This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
While there is a lot of discussion about the merits of data warehouses, not enough discussion centers around datalakes. We talked about enterprise data warehouses in the past, so let’s contrast them with datalakes. Both data warehouses and datalakes are used when storing big data.
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, datalakes, frontends, and pipelines/ETL.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a datalake, and building an API to extract needed information isn’t working. The post Why Graph Databases Are an Essential Choice for Master Data Management appeared first on DATAVERSITY.
Writing data to an AWS datalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the datalake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
tl;dr Ein Data Lakehouse ist eine moderne Datenarchitektur, die die Vorteile eines DataLake und eines Data Warehouse kombiniert. Die Definition eines Data Lakehouse Ein Data Lakehouse ist eine moderne Datenspeicher- und -verarbeitungsarchitektur, die die Vorteile von DataLakes und Data Warehouses vereint.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. option("multiLine", "true").option("header",
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage. Also, traditional database management tasks, including backups, upgrades and routine maintenance drain valuable time and resources, hindering innovation.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Open Table Format (OTF) architecture now provides a solution for efficient data storage, management, and processing while ensuring compatibility across different platforms. In this blog, we will discuss: What is the Open Table format (OTF)? It can also be integrated into major data platforms like Snowflake. Contact phData Today!
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. This blog post has demonstrated how AWS can greatly benefit your SaaS company, on multiple levels.
Benefits of new data warehousing technology Everything is data, regardless of whether it’s structured, semi-structured, or unstructured. Most of the enterprise or legacy data warehousing will support only structured data through relational database management system (RDBMS) databases.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt. Arghya Banerjee is a Sr.
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
This blog was originally written by Keith Smith and updated for 2024 by Justin Delisi. Snowflake’s Data Cloud has emerged as a leader in cloud data warehousing. A cloud data warehouse is designed to combine a concept that every organization knows, namely a data warehouse, and optimizes the components of it, for the cloud.
To do this, the text input is transformed into a structured representation, and from this representation, a SQL query that can be used to access a database is created. The primary goal of Text2SQL is to make querying databases more accessible to non-technical users, who can provide their queries in natural language. gymnast_id = t2.
But what most people don’t realize is that behind the scenes, Uber is not just a transportation service; it’s a data and analytics powerhouse. Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This enables them to batch queries based on speed or accuracy.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables.
On the business side, Amazon Q Business is bridging the gap between unstructured and structured data, recognizing that most businesses need to draw from a mix of data. Now they can access databases and data warehouses, as well as unstructured business data, like emails, reports, charts, graphs, and images.
To set up RAG, you need to have a vector database to provide your model with related source documents. A vector store is a system you can use to store and query vectors at scale, with efficient nearest neighbor query algorithms and appropriate indexes to improve data retrieval. These safeguards are FM agnostic.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
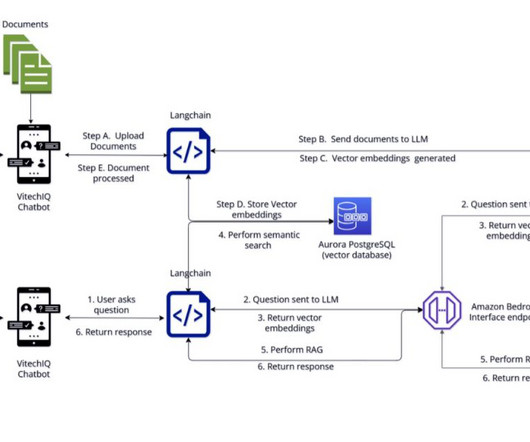
In this blog, we walkthrough the architectural components, evaluation criteria for the components selected by Vitech and the process flow of user interaction within VitechIQ. However, Vitech has expertise in handling and managing Amazon Aurora PostgreSQL-Compatible Edition databases for their enterprise applications.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
In the early days of business analysis and underwriting, data was managed with simply a pen and paper and, of course, Excel spreadsheets. As technology has advanced, databases, warehouses, and datalakes have enabled information to be collected, stored, and managed electronically.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Setup the Database access and Network access.
Thoughtworks says data mesh is key to moving beyond a monolithic datalake. Spoiler alert: data fabric and data mesh are independent design concepts that are, in fact, quite complementary. Thoughtworks says data mesh is key to moving beyond a monolithic datalake 2. Gartner on Data Fabric.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again. Subscribe to Alation's Blog.
Online analytical processing (OLAP) database systems and artificial intelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Defining OLAP today OLAP database systems have significantly evolved since their inception in the early 1990s.
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. A data fabric is comprised of a network of data nodes (e.g.,
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. This table is used for finding the correct table, database, and attributes.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. Choose Next.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
For more detail on each of these integrations, check out our Einstein Discovery in Tableau blog post. . You can now connect to your data in Azure SQL Database (with Azure Active Directory) and Azure DataLake Gen 2. Stay on top of important updates with our new unified notification experience.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content