This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Big Data Architect. option("sep", ",").load("s3://aws-blogs-artifacts-public/artifacts/BDB-4798/data/venue.csv")
Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images. The model was then fine-tuned with training data from the datapreparation stage. The sunburst graph below is a visualization of this classification.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The datalake environment is required to configure an AWS Glue database table, which is used to publish an asset in the Amazon DataZone catalog.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. One for the datalake for Comprehend flywheel.
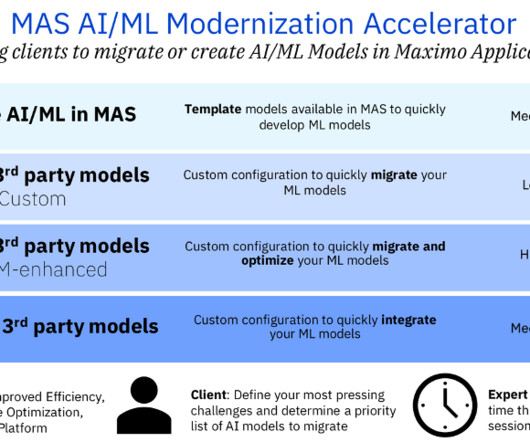
In this blog, we delve into 4 different “on-ramps” we created in a MAS Accelerator to offer a straightforward path to harnessing the power of AI in MAS, wherever you may be on your MAS AI/ML modernization journey. In our scenario, the data is stored in the Cloud Object Storage in Watson Studio.
Increased operational efficiency benefits Reduced datapreparation time : OLAP datapreparation capabilities streamline data analysis processes, saving time and resources. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
These teams are as follows: Advanced analytics team (datalake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
Data collection and ingestion The data collection and ingestion layer connects to all upstream data sources and loads the data into the datalake. Therefore, the ingestion components need to be able to manage authentication, data sourcing in pull mode, data preprocessing, and data storage.
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
Figure 1 illustrates the typical metadata subjects contained in a data catalog. Figure 1 – Data Catalog Metadata Subjects. Datasets are the files and tables that data workers need to find and access. They may reside in a datalake, warehouse, master data repository, or any other shared data resource.
Businesses require Data Scientists to perform Data Mining processes and invoke valuable data insights using different software and tools. What is Data Mining and how is it related to Data Science ? Let’s learn from the following blog! What is Data Mining? are the various data mining tools.
It offers its users advanced machine learning, data management , and generative AI capabilities to train, validate, tune and deploy AI systems across the business with speed, trusted data, and governance. It helps facilitate the entire data and AI lifecycle, from datapreparation to model development, deployment and monitoring.
Whether it’s for ad hoc analytics, data transformation, data sharing, datalake modernization or ML and gen AI, you have the flexibility to choose. Integrated solutions for zero-ETL datapreparation: IBM databases on AWS offer integrated solutions that eliminate the need for ETL processes in datapreparation for AI.
Data Catalogs for Data Science & Engineering – Data catalogs that are primarily used for data science and engineering are typically used by very experienced data practitioners. It also catalogs datasets and operations that includes datapreparation features and functions.
Dataflows allow users to establish source connections and retrieve data, and subsequent data transformations can be conducted using the online Power Query Editor. In this blog, we will provide insights into the process of creating Dataflows and offer guidance on when to choose them to address real-world use cases effectively.
In this blog, I will cover: What is watsonx.ai? sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support. What capabilities are included in watsonx.ai?
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. Check out the AWS Blog for more practices about building ML features from a modern data warehouse.
Datapreparation Before creating a knowledge base using Knowledge Bases for Amazon Bedrock, it’s essential to prepare the data to augment the FM in a RAG implementation. Data discovery and findability Findability is an important step of the process.
Even something like gamification may emerge as a way to fully engage data shoppers as a community. Behind the scenes, ‘backroom services” will power the storefront, performing such tasks as data acquisition, datapreparation, data curation and cataloging, and tracking. Building the EDM.
ODSC West 2024 showcased a wide range of talks and workshops from leading data science, AI, and machine learning experts. This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, data modeling, and deployment strategies.
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. Data preprocessing and feature engineering In this section, we discuss our methods for datapreparation and feature engineering.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Mai-Lan Tomsen Bukovec, Vice President, Technology | AIM250-INT | Putting your data to work with generative AI Thursday November 30 | 12:30 PM – 1:30 PM (PST) | Venetian | Level 5 | Palazzo Ballroom B How can you turn your datalake into a business advantage with generative AI? You must bring your laptop to participate.
In a recent blog, titled Collaboration and Crowdsourcing with Data Cataloging , I discussed the importance of participation by all data stakeholders as a key to getting maximum value from your data catalog. Their tendency is to do just enough data work to get by, and to do that work primarily in Excel spreadsheets.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring.
Data must be available at the right moment for consumption and it might not be the easiest task to develop a strategy around the continuous pipelines and the integrated applications to set up your stack. Alteryx and the Snowflake Data Cloud offer a potential solution to this issue and can speed up your path to Analytics.
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage.
In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting. Datapreparation, train and tune, deploy and monitor. We have data pipelines and datapreparation. It can cover the gamut.
In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting. Datapreparation, train and tune, deploy and monitor. We have data pipelines and datapreparation. It can cover the gamut.
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches.
Placing functions for plotting, data loading, datapreparation, and implementations of evaluation metrics in plain Python modules keeps a Jupyter notebook focused on the exploratory analysis | Source: Author Using SQL directly in Jupyter cells There are some cases in which data is not in memory (e.g.,
Also consider using Amazon Security Lake to automatically centralize security data from AWS environments, SaaS providers, on premises, and cloud sources into a purpose-built datalake stored in your account.
The pipelines are interoperable to build a working system: Data (input) pipeline (data acquisition and feature management steps) This pipeline transports raw data from one location to another. Model/training pipeline This pipeline trains one or more models on the training data with preset hyperparameters.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
Datalakes, while useful in helping you to capture all of your data, are only the first step in extracting the value of that data. We recently announced an integration with Trifacta to seamlessly integrate the Alation Data Catalog with self-service data prep applications to help you solve this issue.
This highlights the two companies’ shared vision on self-service data discovery with an emphasis on collaboration and data governance. 2) When data becomes information, many (incremental) use cases surface.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content