This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To unlock the potential of generative AI technologies, however, there’s a key prerequisite: your data needs to be appropriately prepared. In this post, we describe how use generative AI to update and scale your datapipeline using Amazon SageMaker Canvas for data prep.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with datapipelines and orderly, efficient data warehouses. But as big data continued to grow and the amount of stored information increased every […].
Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machine learning models. Together they create a powerful, flexible, and scalable foundation for modern data applications. One of the standout features of Dataiku is its focus on collaboration.
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Airflow setup Apache Airflow is an open-source tool for orchestrating workflows and data processing pipelines. ", instance_type="ml.m5.xlarge",
Conventional ML development cycles take weeks to many months and requires sparse data science understanding and ML development skills. Business analysts’ ideas to use ML models often sit in prolonged backlogs because of data engineering and data science team’s bandwidth and datapreparation activities.
We exist in a diversified era of data tools up and down the stack – from storage to algorithm testing to stunning business insights. appeared first on DATAVERSITY.
Data Engineer: A data engineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models. They design datapipelines that integrate different datasets to ensure the quality, reliability, and scalability needed for AI applications.
In the following sections, we provide a detailed, step-by-step guide on implementing these new capabilities, covering everything from datapreparation to job submission and output analysis. This use case serves to illustrate the broader potential of the feature for handling diverse data processing tasks.
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. With AWS Glue custom connectors, it’s effortless to transfer data between Amazon S3 and other applications. Conclusion This solution allows for easy data integration to help expand cost-effective air quality monitoring.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring. Tayo Olajide is a seasoned Cloud Data Engineering generalist with over a decade of experience in architecting and implementing data solutions in cloud environments.
It includes a range of technologies—including machine learning frameworks, datapipelines, continuous integration / continuous deployment (CI/CD) systems, performance monitoring tools, version control systems and sometimes containerization tools (such as Kubernetes )—that optimize the ML lifecycle.
Continuous ML model retraining is one method to overcome this challenge by relearning from the most recent data. This requires not only well-designed features and ML architecture, but also datapreparation and ML pipelines that can automate the retraining process.
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. We set up an end-to-end Ray-based ML workflow, orchestrated using SageMaker Pipelines. This allows building end-to-end datapipelines and ML workflows on top of Ray.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Flyte Flyte is a platform for orchestrating ML pipelines at scale.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. In this blog, we’ll explore: Overview of Snowflake Stored Procedures & dbt Hooks.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Standard Chartered Bank’s Global Head of Technology, Santhosh Mahendiran , discussed the democratization of data across 3,500+ business users in 68 countries. We look at data as an asset, regardless of whether the use case is AML/fraud or new revenue. 3) Data professionals come in all shapes and forms.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Above all, this solution offers you a native Spark way to implement an end-to-end datapipeline from Amazon Redshift to SageMaker.
In this blog, I will cover: What is watsonx.ai? sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support. What capabilities are included in watsonx.ai?
In Nick Heudecker’s session on Driving Analytics Success with Data Engineering , we learned about the rise of the data engineer role – a jack-of-all-trades data maverick who resides either in the line of business or IT. DataRobot Data Prep. 3) The emergence of a new enterprise information management platform. Free Trial.
DataRobot now delivers both visual and code-centric datapreparation and datapipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Learn more about this groundbreaking release in this blog post, Advancing AI Cloud with Release 7.2.
In this blog post, we detail the steps you need to take to build and run a successful MLOps pipeline. MLOps (Machine Learning Operations) is the set of practices and techniques used to efficiently and automatically develop, test, deploy, and maintain ML models and applications and data in production. What is MLOps?
This blog was originally written by Erik Hyrkas and updated for 2024 by Justin Delisi This isn’t meant to be a technical how-to guide — most of those details are readily available via a quick Google search — but rather an opinionated review of key processes and potential approaches. Use with caution, and test before committing to using them.
Data must be available at the right moment for consumption and it might not be the easiest task to develop a strategy around the continuous pipelines and the integrated applications to set up your stack. Alteryx and the Snowflake Data Cloud offer a potential solution to this issue and can speed up your path to Analytics.
Because the machine learning lifecycle has many complex components that reach across multiple teams, it requires close-knit collaboration to ensure that hand-offs occur efficiently, from datapreparation and model training to model deployment and monitoring. How to use ML to automate the refining process into a cyclical ML process.
Data Scientists and Data Analysts have been using ChatGPT for Data Science to generate codes and answers rapidly. In the following blog, let’s look at how ChatGPT changes human function. The entire process involves cleaning, Merging and changing the data format. This data can help in building the project pipeline.
This blog post delves into the concepts of LLMOps and MLOps, explaining how and when to use each one. Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. LLMOps is MLOps for LLMs.
Under this category, tools with pre-built connectors for popular data sources and visual tools for data transformation are better choices. This setting ensures that the datapipeline adapts to changes in the Source schema according to user-specific needs. Another way is to add the Snowflake details through Fivetran.
In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting. Datapreparation, train and tune, deploy and monitor. We have datapipelines and datapreparation. But then there are preparations for domain-specific data.
In media and gaming: designing game storylines, scripts, auto-generated blogs, articles and tweets, and grammar corrections and text formatting. Datapreparation, train and tune, deploy and monitor. We have datapipelines and datapreparation. But then there are preparations for domain-specific data.
Summary: This blog provides a comprehensive roadmap for aspiring Azure Data Scientists, outlining the essential skills, certifications, and steps to build a successful career in Data Science using Microsoft Azure. DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling.
The Snowflake Data Cloud is a leading cloud data platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake. What is Snowpark?
Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently. In GPU Accelerated DataPreparation for Limit Order Book Modeling , the authors describe a GPU pipeline handling data collection, LOB pre-processing, data normalization, and batching into training samples.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Solution walkthrough (Scenario 1) The first step focuses on preparing the data for each data source for unified access.
Again, what goes on in this component is subjective to the data scientist’s initial (manual) datapreparation process, the problem, and the data used. Kedro Kedro is a Python library for building modular data science pipelines.
David: My technical background is in ETL, data extraction, data engineering and data analytics. I spent over a decade of my career developing large-scale datapipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems.
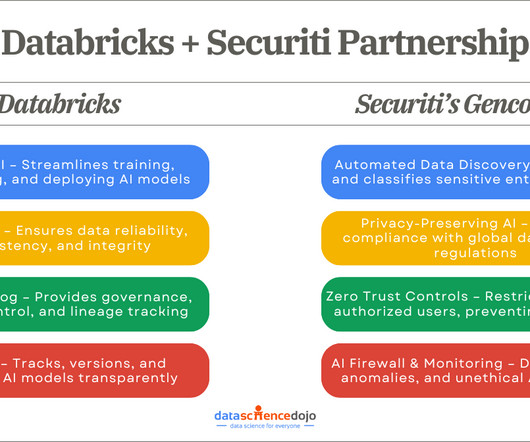
The combination of Databricks’ AI infrastructure and Securiti’s Gencore AI offers a security-first AI building framework, enabling enterprises to innovate while safeguarding sensitive data. Optimized DataPipelines for AI Readiness AI models are only as good as the data they process.
In this blog post, we bring insights for AI leaders Svetlana Sicular, Research VP, AI Strategy, Gartner and Yaron Haviv, co-founder and CTO, Iguazio (acquired by McKinsey). Automate productization, like auto-gen batching, real-time datapipelines, automated model training and CI/CD.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content