This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
As organizations are maturing their data infrastructure and accumulating more data than ever before in their datalakes, Open and Reliable table formats.
However, the sheer volume, variety, and velocity of data can overwhelm traditional data management solutions. Enter the datalake – a centralized repository designed to store all types of data, whether structured, semi-structured, or unstructured.
While datalakes and data warehouses are both important Data Management tools, they serve very different purposes. If you’re trying to determine whether you need a datalake, a data warehouse, or possibly even both, you’ll want to understand the functionality of each tool and their differences.
Recently we’ve seen lots of posts about a variety of different file formats for datalakes. There’s Delta Lake, Hudi, Iceberg, and QBeast, to name a few. It can be tough to keep track of all these datalake formats — let alone figure out why (or if!) And I’m curious to see if you’ll agree.
The post DataLakes for Non-Techies appeared first on DATAVERSITY. Moreover, complex usability helped in developing a network of certified (aka expensive and lucrative) consultancy workforce. IT has recently experienced […].
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, datalakes, frontends, and pipelines/ETL.
Was gerade zum Trend wird, ist der Aufbau eines Data Lakehouses. Ein Lakehouse inkludiert auch clevere Art und Weise auch einen DataLake. Ein DataLake ist dann sowas wie die eine böse Schublade, die man eigentlich gar nicht haben möchte, aber in die man dann alle Briefe, Dokumente usw.
According to a recent report, data breaches exposed a staggering 35 billion records in the first four months of 2024. To deal with this escalating crisis, a new solution […] The post The Rise of Cybersecurity DataLakes: Shielding the Future of Data appeared first on DATAVERSITY.
It has been ten years since Pentaho Chief Technology Officer James Dixon coined the term “datalake.” While data warehouse (DWH) systems have had longer existence and recognition, the data industry has embraced the more […]. The post A Bridge Between DataLakes and Data Warehouses appeared first on DATAVERSITY.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Writing data to an AWS datalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the datalake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
Data Swamp vs DataLake. When you imagine a lake, it’s likely an idyllic image of a tree-ringed body of reflective water amid singing birds and dabbling ducks. I’ll take the lake, thank you very much. Many organizations have built a datalake to solve their data storage, access, and utilization challenges.
In the ever-evolving landscape of data management, two key concepts have emerged as essential components for organizations seeking to harness the power of their data: data marts and datalakes. Understanding the distinctions […]
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
A datalake becomes a data swamp in the absence of comprehensive data quality validation and does not offer a clear link to value creation. Organizations are rapidly adopting the cloud datalake as the datalake of choice, and the need for validating data in real time has become critical.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
The data being talked about is useful for businesses to draw insights, formulate strategies, and understand trends and customer behavior, among others. […]. The post Maximize the ROI of Your Enterprise DataLake appeared first on DATAVERSITY.
When it was no longer a hard requirement that a physical data model be created upon the ingestion of data, there was a resulting drop in richness of the description and consistency of the data stored in Hadoop. You did not have to understand or prepare the data to get it into Hadoop, so people rarely did.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. Without business context, business users are less likely to use the datalake and insights will be hard to come by.
The data we produce and manage is growing in scale and demands careful consideration of the proper data framework for the job. There’s no one-size-fits-all data architecture, and […]. The post DataLakes Are Dead: Evolving Your Company’s Data Architecture appeared first on DATAVERSITY.
Automatisierung: Erstellt SQL-Code, DACPAC-Dateien, SSIS-Pakete, Data Factory-ARM-Vorlagen und XMLA-Dateien. DataLakes: Unterstützt MS Azure Blob Storage. Pipelines/ETL : Unterstützt Technologien wie SQL Server Integration Services und Azure Data Factory.
The rise of datalakes and adjacent patterns such as the data lakehouse has given data teams increased agility and the ability to leverage major amounts of data. Constantly evolving data privacy legislation and the impact of major cybersecurity breaches has led to the call for responsible data […].
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? It can also be integrated into major data platforms like Snowflake. Contact phData Today!
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a datalake, and building an API to extract needed information isn’t working. Click to learn more about author Brian Platz.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect. option("sep", ",").load("s3://aws-blogs-artifacts-public/artifacts/BDB-4798/data/venue.csv")
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
A data lakehouse contains an organization’s data in a unstructured, structured, semi-structured form, which can be stored indefinitely for immediate or future use. This data is used by data scientists and engineers who study data to gain business insights.
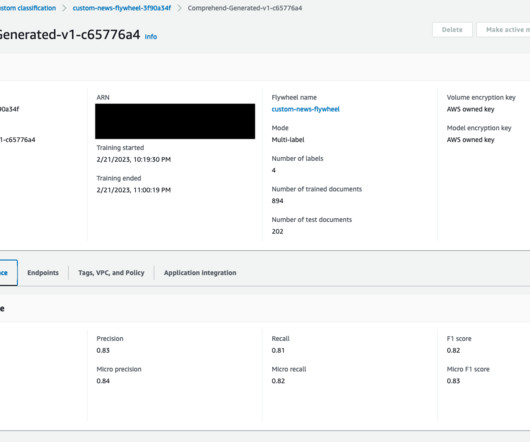
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. One for the datalake for Comprehend flywheel.
This feature also allows you to automate model retraining after new datasets are ingested and available in the flywheel´s datalake. Datalake – A flywheel’s datalake is a location in your Amazon Simple Storage Service (Amazon S3) bucket that stores all its datasets and model artifacts.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt. Arghya Banerjee is a Sr.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
A data lakehouse architecture combines the performance of data warehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI.
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
Amazon Simple Storage Service (Amazon S3) stores the model artifacts and creates a datalake to host the inference output, document analysis output, and other datasets in CSV format. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. This blog post has demonstrated how AWS can greatly benefit your SaaS company, on multiple levels. Conclusions.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content