This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
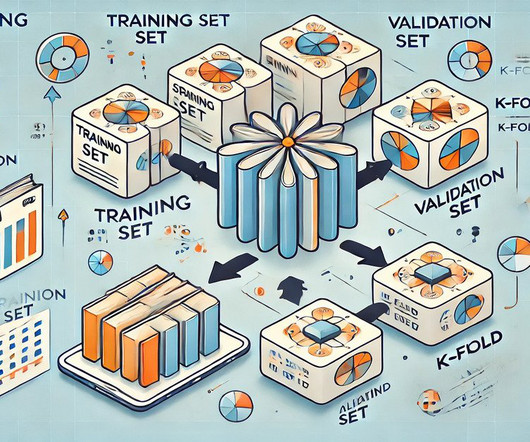
Summary: Cross-validation in Machine Learning is vital for evaluating model performance and ensuring generalisation to unseen data. Introduction In this article, we will explore the concept of cross-validation in Machine Learning, a crucial technique for assessing model performance and generalisation.
Achieving Peak Performance: Mastering Control and Generalization Source: Image created by Jan Marcel Kezmann Today, we’re going to explore a crucial decision that researchers and practitioners face when training machine and deeplearning models: Should we stick to a fixed custom dataset or embrace the power of cross-validation techniques?
Deeplearning is a branch of machine learning that makes use of neural networks with numerous layers to discover intricate data patterns. Deeplearning models use artificial neural networks to learn from data. It is a tremendous tool with the ability to completely alter numerous sectors.
Model architectures : All four winners created ensembles of deeplearning models and relied on some combination of UNet, ConvNext, and SWIN architectures. In the modeling phase, XGBoost predictions serve as features for subsequent deeplearning models. Test-time augmentations were used with mixed results.
I am involved in an educational program where I teach machine and deeplearning courses. Machine learning is my passion and I often take part in competitions. Training data was splited into 5 folds for crossvalidation. We implement machine learning and deeplearning methods in our research projects.
Additionally, I will use StratifiedKFold cross-validation to perform multiple train-test splits. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners.
Applying XGBoost on a Problem Statement Applying XGBoost to Our Dataset Summary Citation Information Scaling Kaggle Competitions Using XGBoost: Part 4 Over the last few blog posts of this series, we have been steadily building up toward our grand finish: deciphering the mystery behind eXtreme Gradient Boosting (XGBoost) itself.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. SageMaker notably supports popular deeplearning frameworks, including PyTorch, which is integral to the solutions provided here.
Feature engineering vs. neural network feature learning : The top performing solutions included deeplearning models that used image or sequence representations of the data as inputs and feature engineering to capture the mass spectrograms. All winners who used deeplearning fine-tuned pre-trained models.
Several additional approaches were attempted but deprioritized or entirely eliminated from the final workflow due to lack of positive impact on the validation MAE. Her primary interests lie in theoretical machine learning. She currently does research involving interpretability methods for biological deeplearning models.
To determine the best parameter values, we conducted a grid search with 10-fold cross-validation, using the F1 multi-class score as the evaluation metric. For the classifier, we employ SVM, using the scikit-learn Python module. The SVM algorithm requires the tuning of several parameters to achieve optimal performance.
Cross-validation is recommended as best practice to provide reliable results because of this. If you want to read some of my other blogs, you can read them below: KNN: A Complete Guide Naive Bayes: A Complete Guide Linear Regression: A Complete Guide I advise you to give it a shot. In this instance, we observe a 13.3%
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. The global Machine Learning market was valued at USD 35.80
With the global Machine Learning market projected to grow from USD 26.03 This blog explores their types, tuning techniques, and tools to empower your Machine Learning models. Neural Networks In DeepLearning, key model-related hyperparameters include the number of layers, neurons in each layer, and the activation functions.
Measuring Calibration in DeepLearning. CrossValidated] Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners. 10] Nixon, Jeremy, et al. CVPR workshops.
Summary: This blog covers 15 crucial artificial intelligence interview questions, ranging from fundamental concepts to advanced techniques. In this blog post, we will explore 15 essential artificial intelligence interview questions that cover a range of topics, from fundamental principles to cutting-edge techniques.
Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Overall , Machine learning’s main objective is to find a tradeoff between the model’s ability to fit the training data and its ability to generalize to new data. In this blog we will talk a bit about the bias-variance tradeoff and drop on double descent phenomenon. This is the so-called bias-variance tradeoff.
Hey guys, in this blog we will see some of the most asked Data Science Interview Questions by interviewers in [year]. Read the full blog here — [link] Data Science Interview Questions for Freshers 1. What is deeplearning? What is the difference between deeplearning and machine learning?
In this blog, we’ll explore various cheat sheets that cover a wide range of Data Science topics, making them a must-have resource for both beginners and experienced professionals.
