This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
In this blog post, we introduce the joint MongoDB - Iguazio gen AI solution, which allows for the development and deployment of resilient and scalable gen AI applications. Iguazio capabilities: Structured and unstructured datapipelines for processing, versioning and loading documents.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
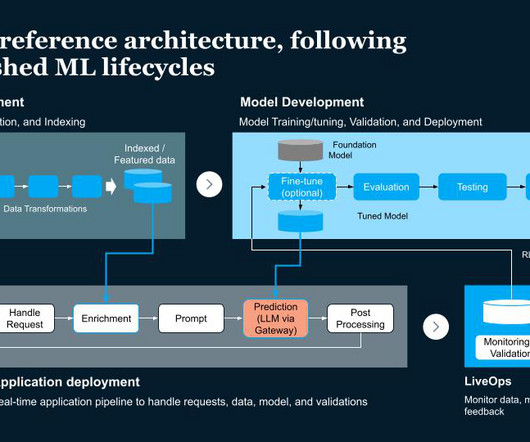
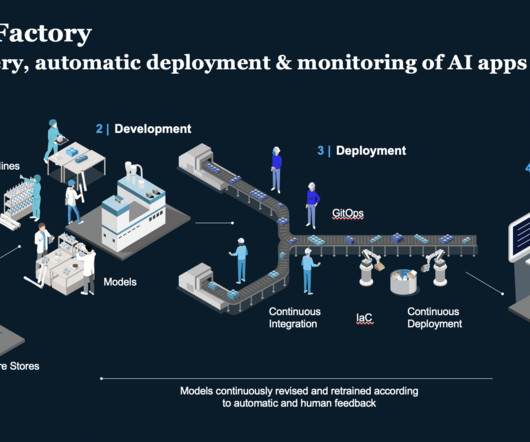
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? It could help you detect and prevent datapipeline failures, data drift, and anomalies.
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
It brings together business users, data scientists , data analysts, IT, and application developers to fulfill the business need for insights. DataOps then works to continuously improve and adjust datamodels, visualizations, reports, and dashboards to achieve business goals. Subscribe to Alation's Blog.
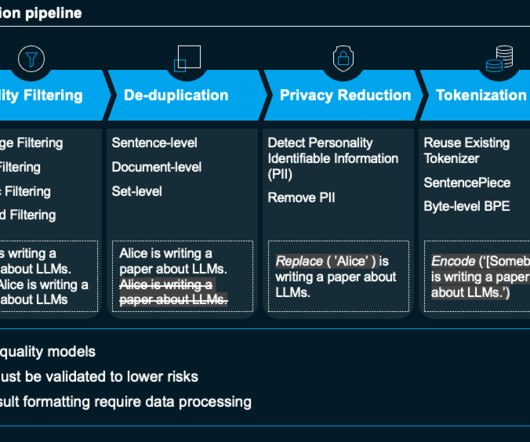
But doing so requires significant engineering, quality data and overcoming risks. In this blog post, we show all the elements and practices you need to to take to productize LLMs and generative AI. You can watch the full talk this blog post is based on, which took place at ODSC West 2023, here. This helps cleanse the data.
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. The modern data stack is important because its suite of tools is designed to solve all of the core data challenges companies face.
In this blog, our focus will be on exploring the data lifecycle along with several Design Patterns, delving into their benefits and constraints. Data architects can leverage these patterns as starting points or reference models when designing and implementing data vault architectures.
This blog highlights the importance of organised, flexible configurations in ML workflows and introduces Hydra. Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale datapipelines.
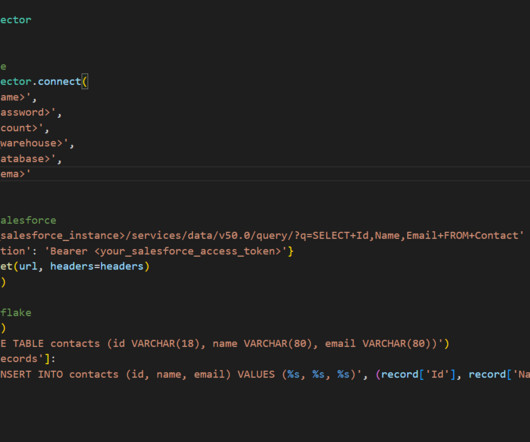
To uncover this data, it needs to be consolidated, easily accessible, and living in a central location, which is precisely why many of our customers turn to the Snowflake Data Cloud. Why is it Important to Ingest Salesforce Data in Snowflake? This eliminates the need for manual data entry and reduces the risk of human error.
