This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
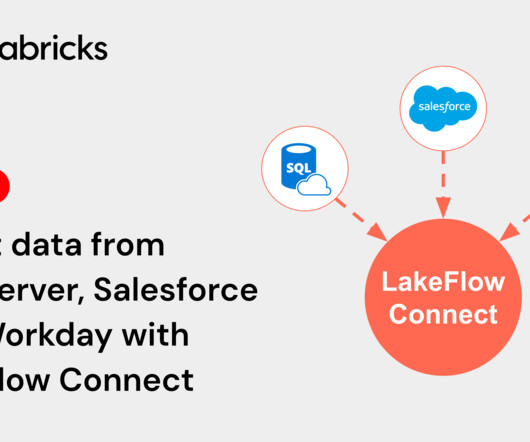
We’re excited to announce the Public Preview of LakeFlow Connect for SQL Server, Salesforce, and Workday. These ingestion connectors enable simple and efficient.
Introduction In this blog post, we'll explore a set of advanced SQL functions available within Apache Spark that leverage the HyperLogLog algorithm, enabling.
Dataengineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and dataengineers are responsible for designing and implementing the systems and infrastructure that make this possible.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. Data Lakes : It supports MS Azure Blob Storage. pipelines, Azure Data Bricks.
They allow data processing tasks to be distributed across multiple machines, enabling parallel processing and scalability. It involves various technologies and techniques that enable efficient data processing and retrieval. Stay tuned for an insightful exploration into the world of Big DataEngineering with Distributed Systems!
Introduction Applying Large Language Models (LLMs) for code generation is becoming increasingly prevalent, as it helps you code faster and smarter. A primary.
Anzeige Data Science und AI sind aufstrebende Arbeitsfelder, die sich mit der Gewinnung von Wissen aus Daten beschäftigen. SQL für Data Science ermöglicht, Daten effektiv zu organisieren und schnell Abfragen zu erstellen, um Antworten auf komplexe Fragen zu finden. Weitere Kurse von Coursera zum Thema Data & AI (link).
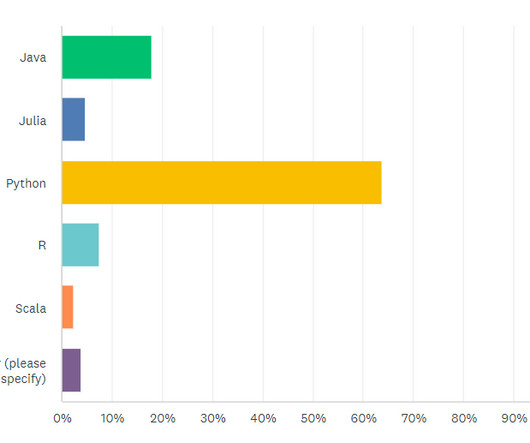
However, we collect these over time and will make trends secure, for example how the demand for Python, SQL or specific tools such as dbt or Power BI changes. For DATANOMIQ this is a show-case of the coming Data as a Service ( DaaS ) Business. The presentation is currently limited to the current situation on the labor market.
So why using IaC for Cloud Data Infrastructures? For Data Warehouse Systems that often require powerful (and expensive) computing resources, this level of control can translate into significant cost savings. The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQL Database.
Managing and retrieving the right information can be complex, especially for data analysts working with large data lakes and complex SQL queries. This tool converts questions from data analysts asked in natural language (such as “Which table contains customer address information?”)
This article was published as a part of the Data Science Blogathon. Introduction Ever wondered how to query and analyze raw data? This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. Also, have you ever tried doing this with Athena and QuickSight?
The data is stored in a data lake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. Data is normally stored in databases, and can be queried using the most common query language, SQL. The challenge is to assure quality.
Die Bedeutung effizienter und zuverlässiger Datenpipelines in den Bereichen Data Science und DataEngineering ist enorm. Automatisierung: Erstellt SQL-Code, DACPAC-Dateien, SSIS-Pakete, Data Factory-ARM-Vorlagen und XMLA-Dateien. Data Lakes: Unterstützt MS Azure Blob Storage.
Current professionals seeking to transition into the data-tech domain or data science professionals seeking to enhance their career growth and development can also benefit from these sessions. In this blog post, we […] The post Explore the World of Data-Tech with DataHour appeared first on Analytics Vidhya.
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. The following screenshot shows an example of the unified notebook page.
Accordingly, one of the most demanding roles is that of Azure DataEngineer Jobs that you might be interested in. The following blog will help you know about the Azure DataEngineering Job Description, salary, and certification course. How to Become an Azure DataEngineer?