Significantly, despite being user-friendly and easy to learn, one of Python’s many advantages is that it has large collection of libraries. To help you understand Python Libraries better, the blog will explain a Python Libraries for Data Science List which you can learn about. What is a Python Library?
With the advent of DeepLearning, recommender systems have seen significant advancements. Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for data science, machine learning, and deeplearning practitioners.
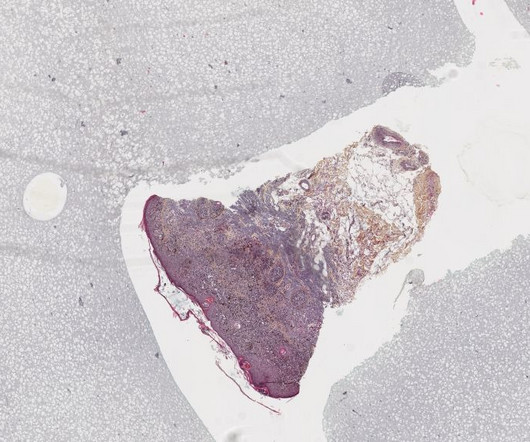
Image and Signal Processing: In medical imaging and signal processing, data scientists and machine learning engineers employ advanced algorithms to extract valuable information from images, such as CT scans, MRIs, and EKGs. We're committed to supporting and inspiring developers and engineers from all walks of life.
A key aspect of building effective Machine Learning models is feature extraction in Machine Learning. This blog will explore the importance of feature extraction, its techniques, and its impact on model efficiency and accuracy. Key Takeaways Feature extraction transforms raw data into usable formats for Machine Learning models.
For example, the model produced a RMSLE (Root Mean Squared Logarithmic Error) CrossValidation of 0.0825 and a MAPE (Mean Absolute Percentage Error) CrossValidation of 6.215. This would entail a roughly +/-€24,520 price difference on average, compared to the true price, using MAE (Mean Absolute Error) CrossValidation.
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. It covers types of Machine Learning, key concepts, and essential steps for building effective models. Finding the best combination of these parameters can significantly enhance model performance.
Hyperparameters are the configuration variables of a machine learning algorithm that are set prior to training, such as learning rate, number of hidden layers, number of neurons per layer, regularization parameter, and batch size, among others. We’re committed to supporting and inspiring developers and engineers from all walks of life.
This blog will explore the intricacies of AI Time Series Forecasting, its challenges, popular models, implementation steps, applications, tools, and future trends. Split the Data: Divide your dataset into training, validation, and testing subsets to ensure robust evaluation. billion in 2024 and is projected to reach a mark of USD 1339.1
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. DeepLearning An introduction to deeplearning concepts and frameworks like TensorFlow and PyTorch, focusing on their applications in processing large datasets.
In this blog post, I’ll share my own experiences and the hard-won insights I’ve gained from designing, building, and deploying cutting-edge CV models across various platforms like cloud, on-premise, and edge devices. neptune.ai’s case studies : knowledge base of practical use cases.
Quantitative evaluation We utilize 2018–2020 season data for model training and validation, and 2021 season data for model evaluation. We perform a five-fold cross-validation to select the best model during training, and perform hyperparameter optimization to select the best settings on multiple model architecture and training parameters.
This blog explores XGBoosts unique characteristics, practical applications, and how it revolutionises Machine Learning workflows. Monitor Overfitting : Use techniques like early stopping and cross-validation to avoid overfitting. Key Takeaways It handles large datasets with multi-threading and distributed computing.
A Machine Learning Engineer plays a crucial role in this landscape, designing and implementing algorithms that drive innovation and efficiency. offer specialised Machine Learning and Artificial Intelligence courses covering DeepLearning , Natural Language Processing, and Reinforcement Learning.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques.
My topic is the multimodal analysis of cancer patients' data and more specifically of glioblastoma data using deeplearning. Ziad Kheil: Currently a PhD student at the CRCT, I work on deeplearning based medical image registration with a focus on thoracic images. What motivated you to compete in this challenge?
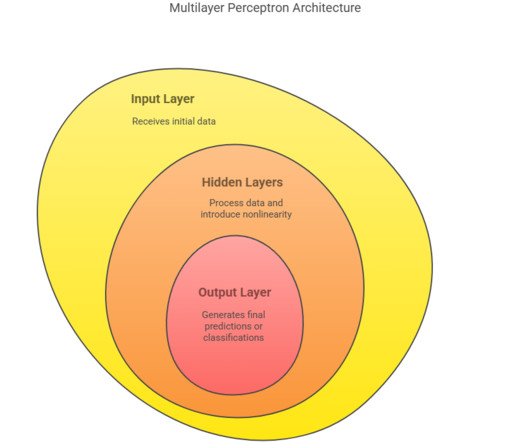
Summary: Multilayer Perceptron in machine learning (MLP) is a powerful neural network model used for solving complex problems through multiple layers of neurons and nonlinear activation functions. The optimal architecture often requires experimentation and cross-validation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content