This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Businesses need to understand the trends in datapreparation to adapt and succeed. If you input poor-qualitydata into an AI system, the results will be poor. This principle highlights the need for careful datapreparation, ensuring that the input data is accurate, consistent, and relevant.
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
In fact, it’s been more than three decades of innovation in this market, resulting in the development of thousands of data tools and a global datapreparation tools market size that’s set […] The post Why Is DataQuality Still So Hard to Achieve? appeared first on DATAVERSITY.
By creating microsegments, businesses can be alerted to surprises, such as sudden deviations or emerging trends, empowering them to respond proactively and make data-driven decisions. Choose Segment ColumnData Explanation: Segmenting column dataprepares the system to generate SQL queries for distinctvalues.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
Generative AI (GenAI), specifically as it pertains to the public availability of large language models (LLMs), is a relatively new business tool, so it’s understandable that some might be skeptical of a technology that can generate professional documents or organize data instantly across multiple repositories.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. million per year.
With the increasing reliance on technology in our personal and professional lives, the volume of data generated daily is expected to grow. This rapid increase in data has created a need for ways to make sense of it all. The post DataPreparation and Raw Data in Machine Learning: Why They Matter appeared first on DATAVERSITY.
Additionally, these tools provide a comprehensive solution for faster workflows, enabling the following: Faster datapreparation – SageMaker Canvas has over 300 built-in transformations and the ability to use natural language that can accelerate datapreparation and making data ready for model building.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Aggregating and preparing large amounts of data is a critical part of ML workflow. Data scientists and data engineers use Apache Spark, Apache Hive, and Presto running on Amazon EMR for large-scale data processing. For Stack name , enter a name for the stack (for example, dw-emr-hive-blog ).
Choose Data Wrangler in the navigation pane. On the Import and prepare dropdown menu, choose Tabular. A new data flow is created on the Data Wrangler console. Choose Get data insights to identify potential dataquality issues and get recommendations. For Analysis name , enter a name.
As a result of this, your gen AI initiatives are built on a solid foundation of trusted, governed data. Bring in data engineers to assess dataquality and set up datapreparation processes This is when your data engineers use their expertise to evaluate dataquality and establish robust datapreparation processes.
In a single visual interface, you can complete each step of a datapreparation workflow: data selection, cleansing, exploration, visualization, and processing. Custom Spark commands can also expand the over 300 built-in data transformations. We start from creating a data flow.
To comprehend and transform raw, unstructured data for any specific business use, it typically takes a data scientist and specialized tools. As an alternative, datapreparation tools that provide self-service access to the information kept in data lakes are gaining popularity.
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to preparedata and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate datapreparation in machine learning (ML) workflows without writing any code.
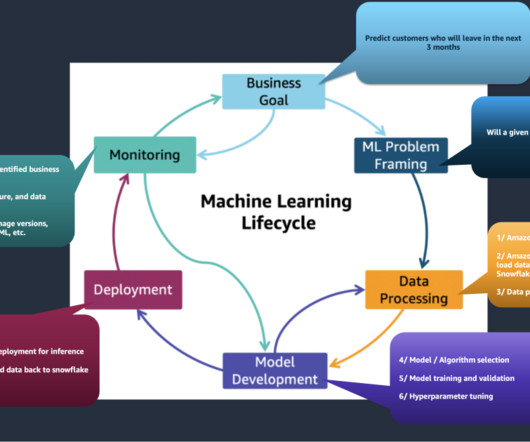
It includes processes for monitoring model performance, managing risks, ensuring dataquality, and maintaining transparency and accountability throughout the model’s lifecycle. Datapreparation For this example, you will use the South German Credit dataset open source dataset.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Noise refers to random errors or irrelevant data points that can adversely affect the modeling process.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Data monitoring tools help monitor the quality of the data.
Dimension reduction techniques can help reduce the size of your data while maintaining its information, resulting in quicker training times, lower cost, and potentially higher-performing models. Amazon SageMaker Data Wrangler is a purpose-built data aggregation and preparation tool for ML. Choose Create.
