This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. Recent developments in generative AI models have further sped up the need of ML adoption across industries.
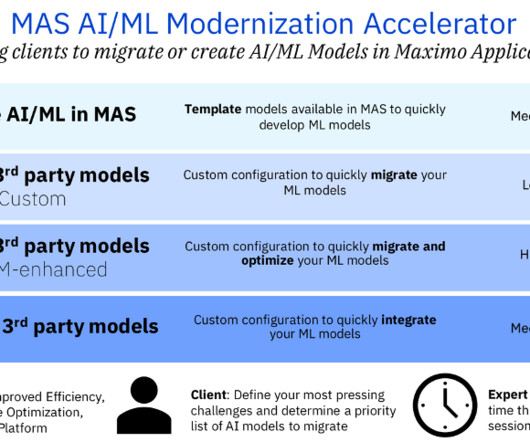
Many businesses are in different stages of their MAS AI/ML modernization journey. In this blog, we delve into 4 different “on-ramps” we created in a MAS Accelerator to offer a straightforward path to harnessing the power of AI in MAS, wherever you may be on your MAS AI/ML modernization journey.
Enterprises migrating on-prem data environments to the cloud in pursuit of more robust, flexible, and integrated analytics and AI/ML capabilities are fueling a surge in cloud datalake implementations. The post How to Ensure Your New Cloud DataLake Is Secure appeared first on DATAVERSITY.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Data engineers use data warehouses, datalakes, and analytics tools to load, transform, clean, and aggregate data. Choose Continue.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data. Run the AWS Glue ML transform job.
A datalake becomes a data swamp in the absence of comprehensive data quality validation and does not offer a clear link to value creation. Organizations are rapidly adopting the cloud datalake as the datalake of choice, and the need for validating data in real time has become critical.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. Enterprises can use no-code ML solutions to streamline their operations and optimize their decision-making without extensive administrative overhead.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
This post, part of the Governing the ML lifecycle at scale series ( Part 1 , Part 2 , Part 3 ), explains how to set up and govern a multi-account ML platform that addresses these challenges. An enterprise might have the following roles involved in the ML lifecycles. This ML platform provides several key benefits.
Solution overview Amazon SageMaker is a fully managed service that helps developers and data scientists build, train, and deploy machine learning (ML) models. Data preparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
This combination of great models and continuous adaptation is what will lead to a successful machine learning (ML) strategy. MLOps focuses on the intersection of data science and data engineering in combination with existing DevOps practices to streamline model delivery across the ML development lifecycle.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
Data is the foundation for machine learning (ML) algorithms. One of the most common formats for storing large amounts of data is Apache Parquet due to its compact and highly efficient format. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake.
In this blog post, we demonstrate prompt engineering techniques to generate accurate and relevant analysis of tabular data using industry-specific language. This is done by providing large language models (LLMs) in-context sample data with features and labels in the prompt. Arghya Banerjee is a Sr. Solutions Architect at AWS.
ML operationalization summary As defined in the post MLOps foundation roadmap for enterprises with Amazon SageMaker , ML and operations (MLOps) is the combination of people, processes, and technology to productionize machine learning (ML) solutions efficiently.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
By running reports on historical data, a data warehouse can clarify what systems and processes are working and what methods need improvement. Data warehouse is the base architecture for artificial intelligence and machine learning (AI/ML) solutions as well.
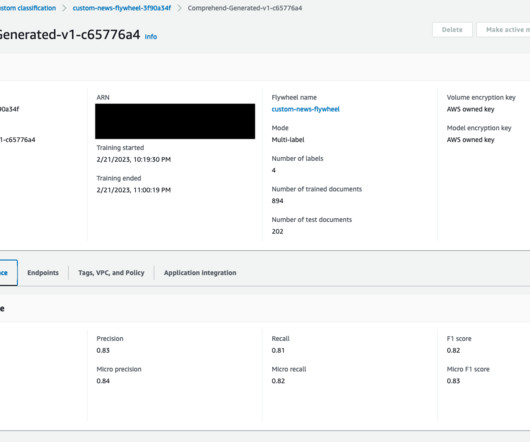
Flywheel creates a datalake (in Amazon S3) in your account where all the training and test data for all versions of the model are managed and stored. Periodically, the new labeled data (to retrain the model) can be made available to flywheel by creating datasets. One for the datalake for Comprehend flywheel.
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
Elymsyr wants to develop new projects to improve their ML, RL, computer vision, and co-working skills. Streamline ML Workflow with MLflow — II by ronilpatil This article explains how to leverage MLflow to track machine learning experiments, register a model, and serve the model into production. Think a friend would enjoy this too?
