This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This blog delves into a detailed comparison between the two data management techniques. Hence, this blog will explore the debate from a few particular aspects, highlighting the characteristics of both traditional and vector databases in the process. A file records vectors that belong to each cluster.
Smart Subgroups For a user-specified patient population, the Smart Subgroups feature identifies clusters of patients with similar characteristics (for example, similar prevalence profiles of diagnoses, procedures, and therapies). The cluster feature summaries are stored in Amazon S3 and displayed as a heat map to the user.
The data is obtained from the Internet via APIs and web scraping, and the job titles and the skills listed in them are identified and extracted from them using NaturalLanguageProcessing (NLP) or more specific from Named-Entity Recognition (NER).
Well, it’s NaturalLanguageProcessing which equips the machines to work like a human. But there is much more to NLP, and in this blog, we are going to dig deeper into the key aspects of NLP, the benefits of NLP and NaturalLanguageProcessing examples. What is NLP?
In this blog post, we’ll explore five project ideas that can help you build expertise in computer vision, naturallanguageprocessing (NLP), sales forecasting, cancer detection, and predictive maintenance using Python.
To achieve this, Lumi developed a classification model based on BERT (Bidirectional Encoder Representations from Transformers) , a state-of-the-art naturallanguageprocessing (NLP) technique. They used JMeter to call the Asynchronous Inference endpoint to simulate real production load on the cluster.
In this blog post, we will show you how to use both of these services together to efficiently perform analysis on massive data sets in the cloud while addressing the challenges mentioned above. In the blog today, we will be executing the following steps: Cloning the sample repository with the required packages. Solution overview.
In this blog, we will take a deep dive into LLMs, including their building blocks, such as embeddings, transformers, and attention. To test your knowledge, we have included a crossword or quiz at the end of the blog. Transformers are a type of neural network that are well-suited for naturallanguageprocessing tasks.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
This blog delves into the technical details of how vec t o r d a ta b a s e s empower patient sim i l a r i ty searches and pave the path for improved diagnosis. Exploring Disease Mechanisms : Vector databases facilitate the identification of patient clusters that share similar disease progression patterns.
It is an AI framework and a type of naturallanguageprocessing (NLP) model that enables the retrieval of information from an external knowledge base. Facebook AI similarity search (FAISS) FAISS is used for similarity search and clustering dense vectors. Content creation It primarily deals with writing articles and blogs.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. It can also be used for determining the optimal number of clusters.
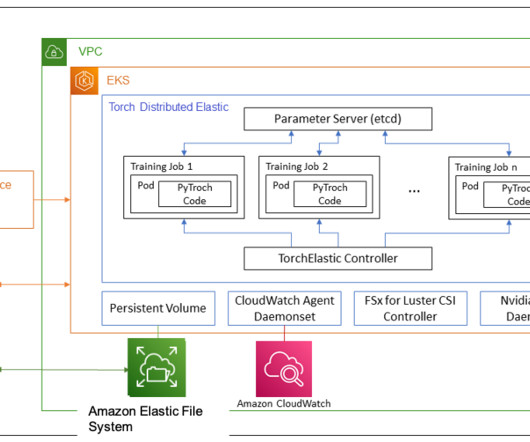
Distributed model training requires a cluster of worker nodes that can scale. Amazon Elastic Kubernetes Service (Amazon EKS) is a popular Kubernetes-conformant service that greatly simplifies the process of running AI/ML workloads, making it more manageable and less time-consuming.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It also contains supporting code for evaluation and parameter tuning. Once this process is done the first 5 rows of the file are displayed for preview.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. Their impact on ML tasks has made them a cornerstone of AI advancements.
It is used for machine learning, naturallanguageprocessing, and computer vision tasks. Wrapping up In this blog post, we have reviewed the top 6 AI tools for data analysis. TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs.
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
In our test environment, we observed 20% throughput improvement and 30% latency reduction across multiple naturallanguageprocessing models. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
However, building large distributed training clusters is a complex and time-intensive process that requires in-depth expertise. Clusters are provisioned with the instance type and count of your choice and can be retained across workloads. As a result of this flexibility, you can adapt to various scenarios.
Cost optimization – The serverless nature of the integration means you only pay for the compute resources you use, rather than having to provision and maintain a persistent cluster. This same interface is also used for provisioning EMR clusters. The following diagram illustrates this solution.
Embeddings play a key role in naturallanguageprocessing (NLP) and machine learning (ML). Text embedding refers to the process of transforming text into numerical representations that reside in a high-dimensional vector space. For example, let’s say you had a collection of customer emails or online product reviews.
Using RStudio on SageMaker and Amazon EMR together, you can continue to use the RStudio IDE for analysis and development, while using Amazon EMR managed clusters for larger data processing. In this post, we demonstrate how you can connect your RStudio on SageMaker domain with an EMR cluster. Choose Create stack.
For training, we chose to use a cluster of trn1.32xlarge instances to take advantage of Trainium chips. We used a cluster of 32 instances in order to efficiently parallelize the training. We also used AWS ParallelCluster to manage cluster orchestration. Tengfei Xue is an Applied Scientist at NinjaTech AI.
When storing a vector index for your knowledge base in an Aurora database cluster, make sure that the table for your index contains a column for each metadata property in your metadata files before starting data ingestion. These enhancements alleviate the need for creating multiple knowledge bases or redundant data copies.
