This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and dataengineering. They transform data into a consistent format for users to consume.
We are proud to announce two new analyst reports recognizing Databricks in the dataengineering and data streaming space: IDC MarketScape: Worldwide Analytic.
Introduction Databricks Lakehouse Monitoring allows you to monitor all your datapipelines – from data to features to ML models – without additional too.
Dataengineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Navigating the World of DataEngineering: A Beginner’s Guide. A GLIMPSE OF DATAENGINEERING ❤ IMAGE SOURCE: BY AUTHOR Data or data? No matter how you read or pronounce it, data always tells you a story directly or indirectly. Dataengineering can be interpreted as learning the moral of the story.
Dataengineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
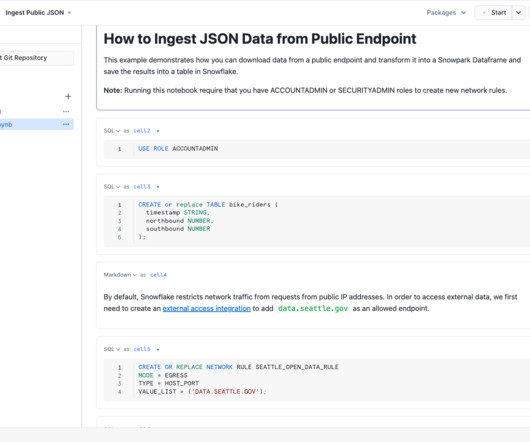
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
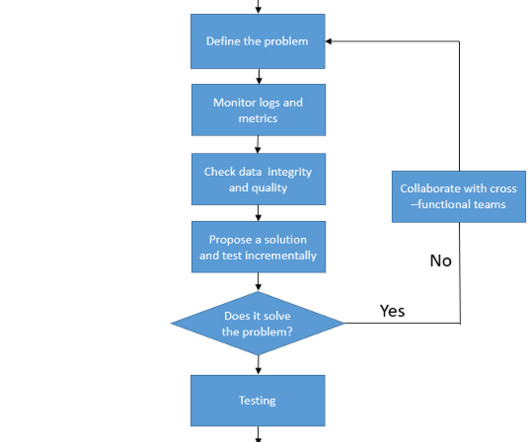
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse.
This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines. What is an ETL datapipeline in ML?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
About the Authors Emrah Kaya is DataEngineering Manager at Omron Europe and Platform Lead for ODAP Project. With his extensive background on Cloud & Data Architecture, Emrah leads key OMRONs technological advancement initiatives, including artificial intelligence, machine learning, or data science.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. It allows users to design datapipelines, such as extracting data from various sources, transforming that data, and loading it into data storage engines.
In this blog, we will explore the top 10 AI jobs and careers that are also the highest-paying opportunities for individuals in 2024. Chatbots and virtual assistants are some of the common applications developed by NLP engineers for modern businesses. Hence, they collect, clean, and organize data to prepare it for analysis.
But with automated lineage from MANTA, financial organizations have seen as much as a 40% increase in engineering teams’ productivity after adopting lineage. Increased datapipeline observability As discussed above, there are countless threats to your organization’s bottom line.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Airflow setup Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines. ", instance_type="ml.m5.xlarge",
Welcome to Beyond the Data, a series that investigates the people behind the talent of phData. In this blog, we’re featuring Eugenia Pais, a Sr. DataEngineer at phData. DataEngineer? As a Senior DataEngineer, I wear many hats. DataEngineer appeared first on phData.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible. Or maybe you are interested in an individual data strategy ? Then get in touch with me!
Additionally, imagine being a practitioner, such as a data scientist, dataengineer, or machine learning engineer, who will have the daunting task of learning how to use a multitude of different tools. It also handles metadata, monitoring, and governance related to data management. Spark, Flink, etc.)
This adaptability allows organizations to align their data integration efforts with distinct operational needs, enabling them to maximize the value of their data across diverse applications and workflows. With that, a strategy that empowers less technical users and accelerates time to value for specialized data teams is critical.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving.
In recent years, dataengineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently. What Are the Benefits of CI/CD Pipeline For Snowflake?
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Why Use Fivetran?
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
Historically, dataengineers have often prioritized building datapipelines over comprehensive monitoring and alerting. Delivering projects on time and within budget often took precedence over long-term data health. Until recently, there were few dedicated data observability tools available.
Rajesh Nedunuri is a Senior DataEngineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
That’s why many organizations invest in technology to improve data processes, such as a machine learning datapipeline. However, data needs to be easily accessible, usable, and secure to be useful — yet the opposite is too often the case. How can dataengineers address these challenges directly?
In prior blog posts challenges beyond the 3V’s and understanding data , I discussed some issues which hindered the efficiency of data analysts besides drastically raising the bar on their motivation to begin working with new data. Here, I want to drill into a few more experiences around use and management of data.
Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks. DataEngineer: A dataengineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models.
Read this e-book on building strong governance foundations Why automated data lineage is crucial for success Data lineage , the process of tracking the flow of data over time from origin to destination within a datapipeline, is essential to understand the full lifecycle of data and ensure regulatory compliance.
Data is presented to the personas that need access using a unified interface. For example, it can be used to answer questions such as “If patients have a propensity to have their wearables turned off and there is no clinical telemetry data available, can the likelihood that they are hospitalized still be accurately predicted?”
This new partnership will unify governed, quality data into a single view, granting all stakeholders total visibility into pipelines and providing them with a superior ability to make data-driven decisions. For people to understand and trust data, they need to see it in context. DataPipeline Strategy.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? DataEngineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
Advanced-DataEngineering and ML Ops with Infrastructure as Code This member-only story is on us. Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machine learning pipelines with AWS Step Functions and deploy them using Infrastructure as Code. Upgrade to access all of Medium.
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
Dataengineering is a fascinating and fulfilling career – you are at the helm of every business operation that requires data, and as long as users generate data, businesses will always need dataengineers. The journey to becoming a successful dataengineer […].
Data teams use Bigeye’s data observability platform to detect data quality issues and ensure reliable datapipelines. If there is an issue with the data or datapipeline, the data team is immediately alerted, enabling them to proactively address the issue. Subscribe to Alation's Blog.
This is where Fivetran and the Modern Data Stack come in. Fivetran is a fully-automated, zero-maintenance datapipeline tool that automates the ETL process from data sources to your cloud warehouse. Because of this, it was hard for them to leverage their data and make data-driven decisions. What is Fivetran?
The recent Snowflake Summit 2024 brought plenty of exciting upcoming features, GA announcements, strategic partnerships, and many more opportunities for customers on the Snowflake AI Data Cloud to innovate. If you are new to Snowflake Cortex AI, check out this introductory blog. schemas["my_schema"].tables.create(my_table)
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, dataengineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. For example, neptune.ai
This blog will cover creating customized nodes in Coalesce, what new advanced features can already be used as nodes, and how to create them as part of your datapipeline. Dynamic Tables Dynamic tables , a recent feature in Snowflake, are a game changer for dataengineering.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content