A data lakehouse architecture combines the performance of data warehouses with the flexibility of datalakes, to address the challenges of today’s complex data landscape and scale AI.
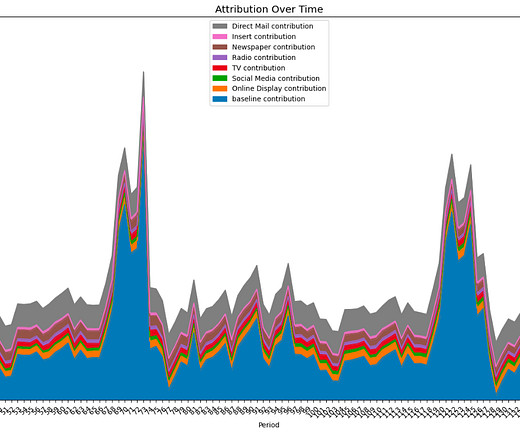
Unlock the Power of Media Mix Modeling for Effective Advertising In this blog, we will provide a quick overview of media mix modeling and how you can get started with it. 5 Concerns for ML Safety in the Era of LLMs and Generative AI The growth of large language models and generative AI has spurred new concerns for ML safety and cybersecurity.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Since AI is a central pillar of their value offering, Sense has invested heavily in a robust engineering organization including a large number of data and AI professionals. This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. Gennaro Frazzingaro, Head of AI/ML at Sense.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. This blog post has demonstrated how AWS can greatly benefit your SaaS company, on multiple levels. Conclusions.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts.
This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. The AI/Ml team is made up of ML engineers, data scientists and backend product engineers. With Iguazio, Sense’s data professionals can pull data, analyze it, train and run experiments.
Evaluating ML model performance is essential for ensuring the reliability, quality, accuracy and effectiveness of your ML models. In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and prepare data for machine learning (ML) from weeks to minutes. Data is frequently kept in datalakes that can be managed by AWS Lake Formation , giving you the ability to implement fine-grained access control using a straightforward grant or revoke procedure.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
These tools may have their own versioning system, which can be difficult to integrate with a broader data version control system. For instance, our datalake could contain a variety of relational and non-relational databases, files in different formats, and data stored using different cloud providers. DVC Git LFS neptune.ai
It offers an extensive suite of AI and ML services, including: Amazon SageMaker for end-to-end ML model development.EC2 GPU instances (NVIDIA A100, V100, etc.) It offers an extensive suite of AI and ML services, including: Amazon SageMaker for end-to-end ML model development.EC2 GPU instances (NVIDIA A100, V100, etc.)
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
A novel approach to solve this complex security analytics scenario combines the ingestion and storage of security data using Amazon Security Lake and analyzing the security data with machine learning (ML) using Amazon SageMaker. Deploy the trained ML model to a SageMaker inference endpoint.
Staying ahead of key technology trends By now, it’s abundantly clear that technologies like artificial intelligence (AI) and machine learning (ML) will revolutionize how customer-centric organizations interact and deliver value to all stakeholders, especially their customers.
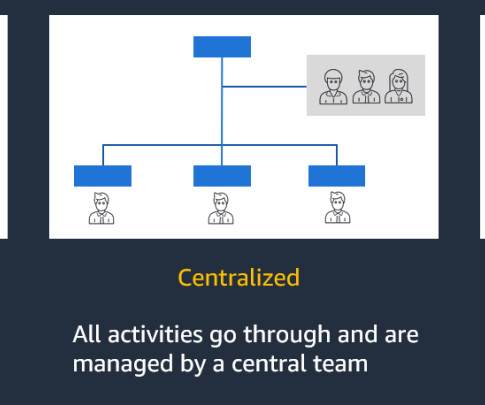
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
Sheer volume of data makes automation with Artificial Intelligence & Machine Learning (AI & ML) an imperative. Menninger outlines how modern data governance practices may deploy a basic repository of data; this can help with some level of automation. Datalakes are repositories where much of this data winds up.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including datalakes, analytics dashboards, and ETL pipelines.
We capitalized on the powerful tools provided by AWS to tackle this challenge and effectively navigate the complex field of machine learning (ML) and predictive analytics. SageMaker is a fully managed ML service. This was a crucial aspect in achieving agility in our operations and a seamless integration of our ML efforts.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. This solution employs machine learning (ML) for anomaly detection, and doesn’t require users to have prior AI expertise. anomalyScore":0.0,"detectionPeriodStartTime":"2024-08-29
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content