This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Events Data + AI Summit Data + AI World Tour Data Intelligence Days Event Calendar Blog and Podcasts Databricks Blog Explore news, product announcements, and more Databricks Mosaic Research Blog Discover the latest in our Gen AI research Data Brew Podcast Let’s talk data!
Through big datamodeling, data-driven organizations can better understand and manage the complexities of big data, improve business intelligence (BI), and enable organizations to benefit from actionable insight.
Data, undoubtedly, is one of the most significant components making up a machine learning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
This blog delves into a detailed comparison between the two data management techniques. In today’s digital world, businesses must make data-driven decisions to manage huge sets of information. Hence, databases are important for strategic data handling and enhanced operational efficiency.
This time, well be going over DataModels for Banking, Finance, and Insurance by Claire L. This book arms the reader with a set of best practices and datamodels to help implement solutions in the banking, finance, and insurance industries. Welcome to the first Book of the Month for 2025.This
Reading Larry Burns’ “DataModel Storytelling” (TechnicsPub.com, 2021) was a really good experience for a guy like me (i.e., someone who thinks that datamodels are narratives). The post Tales of DataModelers appeared first on DATAVERSITY. The post Tales of DataModelers appeared first on DATAVERSITY.
It offers full BI-Stack Automation, from source to data warehouse through to frontend. It supports a holistic datamodel, allowing for rapid prototyping of various models. It also supports a wide range of data warehouses, analytical databases, data lakes, frontends, and pipelines/ETL. Mixed approach of DV 2.0
New big data architectures and, above all, data sharing concepts such as Data Mesh are ideal for creating a common database for many data products and applications. The Event Log DataModel for Process Mining Process Mining as an analytical system can very well be imagined as an iceberg.
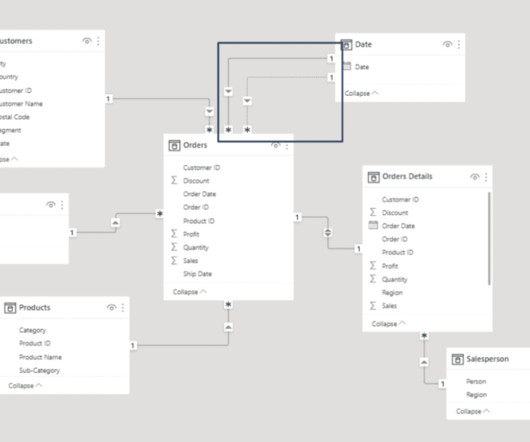
While the front-end report visuals are important and the most visible to end users, a lot goes on behind the scenes that contribute heavily to the end product, including datamodeling. In this blog, we’ll describe datamodeling and its significance in Power BI. What is DataModeling?
Sources of Hallucinations: Generalized Training Data: Models trained on non-specialized data may lack depth in healthcare-specific contexts.Probabilistic Generation: LLMs generate text based on probability, which sometimes leads them to select… Read the full blog for free on Medium.
So, I had to cut down my January 2021 list of things of importance in DataModeling in this new, fine year (I hope)! The post 2021: Three Game-Changing DataModeling Perspectives appeared first on DATAVERSITY. Common wisdom has it that we humans can only focus on three things at a time.
A unified datamodel allows businesses to make better-informed decisions. By providing organizations with a more comprehensive view of the data sources they’re using, which makes it easier to understand their customers’ experiences. appeared first on DATAVERSITY.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Data scientists use different tools for tasks like data visualization, datamodeling, and even warehouse systems.
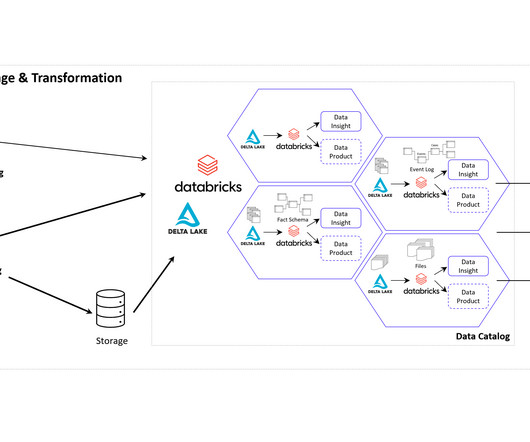
Data Mesh on Azure Cloud with Databricks and Delta Lake for Applications of Business Intelligence, Data Science and Process Mining. With the concept of Data Mesh you will be able to access all your organizational internal and external data sources once and provides the data as several datamodels for all your analytical applications.
Data Governance describes the practices and processes organizations use to manage the access, use, quality and security of an organizations data assets. The data-driven business era has seen a rapid rise in the value of organization’s data resources.
It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible. Learn about datamodeling: Datamodeling is the process of creating a conceptual representation of data.
What is the purpose of this… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter. Convert these to a string: df['a'] = 'a' + df['a'].astype(str)df['b'] astype(str)df['b'] = 'b' + df['b'].astype(str)df['c']
Therefore, it was just a matter of time before this chess-inspired outlook permeated my professional life as a data practitioner. In both chess and datamodeling, the […] The post Data’s Chess Game: Strategic Moves in DataModeling for Competitive Advantage appeared first on DATAVERSITY.
The tagline on the book is Boosting Productivity Through Data Structure Reuse.Ultimately, the book is about combining the mathematical truths of set theory and applying that to datamodeling, but all wrapped together in an adventure with the author.