Risk, compliance, data privacy and escalating costs are just a few of the acute concerns that financial services companies are grappling with today. This includes management vision and strategy, resource commitment, data and tech and operating model alignment, robust risk management and change management. Read more here.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. What are Snowflake Dynamic Tables?
If you’re interested in learning more, we highly recommend checking out our comprehensive blog that covers this in much more detail. How to Connect Power BI to Snowflake Choose Import or Directquery Mode Carefully Power BI offers two main connection types when connecting to data sources, Import and DirectQuery.
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
DataModeling, dbt has gradually emerged as a powerful tool that largely simplifies the process of building and handling datapipelines. dbt is an open-source command-line tool that allows data engineers to transform, test, and document the data into one single hub which follows the best practices of software engineering.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
Welcome to Beyond the Data, a series that investigates the people behind the talent of phData. In this blog, we’re featuring Eugenia Pais, a Sr. Data Engineer at phData. I consciously chose to pivot away from general software development and specialize in Data Engineering.
What does a modern data architecture do for your business? A modern data architecture like Data Mesh and Data Fabric aims to easily connect new data sources and accelerate development of use case specific datapipelines across on-premises, hybrid and multicloud environments.
At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration.
Getting your data into Snowflake, creating analytics applications from the data, and even ensuring your Snowflake account runs smoothly all require some sort of tool. In this blog, we’ll review some of the best free tools for use with Snowflake Data Cloud , what they can do for you, and how to use them without breaking the bank.
This blog post delves into the concepts of LLMOps and MLOps, explaining how and when to use each one. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By doing so, you can ensure quality and production-ready models.
Companies at this stage will likely have a team of ML engineers dedicated to creating datapipelines, versioning data, and maintaining operations monitoring data, models & deployments. By now, data scientists have witnessed success optimizing internal operations and external offerings through AI.
Within this data ocean, a specific type holds immense value: time series data. This data captures measurements or events at specific points in time, essentially creating a digital record of how something changes over time. Buckle up as we navigate the intricacies of storing and analysing this dynamic data.
Introduction Dimensional modelling is crucial for organising data to enhance query performance and reporting efficiency. Effective schema design is essential for optimising data retrieval and analysis in data warehousing. Must Read Blogs: Exploring the Power of Data Warehouse Functionality.
Under this category, tools with pre-built connectors for popular data sources and visual tools for data transformation are better choices. This setting ensures that the datapipeline adapts to changes in the Source schema according to user-specific needs.
This will require investing resources in the entire AI and ML lifecycle, including building the datapipeline, scaling, automation, integrations, addressing risk and data privacy, and more. By doing so, you can ensure quality and production-ready models.
Data engineering is a fascinating and fulfilling career – you are at the helm of every business operation that requires data, and as long as users generate data, businesses will always need data engineers. The journey to becoming a successful data engineer […]. In other words, job security is guaranteed.
Since you found your way to this blog, you must have already been familiar with the dbt Cloud. In this blog, we will explore the importance of codifying best practices in dbt and provide you with practical guidance on how to do so. Hence, referencing staging models for downstream models is considered to be legal.
A typical machine learning pipeline with various stages highlighted | Source: Author Common types of machine learning pipelines In line with the stages of the ML workflow (data, model, and production), an ML pipeline comprises three different pipelines that solve different workflow stages.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Blog - Everest Group Requirements gathering: ChatGPT can significantly simplify the requirements gathering phase by building quick prototypes of complex applications. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Team composition The team comprises datapipeline engineers, ML engineers, full-stack engineers, and data scientists. Organization Acquia Industry Software-as-a-service Team size Acquia built an ML team five years ago in 2017 and has a team size of 6.
This past week, I had the pleasure of hosting Data Governance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , Data Governance lead at Alation. These reports (combined with updates to the data governance roadmap, and your progress narrative) tell a great story. This is a very good thing.
Enter dbt dbt provides SQL-centric transformations for your datamodeling and transformations, which is efficient for scrubbing and transforming your data while being an easy skill set to hire for and develop within your teams. It should also enable easy sharing of insights across the organization.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
In this blog post, we bring insights for AI leaders Svetlana Sicular, Research VP, AI Strategy, Gartner and Yaron Haviv, co-founder and CTO, Iguazio (acquired by McKinsey). Automate productization, like auto-gen batching, real-time datapipelines, automated model training and CI/CD.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content