This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The October blogs that won KDnuggets Rewards include: How I Tripled My Income With Data Science in 18 Months; What Google Recommends You do Before Taking Their Machine Learning or Data Science Course; How to Build Strong Data Science Portfolio as a Beginner; Data Scientist vs DataEngineer Salary.
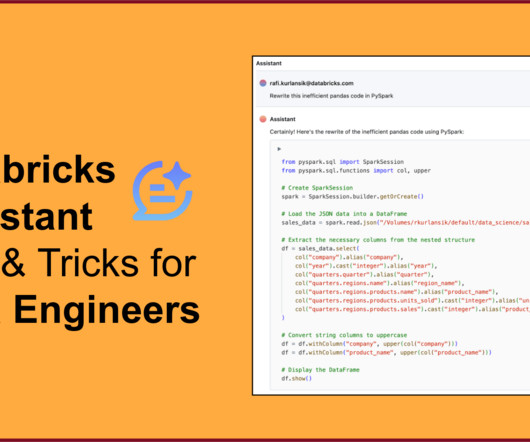
The generative AI revolution is transforming the way that teams work, and Databricks Assistant leverages the best of these advancements. It allows you.
Today, we are excited to announce Databricks LakeFlow, a new solution that contains everything you need to build and operate production data pipelines.
The October blogs that won KDnuggets Rewards include: How I Tripled My Income With Data Science in 18 Months; What Google Recommends You do Before Taking Their Machine Learning or Data Science Course; How to Build Strong Data Science Portfolio as a Beginner; Data Scientist vs DataEngineer Salary.
Within the Databricks Community, there is a technical blog where community members share best practices, tutorials and insights on data analytics, dataengineering.
Within the Databricks Community, there is a technical blog where community members share best practices, tutorials and insights on data analytics, dataengineering.
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
In this four-part blog series "Lessons learned from building Cybersecurity Lakehouses," we are discussing a number of challenges organizations face with dataengineering.
In this four-part blog series "Lessons learned from building Cybersecurity Lakehouses," we will discuss a number of challenges organizations face with dataengineering.
In this four-part blog series “Lessons learned building Cybersecurity Lakehouses,” we are discussing a number of challenges organizations face with dataengineering when bui.
In this four-part blog series, "Lessons learned from building Cybersecurity Lakehouses," we are discussing a number of challenges organizations face with dataengineering.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary. appeared first on Analytics Vidhya.
As organizations leverage their proprietary data for models, many encounter the hard truth: The best GenAI models in the world will not succeed without good data.
We are proud to announce two new analyst reports recognizing Databricks in the dataengineering and data streaming space: IDC MarketScape: Worldwide Analytic.
Even if their data systems are not technically flawed, they are still unable to solve business problems and drive profitable decisions. Companies in the initial […] The post The Urgent Risks of Bad DataEngineering appeared first on Aryng's Blog.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
For DATANOMIQ this is a show-case of the coming Data as a Service ( DaaS ) Business. The post Monitoring of Jobskills with DataEngineering & AI appeared first on Data Science Blog. Over the time, it will provides you the answer on your questions related to which tool to learn!
By learning Python, you can effectively clean and manipulate data, create visualizations, and build machine-learning models. Familiarize yourself with essential data science libraries Once you have a good grasp of Python programming, start with essential data science libraries like NumPy, Pandas, and Matplotlib.
In today’s rapidly evolving data landscape, organizations must make sense of the overwhelming amounts of data generated daily. The roles of dataengineers and data scientists are central to this mission. They each require distinct skill sets that, when combined, can create a powerful synergy.
However, behind the glitz and glamor of these advancements, there is an underappreciated field: dataengineering. Data is the lifeblood that fuels today’s […] The post The Role of DataEngineering in AI and Machine Learning Projects appeared first on DATAVERSITY.
Dataengineering teams are frequently tasked with building bespoke ingestion solutions for myriad custom, proprietary, or industry-specific data sources. Many teams find that.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
A collaborative and interactive workspace allows users to perform big data processing and machine learning tasks easily. In this blog post, we will take a closer look at Azure Databricks, its key features, […] The post Azure Databricks: A Comprehensive Guide appeared first on Analytics Vidhya.
In this blog p. Apache Spark™ 3.5 and Databricks Runtime 14.0 have brought an exciting feature to the table: Python user-defined table functions (UDTFs).
This article was published as a part of the Data Science Blogathon. Introduction Ever wondered how to query and analyze raw data? This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. Also, have you ever tried doing this with Athena and QuickSight?
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. This is indeed a game-changer in the realm of data science.
This blog discusses vector databases, specifically pinecone vector databases. A vector database is a type of database that stores data as mathematical vectors, which represent features or attributes. These vectors have multiple dimensions, capturing complex data relationships.
Introduction In this blog post, we'll explore a set of advanced SQL functions available within Apache Spark that leverage the HyperLogLog algorithm, enabling.
Current professionals seeking to transition into the data-tech domain or data science professionals seeking to enhance their career growth and development can also benefit from these sessions. In this blog post, we […] The post Explore the World of Data-Tech with DataHour appeared first on Analytics Vidhya.
This blog provided you with a comprehensive overview of ETL and JupySQL, including a brief introduction to ETLs and JupySQL. We also demonstrated how to schedule an example ETL notebook via GitHub actions, which allows you to automate the process of executing ETLs and JupySQL from Jupyter.
This article was published as a part of the Data Science Blogathon. Introduction Earlier, I had introduced basic concepts of Apache Kafka in my blog on Analytics Vidhya(link is available under references).
Databricks recently announced the Data Intelligence Platform, a natural evolution of the lakehouse architecture we pioneered. The idea of a Data Intelligence Platform.
Anzeige Data Science und AI sind aufstrebende Arbeitsfelder, die sich mit der Gewinnung von Wissen aus Daten beschäftigen. Von einem Data Scientist wird ferner erwartet, die theoretischen Grundlagen sowie die praktische Anwendung von Machine Learning und Deep Learning als trainierte Fähigkeit abrufbar zu haben.
Let’s get started Photo by Kaleidico… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas.
There are so many different data- and machine-learning-related jobs. But what actually are the differences between a DataEngineer, Data Scientist, ML Engineer, Research Engineer, Research Scientist, or an Applied Scientist?! Dataengineering is the foundation of all ML pipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content