Increased operational efficiency benefits Reduced datapreparation time : OLAP datapreparation capabilities streamline data analysis processes, saving time and resources. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
Datapreparation, feature engineering, and feature impact analysis are techniques that are essential to model building. These activities play a crucial role in extracting meaningful insights from raw data and improving model performance, leading to more robust and insightful results.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
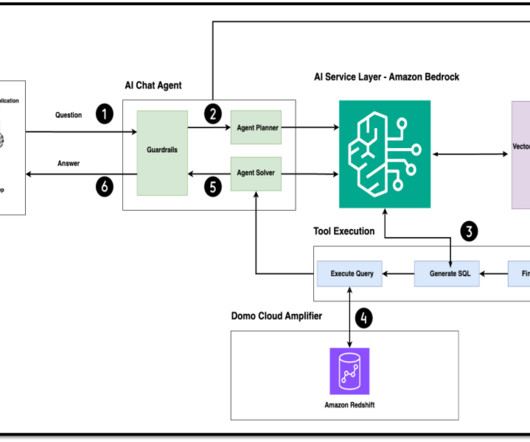
Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise. This can democratize data access and speed up analysis. powered by Amazon Bedrock Domo.AI
These activities are recorded in a model recipe , which is a series of steps towards datapreparation. This recipe is maintained throughout the lifecycle of a particular ML model from datapreparation to generating predictions.
Guided Navigation – Guided navigation provides intelligent suggestions, which guide correct usage of data. Behavioral intelligence, embedded in the catalog, learns from user behavior to enforce best practices through features like dataquality flags, which help folks stay compliant as they use data.
Exploring and Transforming Data. Good data curation and datapreparation leads to more practical, accurate model outcomes. Data aggregation such as from hourly to daily or from daily to weekly time steps may also be required. Perform dataquality checks and develop procedures for handling issues.
Supplier metadata is especially important for data acquired from external sources, informing about sources and subscription or licensing constraints. I’ll dive deeper into catalog metadata in an upcoming blog. What is a Data Catalog? What Does a Data Catalog Do? Benefits of a Data Catalog. Conclusion.
Businesses face significant hurdles when preparingdata for artificial intelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
We use a test datapreparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model.
The complexity of developing a bespoke classification machine learning model varies depending on a variety of aspects such as dataquality, algorithm, scalability, and domain knowledge, to mention a few. You can find more details about training datapreparation and understand the custom classifier metrics.
To achieve organization-wide data literacy, a new information management platform must emerge. This new platform will also serve many different use cases, including but not limited to analytics, application and data migrations, data monetization, and master data creation. . [1] DataRobot Data Prep. Free Trial.
We recently announced an integration with Trifacta to seamlessly integrate the Alation Data Catalog with self-service data prep applications to help you solve this issue. Bringing best of breed self-service datapreparation together with data cataloging is a natural combination.
Ensuring dataquality, governance, and security may slow down or stall ML projects. Conduct exploratory analysis and datapreparation. You may often select low-value use cases as proof of concept rather than solving a meaningful business or customer problem. Determine the ML algorithm, if known or possible.
For instance, telcos are early adopters of location intelligence – spatial analytics has been helping telecommunications firms by adding rich location-based context to their existing data sets for years. All that time spent on datapreparation has an opportunity cost associated with it.
Organizations will contend with problems ranging from data literacy — knowing how to use the data, analytical productivity — time to discovering the insight, dataquality and data availability. Subscribe to Alation's Blog. Get the latest data cataloging news and trends in your inbox.
Summary: Predictive analytics utilizes historical data, statistical algorithms, and Machine Learning techniques to forecast future outcomes. This blog explores the essential steps involved in analytics, including data collection, model building, and deployment. What is Predictive Analytics?
Never before have we had a centralized catalog that made finding data so easy.”. Alation’s robust platform helps users find and understand data in mere minutes — rather than months. Turns out, people much prefer innovating on creative projects over the stress of hunting for data. The Data Management Survey.
This is a joint blog with AWS and Philips. Data Management – Efficient data management is crucial for AI/ML platforms. Regulations in the healthcare industry call for especially rigorous data governance. Philips is a health technology company focused on improving people’s lives through meaningful innovation.
The data professionals deploy different techniques and operations to derive valuable information from the raw and unstructured data. The objective is to enhance the dataquality and prepare the data sets for the analysis. What is Data Manipulation?
In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning. We will also discuss best practices for training LLMs, such as using transfer learning, data augmentation, and ensembling methods.
The data value chain goes all the way from data capture and collection to reporting and sharing of information and actionable insights. As data doesn’t differentiate between industries, different sectors go through the same stages to gain value from it. Click to learn more about author Helena Schwenk.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content