This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. This is called clustering. In Data Science, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset.
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. IoT, Web 3.0,
These intelligent predictions are powered by various Machine Learning algorithms. This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples. Key Takeaways Machine Learning enables systems to learn from data without explicit programming.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. What is Classification? Hence, the assumption causes a problem.
This blog explores types of classification tasks, popular algorithms, methods for evaluating performance, real-world applications, and why classifiers are indispensable in Machine Learning. SupportVectorMachines (SVM) SVM finds the optimal hyperplane that separates classes with maximum margin.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM).
In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. For beginners, it can seem daunting to dive into the world of data mining, but by following the tips outlined in this blog post, they can start their journey on the right foot.
Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. K-means clustering is commonly used for market segmentation, document clustering, image segmentation and image compression.
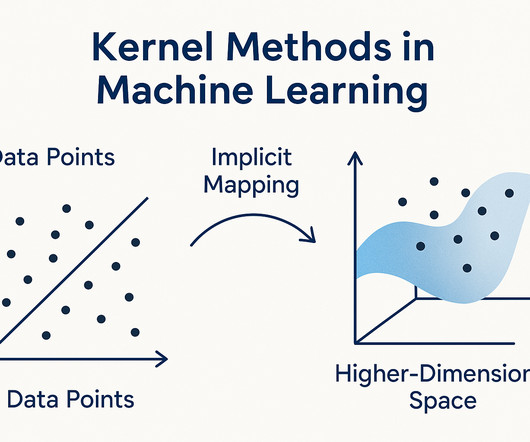
This is where kernel methods in machine learning come in like superheroes. Think of them as magic glasses that help machines see patterns better. In this blog, Ill walk you through these methods, how they work, and why they matterall in simple words. Frequently Asked Questions What are kernel methods in machine learning?
We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker. A cluster of pings represents popular spots where devices gathered or stopped, such as stores or restaurants. Manually managing a DIY compute cluster is slow and expensive.
Machine learning(ML) is evolving at a very fast pace. I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning?
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of data model for Machine Learning, exploring their types. What is Machine Learning?
SVM-based classifier: Amazon Titan Embeddings In this scenario, it is likely that user interactions belonging to the three main categories ( Conversation , Services , and Document_Translation ) form distinct clusters or groups within the embedding space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
Summary: Linear Algebra is foundational to Machine Learning, providing essential operations such as vector and matrix manipulations. By understanding Linear Algebra operations, practitioners can better grasp how Machine Learning models work, optimize their performance, and implement various algorithms effectively.
It helps in discovering hidden patterns and organizing text data into meaningful clusters. Machine Learning algorithms, including Naive Bayes, SupportVectorMachines (SVM), and deep learning models, are commonly used for text classification. within the text.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
The following blog will provide you a thorough evaluation on how Anomaly Detection Machine Learning works, emphasising on its types and techniques. Further, it will provide a step-by-step guide on anomaly detection Machine Learning python. Anomalies, being different from normal data, result in higher reconstruction errors.
Are there clusters of customers with different spending patterns? #3. Model Training We train multiple machine learning models, including Logistic Regression, Random Forest, Gradient Boosting, and SupportVectorMachine. SupportVectorMachine (svm): Versatile model for linear and non-linear data.
Machine learning for text extraction with Python is one of the best combos out there for this task. In this blog post, we’ll talk about how one can use Machine learning and Python to perform text extraction with the highest level of accuracy. Pandas – This works best for model evaluation and machine learning algorithms.
This blog aims to explain what Statistical Modeling is, highlight its key components, and explore its applications across various sectors. These models do not rely on predefined labels; instead, they discover the inherent structure in the data by identifying clusters based on similarities. What is Statistical Modeling?
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
Audio recordings can be transformed into vectors using image embedding transformations over the audio frequencies visual representation (e.g., Meet AI's multitool: Vector embeddings | Google Cloud Blog Embedding applications Recommendation systems (i.e. Clustering — we can cluster our sentences, useful for topic modeling.
Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you. Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. It includes regression, classification, clustering, decision trees, and more.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. The global Machine Learning market was valued at USD 35.80
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. It covers types of Machine Learning, key concepts, and essential steps for building effective models. Clustering and dimensionality reduction are common tasks in unSupervised Learning.
Machine Learning Tools in Bioinformatics Machine learning is vital in bioinformatics, providing data scientists and machine learning engineers with powerful tools to extract knowledge from biological data. Clustering algorithms can group similar biological samples or identify distinct subtypes within a disease.
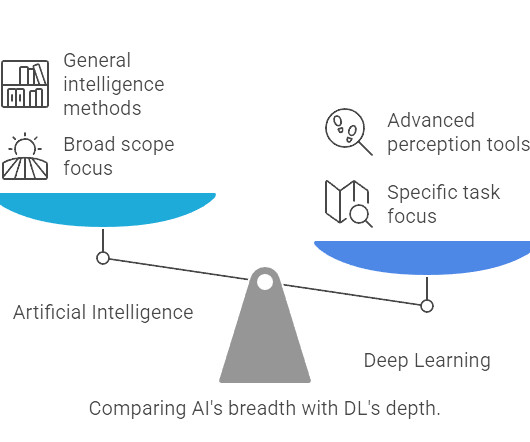
This blog post aims to demystify these powerful concepts. We’ll break down Artificial Intelligence as the overarching goal, introduce its key subset Machine Learning , and then dive deep into Deep Learning , explaining its unique capabilities and how it relates to the others. Is Deep Learning just another name for AI?
Introduction In todays world of AI, both Machine Learning (ML) and Deep Learning (DL) are transforming industries, yet many confuse the two. This blog explores the difference between Machine Learning and Deep Learning , highlighting their unique characteristics, benefits, and challenges.
The global Machine Learning market is rapidly growing, projected to reach US$79.29bn in 2024 and grow at a CAGR of 36.08% from 2024 to 2030. This blog aims to clarify the concept of inductive bias and its impact on model generalisation, helping practitioners make better decisions for their Machine Learning solutions.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and Data Science, highlighting their complementary roles in Data Analysis and intelligent decision-making. Machine Learning Supervised Learning includes algorithms like linear regression, decision trees, and supportvectormachines.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. Another example can be the algorithm of a supportvectormachine. These are called supportvectors.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content