This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
The blog post explains how the Internal Cloud Analytics team leveraged cloud resources like Code-Engine to improve, refine, and scale the datapipelines. Background One of the Analytics teams tasks is to load data from multiple sources and unify it into a data warehouse. Database size limits of 10GB.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
ChatGPT can also use Wolfram Language to create more complex visualizations, such as interactive charts and 3D models. Source: Stephen Wolfram Writings Read this blog to Master ChatGPT cheatsheet 2. This can be useful for data scientists who need to streamline their data science pipeline or automate repetitive tasks.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
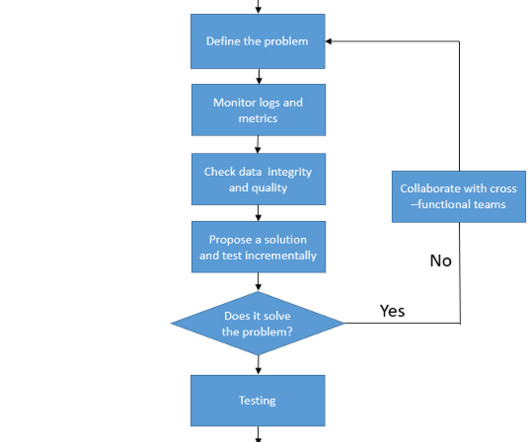
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
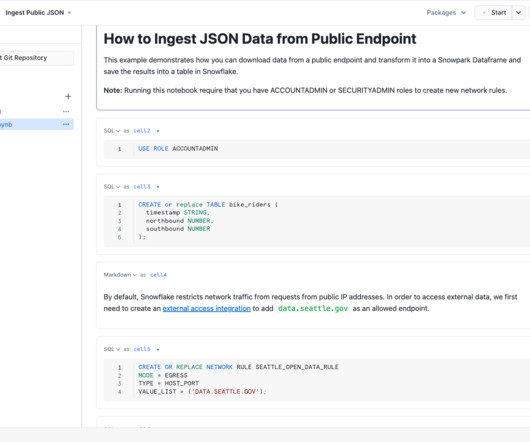
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
The development of a Machine Learning Model can be divided into three main stages: Building your ML datapipeline: This stage involves gathering data, cleaning it, and preparing it for modeling. For data scrapping a variety of sources, such as online databases, sensor data, or social media.
If you ever wonder how predictions and forecasts are made based on the raw data collected, stored, and processed in different formats by website feedback, customer surveys, and media analytics, this blog is for you. To learn more about visualizations, you can refer to one of our many blogs on data visualization for a glance.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
We also discuss different types of ETL pipelines for ML use cases and provide real-world examples of their use to help data engineers choose the right one. What is an ETL datapipeline in ML? Xoriant It is common to use ETL datapipeline and datapipeline interchangeably.
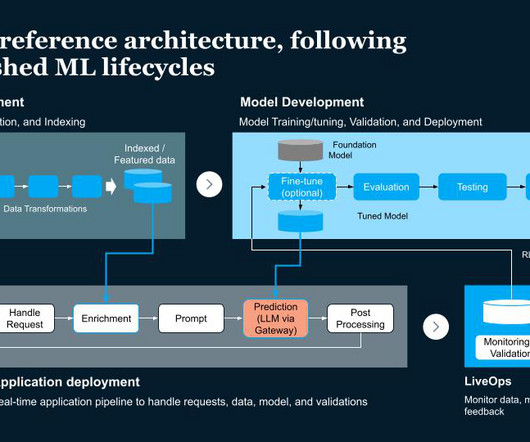
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
A lot of Open-Source ETL tools house a graphical interface for executing and designing DataPipelines. It can be used to manipulate, store, and analyze data of any structure. It generates Java code for the DataPipelines instead of running Pipeline configurations through an ETL Engine. Conclusion.
Data engineering is a crucial field that plays a vital role in the datapipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service.
