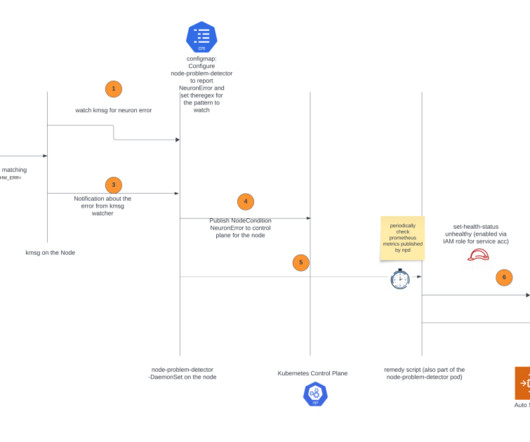

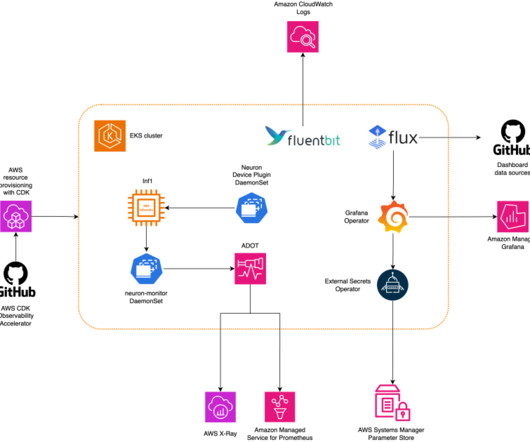





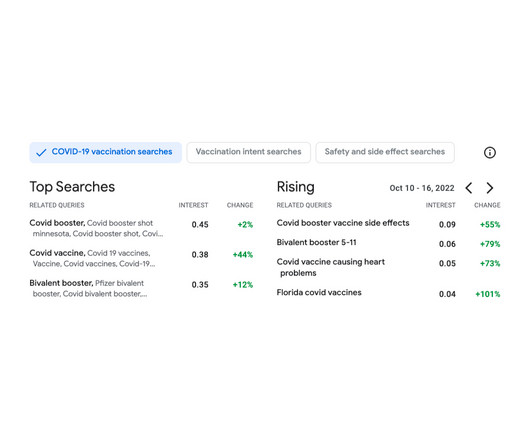



























Let's personalize your content