This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in data science and data engineering. They transform data into a consistent format for users to consume.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
The ETL process is defined as the movement of data from its source to destination storage (typically a Data Warehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow.
However, efficient use of ETLpipelines in ML can help make their life much easier. This article explores the importance of ETLpipelines in machine learning, a hands-on example of building ETLpipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Datapipelines are like insurance. ETL processes are constantly toiling away behind the scenes, doing heavy lifting to connect the sources of data from the real world with the warehouses and lakes that make the data useful. You only know they exist when something goes wrong.
Those who want to design universal datapipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each datapipeline platform embodies a unique philosophy, architectural design, and set of operations.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
Matillion has a Git integration for Matillion ETL with Git repository providers, which your company can use to leverage your development across teams and establish a more reliable environment. In this blog, you will learn how to set up your Matillion ETL to be integrated with Azure DevOps and used as a Git repository for your developments.
In the data analytics processes, choosing the right tools is crucial for ensuring efficiency and scalability. Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
If you ever wonder how predictions and forecasts are made based on the raw data collected, stored, and processed in different formats by website feedback, customer surveys, and media analytics, this blog is for you. To learn more about visualizations, you can refer to one of our many blogs on data visualization for a glance.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Matillion has a Git integration for Matillion ETL with Git repository providers, which can be used by your company to leverage your development across teams and establish a more reliable environment. What is Matillion ETL? To start, we’ll use the URL of your new BitBucket repository to point to the Matillion ETL platform later.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
This adaptability allows organizations to align their data integration efforts with distinct operational needs, enabling them to maximize the value of their data across diverse applications and workflows. This strategy helps organizations optimize data usage, expand into new markets, and increase revenue.
The answer lies in the data used to train these models and how that data is derived. In this blog post, we will explore the importance of lineage transparency for machine learning data sets and how it can help establish and ensure, trust and reliability in ML conclusions.
In this blog, we’ll show you how to boost your MLOps efficiency with 6 essential tools and platforms. we have Databricks which is an open-source, next-generation data management platform. It focuses on two aspects of data management: ETL (extract-transform-load) and data lifecycle management.
If the data sources are additionally expanded to include the machines of production and logistics, much more in-depth analyses for error detection and prevention as well as for optimizing the factory in its dynamic environment become possible. Or maybe you are interested in an individual data strategy ? Then get in touch with me!
To solve this problem, we had to design a strong datapipeline to create the ML features from the raw data and MLOps. Multiple data sources ODIN is an MMORPG where the game players interact with each other, and there are various events such as level-up, item purchase, and gold (game money) hunting.
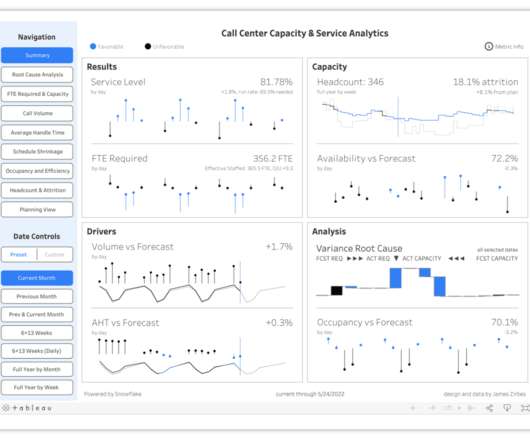
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. It can help collect more data on the value of LLMs for your content translation use cases.
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. It allows organizations to easily connect their disparate data sources without having to manage any infrastructure. Why Use Fivetran?
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Read this e-book on building strong governance foundations Why automated data lineage is crucial for success Data lineage , the process of tracking the flow of data over time from origin to destination within a datapipeline, is essential to understand the full lifecycle of data and ensure regulatory compliance.
Matillion has a GIT integration for Matillion ETL with GIT repository providers, which your company can use to leverage your development across teams and establish a more reliable environment. In this blog, you will learn how to set up your Matillion ETL to be integrated with GIT and used as a GIT repository for your development.
Best practices are a pivotal part of any software development, and data engineering is no exception. This ensures the datapipelines we create are robust, durable, and secure, providing the desired data to the organization effectively and consistently. What Are Matillion Jobs and Why Do They Matter?
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Related post MLOps Is an Extension of DevOps.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETLpipelines. He specializes in designing, building, and optimizing large-scale data solutions.
To do this on your own, you would need to create a data warehouse, optimize the reporting performance, and very clearly visualize the data. Or, all of this could be done – in a more simple and efficient manner – with the help of the Snowflake Data Cloud. Another way to think of it is as Data Activation.
How can a healthcare provider improve its data governance strategy, especially considering the ripple effect of small changes? Data lineage can help.With data lineage, your team establishes a strong data governance strategy, enabling them to gain full control of your healthcare datapipeline.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. The modern data stack is important because its suite of tools is designed to solve all of the core data challenges companies face.
If you are a data scientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that data scientists already have that are transferable to data engineering. In this blog post, we will discuss how you can become a data engineer if you are a data scientist.
This article was co-written by Mayank Singh & Ayush Kumar Singh Your organization’s datapipelines will inevitably run into issues, ranging from simple permission errors to significant network or infrastructure incidents. Configure your ETL tool to send emails to that address and invite people to join the Slack channel.
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. What do Data Science Bootcamps Offer? Data Engineering : Building and maintaining datapipelines, ETL (Extract, Transform, Load) processes, and data warehousing.
In July 2023, Matillion launched their fully SaaS platform called Data Productivity Cloud, aiming to create a future-ready, everyone-ready, and AI-ready environment that companies can easily adopt and start automating their datapipelines coding, low-coding, or even no-coding at all. Everyone can do it in a matter of minutes.
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. What is Matillion ETL? Whether you’re new to Matillion or just looking to improve your ETL skills, keep reading to learn more!
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. With that, let’s dive in What is Matillion ETL? Suppose we have the following insert statement: INSERT INTO orders_by_city SELECT o.id
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content