Embeddings capture the information content in bodies of text, allowing naturallanguageprocessing (NLP) models to work with language in a numeric form. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
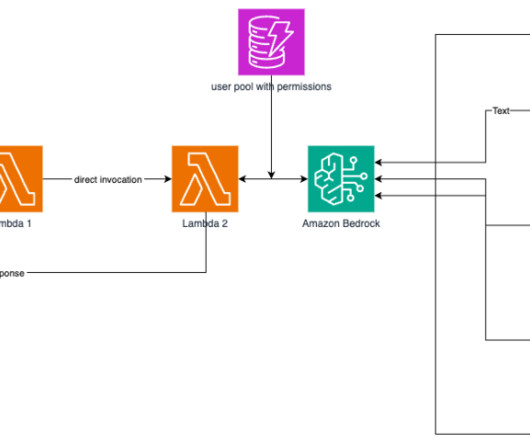
By integrating LLMs, the WxAI team enables advanced capabilities such as intelligent virtual assistants, naturallanguageprocessing (NLP), and sentiment analysis, allowing Webex Contact Center to provide more personalized and efficient customer support. The following diagram illustrates the WxAI architecture on AWS.
Nodes run the pods and are usually grouped in a Kubernetes cluster, abstracting the underlying physical hardware resources. Kubernetes’s declarative, API -driven infrastructure has helped free up DevOps and other teams from manually driven processes so they can work more independently and efficiently to achieve their goals.
A blog by Lewis and three of the paper’s coauthors said developers can implement the process with as few as five lines of code. A recent blog provides an example of RAG accelerated by TensorRT-LLM for Windows to get better results fast. What’s more, the technique can help models clear up ambiguity in a user query.
Facebook AI Similarity Search (Faiss) is a library for efficient similarity search and clustering of dense vectors. It also contains supporting code for evaluation and parameter tuning. Once this process is done the first 5 rows of the file are displayed for preview.
Sonnet model for naturallanguageprocessing. Additionally, we plan to analyze the saved queries using Amazon Titan Text Embeddings and agglomerative clustering to identify semantically similar questions. Amazon Bedrock integration Our Untold Assistant uses Amazon Bedrock with Anthropics Claude 3.5
His research interests are in the area of naturallanguageprocessing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering. Xin Huang is a Senior Applied Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms.
books, magazines, newspapers, forms, street signs, restaurant menus) so that they can be indexed, searched, translated, and further processed by state-of-the-art naturallanguageprocessing techniques. Middle: Illustration of line clustering. Right: Illustration paragraph clustering.
The MoE architecture allows activation of 37 billion parameters, enabling efficient inference by routing queries to the most relevant expert clusters. Conclusion Deploying DeepSeek models on SageMaker AI provides a robust solution for organizations seeking to use state-of-the-art language models in their applications.
Large language models (LLMs) are a class of foundational models (FM) that consist of layers of neural networks that have been trained on these massive amounts of unlabeled data. Large language models (LLMs) have taken the field of AI by storm.
In our solution, we implement a hyperparameter grid search on an EKS cluster for tuning a bert-base-cased model for classifying positive or negative sentiment for stock market data headlines. A desired cluster can simply be configured using the eks.conf file and launched by running the eks-create.sh to launch the cluster.
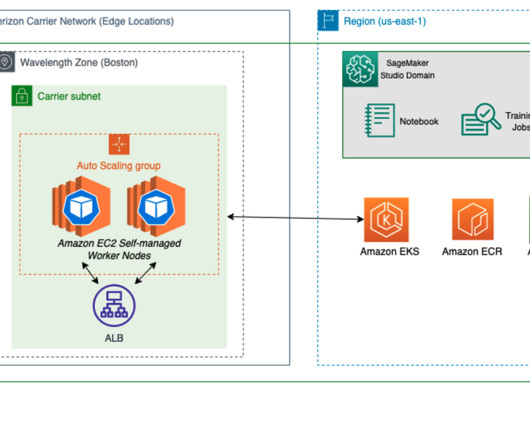
Retailers can deliver more frictionless experiences on the go with naturallanguageprocessing (NLP), real-time recommendation systems, and fraud detection. To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. sourcedir.tar.gz
In this blog, we’ll explore seven key strategies to optimize infrastructure for AI workloads, empowering organizations to harness the full potential of AI technologies. Learn more about IBM IT Infrastructure Solutions The post Unleashing the potential: 7 ways to optimize Infrastructure for AI workloads appeared first on IBM Blog.
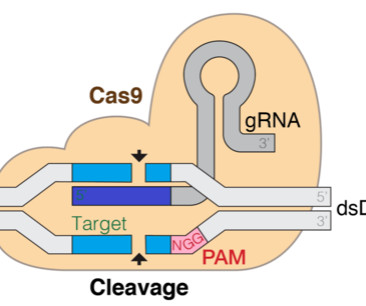
The clustered regularly interspaced short palindromic repeat (CRISPR) technology holds the promise to revolutionize gene editing technologies, which is transformative to the way we understand and treat diseases. He is broadly interested in naturallanguageprocessing and has contributed to AWS products such as Amazon Comprehend.
These factors require training an LLM over large clusters of accelerated machine learning (ML) instances. Within one launch command, Amazon SageMaker launches a fully functional, ephemeral compute cluster running the task of your choice, and with enhanced ML features such as metastore, managed I/O, and distribution.
The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. This produces a vector representation for each sentence that captures its meaning and context.
This characteristic is clearly observed in models in naturallanguageprocessing (NLP) and computer vision (CV) like in the graphs below. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them. And that would lead to a more secure future, I guess.
This blog discusses key Linear Algebra concepts, their practical applications in data preprocessing and model training, and real-world examples that illustrate how these mathematical principles drive advancements in various Machine Learning tasks. Example In NaturalLanguageProcessing (NLP), word embeddings are often represented as vectors.
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
However, when employing the use of traditional naturallanguageprocessing (NLP) models, they found that these solutions struggled to fully understand the nuanced feedback found in open-ended survey responses. About the authors Kinman Lam is an ISV/DNB Solution Architect for AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content