Repeat the steps to add another Aurora MySQL data source, called aggregated_sales , for the same database but with the following details in the Sync scope This data source will be used by Amazon Q for answering questions on aggregated sales. DataEngineer at Amazon Ads. For IAM role , choose Create a new service role.
Simple Data Model for a Process Mining Event Log As part of dataengineering, the data traces that indicate process activities are brought into a log-like schema. And that´s why you should host any object-centric data model not in a dedicated tool for analysis but centralized on a Data Lakehouse System.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
In this blog, we’re going to try our best to remove as much of the uncertainty as possible by walking through the interview process here at phData for DataEngineers. Whether you’re officially job hunting or just curious about what it’s like to interview and work at phData as a DataEngineer, this is the blog for you!
Structured Query Language, or SQL, is a programming language used to communicate with databases. It means that SQL is the language used for storing, retrieving and manipulating data from relational databases. As a result, you may have a keen interest in finding the best books for SQL. A guidebook written by Allen G.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Summary: The ALTER TABLE command in SQL is used to modify table structures, allowing you to add, delete, or alter columns and constraints. Introduction The ALTER TABLE command in SQL is essential for modifying the structure of existing database tables. Read Blog: Discovering Different Types of Keys in Database Management Systems.
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of dataengineering and data science team’s bandwidth and data preparation activities.
Summary: The CASE statement in SQL provides conditional logic within queries, enabling flexible data manipulation. Proper usage and optimisation enhance query performance and adaptability, making it a crucial tool for effective SQLdata management. What is a CASE Statement in SQL? ELSE : An optional clause.
Whether you’re a seasoned tech professional looking to switch lanes, a fresh graduate planning your career trajectory, or simply someone with a keen interest in the field, this blog post will walk you through the exciting journey towards becoming a data scientist. Machine learning Machine learning is a key part of data science.
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provides a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. With that, let’s dive in!
Unlike traditional methods that rely on complex SQL queries for orchestration, Matillion Jobs provide a more streamlined approach. By converting SQL scripts into Matillion Jobs , users can take advantage of the platform’s advanced features for job orchestration, scheduling, and sharing. In our case, this table is “orders.”
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Many of the RStudio on SageMaker users are also users of Amazon Redshift , a fully managed, petabyte-scale, massively parallel data warehouse for data storage and analytical workloads. It makes it fast, simple, and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
In this blog, you’ll learn all about our Automated Testing tool including how to leverage it to automatically rerun any number of SQL scripts you’ve written in Matillion to ensure your workflows are working properly. The queries you add in the “SQL Query” column of that grid will be the ones to run automatically.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure.
In a series of articles, we’d like to share the results so you too can learn more about what the data science community is doing in machine learning. In the first blog, we’re going to discuss the technical side of things, such as what languages and platforms people are using. What areas of machine learning are you interested in?
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. HBase is employed to offer real-time key-based access to data.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the data pipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse. Thus, it has only a minimal footprint.
. “ Gen AI has elevated the importance of unstructured data, namely documents, for RAG as well as LLM fine-tuning and traditional analytics for machine learning, business intelligence and dataengineering,” says Edward Calvesbert, Vice President of Product Management at IBM watsonx and one of IBM’s resident data experts.
Während vor zehn Jahren ich für Celonis noch eine Installation erst einer MS SQL Server Datenbank, etwas später dann bevorzugt eine SAP Hana Datenbank auf einem on-prem Server beim Kunden voraussetzend installieren musste, bevor ich dann zur Installation der Celonis ServerAnwendung selbst kam, ist es heute eine 100% externe Cloud-Lösung.
There are several styles of data integration. Dataengineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
This blog post is an extension of our session, intended to reach a larger audience. Similarly, Function Pools pertains to the collection of functions or SQL templates that are pre-existing within our code base. We were thrilled to see nearly 100 active participants, both in-person and online.
Coalesce is a fantastic transformation tool built specifically to run on Snowflake AI Data Cloud. Because it runs Snowflake SQL from an easy-to-use, code-first GUI interface, it can take advantage of everything Snowflake offers, even if the feature is brand new.
Data Warehousing ist seit den 1980er Jahren die wichtigste Lösung für die Speicherung und Verarbeitung von Daten für Business Intelligence und Analysen. Mit der zunehmenden Datenmenge und -vielfalt wurde die Verwaltung von Data Warehouses jedoch immer schwieriger und teurer. The post Was ist ein Data Lakehouse?
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? Amazon S3, Azure Data Lake, or Google Cloud Storage). Why should we use it?
Today Velox is in various stages of integration with several data systems including Presto (Prestissimo), Spark (Gluten), PyTorch (TorchArrow), and Apache Arrow. You can read more about why Velox was built in Meta’s engineeringblog.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content