This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, datapipelines are necessary. appeared first on Analytics Vidhya.
Built into Data Wrangler, is the Chat for data prep option, which allows you to use natural language to explore, visualize, and transform your data in a conversational interface. Amazon QuickSight powers data-driven organizations with unified (BI) at hyperscale. A provisioned or serverless Amazon Redshift datawarehouse.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis.
The market for datawarehouses is booming. While there is a lot of discussion about the merits of datawarehouses, not enough discussion centers around data lakes. We talked about enterprise datawarehouses in the past, so let’s contrast them with data lakes. DataWarehouse.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with datapipelines and orderly, efficient datawarehouses. But as big data continued to grow and the amount of stored information increased every […].
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a datawarehouse.
Suppose you’re in charge of maintaining a large set of datapipelines from cloud storage or streaming data into a datawarehouse. How can you ensure that your data meets expectations after every transformation? That’s where data quality testing comes in.
The emergence of advanced data storage technologies, such as cloud computing, data hubs, and data lakes, makes us question the role of traditional datawarehouses in modern data architecture. Datawarehouses were first introduced in the […] The post Are DataWarehouses Still Relevant?
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
This adaptability allows organizations to align their data integration efforts with distinct operational needs, enabling them to maximize the value of their data across diverse applications and workflows. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse.
Ultimately, the goal of a CI/CD pipeline is to ensure the safe deployment of new changes to both Snowflake’s non-production and production environments. In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Amazon Redshift is the most popular cloud datawarehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Everyone can do it in a matter of minutes.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
How to scale AL and ML with built-in governance A fit-for-purpose data store built on an open lakehouse architecture allows you to scale AI and ML while providing built-in governance tools. A data store lets a business connect existing data with new data and discover new insights with real-time analytics and business intelligence.
The second is to provide a directed acyclic graph (DAG) for datapipelining and model building. If you use the filesystem as an intermediate data store, you can easily DAG-ify your data cleaning, feature extraction, model training, and evaluation. Teams that primarily access hosted data or assets (e.g.,
By analyzing datasets, data scientists can better understand their potential use in an algorithm or machine learning model. The data science lifecycle Data science is iterative, meaning data scientists form hypotheses and experiment to see if a desired outcome can be achieved using available data.
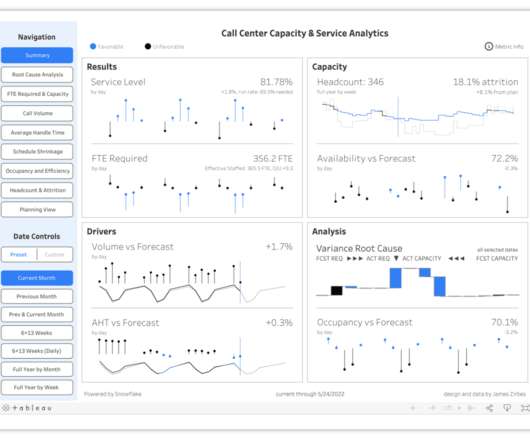
More and more businesses are looking to better leverage their outsourced call center data to make more data-driven decisions. To do this on your own, you would need to create a datawarehouse, optimize the reporting performance, and very clearly visualize the data. Another way to think of it is as Data Activation.
Practitioners and hands-on data users were thrilled to be there, and many connected as they shared their progress on their own data stack journeys. People were familiar with the value of a data catalog (and the growing need for data governance ), though many admitted to being somewhat behind on their journeys.
Introduction Dimensional modelling is crucial for organising data to enhance query performance and reporting efficiency. Effective schema design is essential for optimising data retrieval and analysis in data warehousing. Must Read Blogs: Exploring the Power of DataWarehouse Functionality.
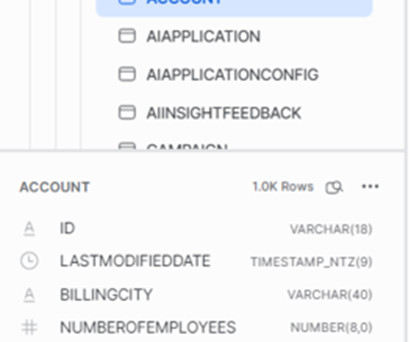
In order to unlock the potential of these tools, your CRM data must remain synced between Salesforce and Snowflake. Salesforce Sync Out offers an excellent and cost-efficient solution for seamlessly ingesting Salesforce data into Snowflake. Warehouse for loading the data (start with XSMALL or SMALL warehouses).
When you make it easier to work with events, other users like analysts and data engineers can start gaining real-time insights and work with datasets when it matters most. As a result, you reduce the skills barrier and increase your speed of data processing by preventing important information from getting stuck in a datawarehouse.
In this blog, I will cover: What is watsonx.ai? sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support. What capabilities are included in watsonx.ai?
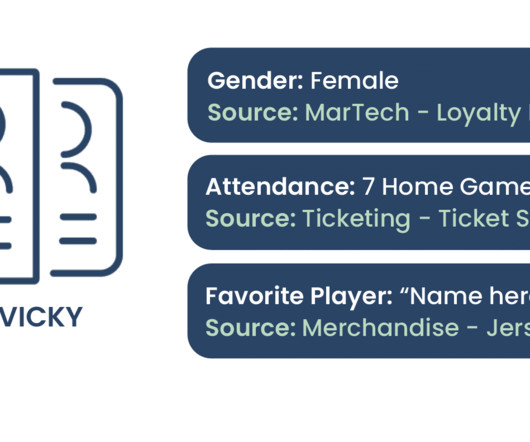
This blog was written by Sara Price and edited by Sunny Yan. In this blog, we’ll demonstrate how to utilize data to drive successful targeted and personalized campaigns for your fanbase to increase revenue, boost operational efficiency, and improve cross-departmental collaboration—all while providing an enriched fan experience.
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. What are Snowflake Dynamic Tables?
But doing so requires significant engineering, quality data and overcoming risks. In this blog post, we show all the elements and practices you need to to take to productize LLMs and generative AI. You can watch the full talk this blog post is based on, which took place at ODSC West 2023, here. This helps cleanse the data.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know. Cloud Platforms: AWS, Azure, Google Cloud, etc.
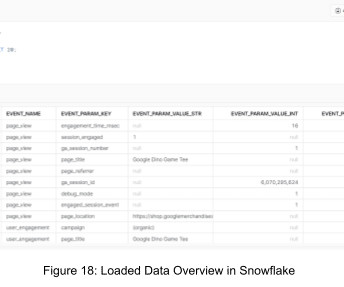
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your datawarehouse. Snowflake provides native ways for data ingestion.
At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration.
This blog was co-written by Sam Hall and Dakota Kelley In our previous blog , we discussed some ways Fivetran and dbt solve ELT for enterprise data consumption and analytics. As your data organization grows, the scalability of your data platform matters. These allow you to scale your pipelines quickly.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and data science use cases. What does a modern data architecture do for your business?
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data.
Let’s briefly look at the key components and their roles in this process: Azure Data Factory (ADF) : ADF will serve as our data orchestration and integration platform. It enables us to create, schedule, and monitor the datapipeline, ensuring seamless movement of data between the various sources and destinations.
If you are a data scientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that data scientists already have that are transferable to data engineering. In this blog post, we will discuss how you can become a data engineer if you are a data scientist.
Jeff Newburn is a Senior Software Engineering Manager leading the Data Engineering team at Logikcull – A Reveal Technology. He oversees the company’s data initiatives, including datawarehouses, visualizations, analytics, and machine learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content