Ultimately, the goal of a CI/CD pipeline is to ensure the safe deployment of new changes to both Snowflake’s non-production and production environments. In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms.
Database name : Enter dev. Database user : Enter awsuser. SageMaker Canvas integration with Amazon Redshift provides a unified environment for building and deploying machine learning models, allowing you to focus on creating value with your data rather than focusing on the technical details of building datapipelines or ML algorithms.
Summary: Time series databases (TSDBs) are built for efficiently storing and analyzing data that changes over time. This data, often from sensors or IoT devices, is typically collected at regular intervals. Buckle up as we navigate the intricacies of storing and analysing this dynamic data.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible. Or maybe you are interested in an individual data strategy ? Then get in touch with me!
However, a data lake functions for one specific company, the data warehouse, on the other hand, is fitted for another. This blog will reveal or show the difference between the data warehouse and the data lake. Data Warehouse. Engineers make use of data lakes in storing incoming data.
Advancements in data processing, storage, and analysis technologies power this transformation. In Data Science in a Cloud World, we explore how cloud computing has revolutionised Data Science. Key Features Tailored for Data Science These platforms offer specialised features to enhance productivity.
This adaptability allows organizations to align their data integration efforts with distinct operational needs, enabling them to maximize the value of their data across diverse applications and workflows. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
It also handles metadata, monitoring, and governance related to data management. Source: IBM Cloud Pak for Data Feature Computation Engine Users can transform batch, streaming, and real-time data into features Source: IBM Cloud Pak for Data To productionize a machine learning system, it is necessary to process new data continuously.
Before a bank can start the process of certifying a risk model, they first need to understand what data is being used and how it changes as it moves from a database to a model. The value of data lineage applies across all industries, but there are three key focuses when you consider it for banking use cases: 1.
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. It can help collect more data on the value of LLMs for your content translation use cases.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. Enter a user name, password, and database name. For this post, we add our restaurant data. Choose Add connection.
It integrates with Git and provides a Git-like interface for data versioning, allowing you to track changes, manage branches, and collaborate with data teams effectively. Dolt Dolt is an open-source relational database system built on Git. It could help you detect and prevent datapipeline failures, data drift, and anomalies.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. In this blog, we’ll explore: Overview of Snowflake Stored Procedures & dbt Hooks.
The 4 Gen AI Architecture Pipelines The four pipelines are: 1. The DataPipeline The datapipeline is the foundation of any AI system. It's responsible for collecting and ingesting the data from various external sources, processing it and managing the data.
The recent Snowflake Summit 2024 brought plenty of exciting upcoming features, GA announcements, strategic partnerships, and many more opportunities for customers on the Snowflake AI Data Cloud to innovate. If you are new to Snowflake Cortex AI, check out this introductory blog. schemas["my_schema"].tables.create(my_table)
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. Building datapipelines manually is an expensive and time-consuming process. Why Use Fivetran?
Best 8 data version control tools for 2023 (Source: DagsHub ) Introduction With business needs changing constantly and the growing size and structure of datasets, it becomes challenging to efficiently keep track of the changes made to the data, which leads to unfortunate scenarios such as inconsistencies and errors in data.
In this blog post, we introduce the joint MongoDB - Iguazio gen AI solution, which allows for the development and deployment of resilient and scalable gen AI applications. Iguazio capabilities: Structured and unstructured datapipelines for processing, versioning and loading documents.
Project Structure Creating Our Configuration File Creating Our DataPipeline Preprocessing Faces: Detection and Cropping Summary Citation Information Building a Dataset for Triplet Loss with Keras and TensorFlow In today’s tutorial, we will take the first step toward building our real-time face recognition application. The dataset.py
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud data warehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Data Engineer: A data engineer sets the foundation of building any generating AI app by preparing, cleaning and validating data required to train and deploy AI models. They design datapipelines that integrate different datasets to ensure the quality, reliability, and scalability needed for AI applications.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content