In the contemporary business environment, the integration of datamodeling and business structure is not only advantageous but crucial. This dynamic pair of documents serves as the foundation for strategic decision-making, providing organizations with a distinct pathway toward success.
However, to fully harness the potential of a data lake, effective datamodeling methodologies and processes are crucial. Datamodeling plays a pivotal role in defining the structure, relationships, and semantics of data within a data lake. Consistency of data throughout the data lake.
This requires a strategic approach, in which CxOs should define business objectives, prioritize data quality, leverage technology, build a data-driven culture, collaborate with […] The post Facing a Big Data Blank Canvas: How CxOs Can Avoid Getting Lost in DataModeling Concepts appeared first on DATAVERSITY.
Tabular data is the data in the typical table — some columns and rows are structured well, like in Excel or SQL data. It's the most common usage of data forms in many data use cases. With the power of LLM, we would learn how to explore the data and perform datamodeling. How do we do?
What is happening to stock market forecasting by AI will be discussed in this blog. And well see how it plays out in the technology, in the data-mining and for investors. #1 Good data is the main factor in AI prediction. Overfitting: Overfitting is when the AI learns the training data too fast, with noise and outliers.
This ensures that the datamodels and queries developed by data professionals are consistent with the underlying infrastructure. Enhanced Security and Compliance Data Warehouses often store sensitive information, making security a paramount concern. appeared first on Data Science Blog.
Designing datamodels and generating Entity-Relationship Diagrams (ERDs) demand significant effort and expertise. Datamodel creation : Based on use cases and user stories, watsonx can generate robust datamodels representing the software’s data structure.
One of the most important questions about using AI responsibly has very little to do with data, models, or anything technical. How can […] The post Ask a Data Ethicist: How Can We Set Realistic Expectations About AI? It has to do with the power of a captivating story about magical thinking.
I’m not going to go into huge details on this as if you follow AI / LLM (which I assume you do if you are reading this) but in a nutshell, RAG is the process whereby you feed external data into an LLM alongside prompts to ensure it has all of the information it needs to make decisions. What is GraphRAG? Why use Graphs and what are they?
For your reference, this blog post demonstrates a solution to create a VPC with no internet connection using an AWS CloudFormation template. Run ML experimentation with MLflow using the @remote decorator from the open-source SageMaker Python SDK. The overall solution architecture is shown in the following figure.
Data is an essential component of any business, and it is the role of a data analyst to make sense of it all. Power BI is a powerful data visualization tool that helps them turn raw data into meaningful insights and actionable decisions. Check out this course and learn Power BI today!
In this blog post, we spotlight a leading player in the gen AI infrastructure ecosystem, NVIDIA , commonly known for their GPUs, software and research that have helped drive gen AI implementation and research. We introduce their new solution model deployment - NVIDIA NIM. Adding observability, logging and experiment tracking.
In this blog, we’ll explore the defining traits, benefits, use cases, and key factors to consider when choosing between SQL and NoSQL databases. SQL or NoSQL SQL Database SQL databases are relational databases that store data in tables. So, let’s dive in!
Data science myths are one of the main obstacles preventing newcomers from joining the field. In this blog, we bust some of the biggest myths shrouding the field. The US Bureau of Labor Statistics predicts that data science jobs will grow up to 36% by 2031.
In a previous blog, we presented the three-layered model for efficient network operations. The main challenges in the context of applying generative AI across these layers are: Data layer : Generative AI initiatives are data projects at their core, with inadequate data comprehension being one of the primary complexities.
Row-level security is a powerful data governance capability across many business intelligence platforms, and Power BI is no exception. In this blog, we will provide a high-level summary of row-level security, why it’s important for your team, when to use it, and how to set it up in Power BI. In the new window, click Manage roles.
An industry-standard datamodel A uniform datamodel is necessary to get a full view of combined systems with information flowing across the ecosystem. Technical, financial, geographical, operational and transactional data attributes are all parts of a data structure.
Every individual analysis the data obtained via their experience to generate a final decision. Put more concretely, data analysis involves sifting through data, modeling it, and transforming it to yield information that guides strategic decision-making.
ISO 20022 data improves payment efficiency The impact of ISO 20022 on payment systems data is significant, as it allows for more detailed information in payment messages. appeared first on IBM Blog. Talk to the IBM Payments Center team The post ISO 20022: Are your payment systems ready?
Our goal is to enable you to set up automated, optimal routing between large language models (LLMs) through Amazon Bedrock Intelligent Prompt Routing and its deep understanding of model behaviors within each model family, which incorporates state-of-the-art methods for training routers for different sets of models, tasks and prompts.
Just as a chef’s masterpiece depends on the quality of the ingredients, your AI outcomes will depend on the data you prepare. Investing in your data can only lead to positive results. The post Looking Ahead: The Future of Data Preparation for Generative AI appeared first on Data Science Blog.
For the past 20 years, he has been helping customers build enterprise data strategies, advising them on Generative AI, cloud implementations, migrations, reference architecture creation, datamodeling best practices, and data lake/warehouse architectures.
This blog was written by Spencer Baucke and updated for 2023 by Gavin Pedersen. Letting your Power BI datamodel get disorganized is a feeling every Power BI developer knows all too well, and it’s something that can occur very quickly when developing. Open the model view by clicking the datamodel icon on the left.
Enterprise applications serve as repositories for extensive datamodels, encompassing historical and operational data in diverse databases. Generative AI foundational models train on massive amounts of unstructured and structured data, but the orchestration is critical to success.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content