This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In my previous articles Predictive Model Data Prep: An Art and Science and Data Prep Essentials for Automated Machine Learning, I shared foundational datapreparation tips to help you successfully. by Jen Underwood. Read More.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
Continuous ML model retraining is one method to overcome this challenge by relearning from the most recent data. This requires not only well-designed features and ML architecture, but also datapreparation and ML pipelines that can automate the retraining process. But there is still an engineering challenge.
With blogs, anyone can now write and distribute an article and with message boards anyone can post an advertisement. Business Intelligence used to require months of effort from BI and ETL teams. You used to be able to get those standards from your colleague in the BI/ETL team. Subscribe to Alation's Blog.
With SageMaker Unified Studio notebooks, you can use Python or Spark to interactively explore and visualize data, preparedata for analytics and ML, and train ML models. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources. Big Data Architect.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. These tools offer a wide range of functionalities to handle complex datapreparation tasks efficiently.
The solution addressed in this blog solves Afri-SET’s challenge and was ranked as the top 3 winning solutions. This post presents a solution that uses a generative artificial intelligence (AI) to standardize air quality data from low-cost sensors in Africa, specifically addressing the air quality data integration problem of low-cost sensors.
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. TR wanted to take advantage of AWS managed services where possible to simplify operations and reduce undifferentiated heavy lifting.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
Welcome to our AWS Redshift to the Snowflake Data Cloud migration blog! In this blog, we’ll walk you through the process of migrating your data from AWS Redshift to the Snowflake Data Cloud. One popular route is leveraging third-party ETL tools like Fivetran to ensure a smooth and successful migration.
Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment. This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects.
Benefits of the SageMaker and Data Cloud Einstein Studio integration Here’s how using SageMaker with Einstein Studio in Salesforce Data Cloud can help businesses: It provides the ability to connect custom and generative AI models to Einstein Studio for various use cases, such as lead conversion, case classification, and sentiment analysis.
Dataflows allow users to establish source connections and retrieve data, and subsequent data transformations can be conducted using the online Power Query Editor. In this blog, we will provide insights into the process of creating Dataflows and offer guidance on when to choose them to address real-world use cases effectively.
Data lakes, while useful in helping you to capture all of your data, are only the first step in extracting the value of that data. We recently announced an integration with Trifacta to seamlessly integrate the Alation Data Catalog with self-service data prep applications to help you solve this issue.
With the importance of data in various applications, there’s a need for effective solutions to organize, manage, and transfer data between systems with minimal complexity. While numerous ETL tools are available on the market, selecting the right one can be challenging.
However, most are only deployed over one data store (Hadoop or other various backends). In 2016, these will increasingly be deployed to query multiple data sources. The implication will be doing away with some (if not all) of the ETL work required to gather all of the data in one data warehouse.
Both tools serve distinct phases within the data analytics process, making their integration a highly advantageous proposition. In this blog, we will focus on integrating Power BI within KNIME for enhanced data analytics. This phase demands meticulous customization to optimize data for analysis.
In this blog, I will cover: What is watsonx.ai? sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support. What capabilities are included in watsonx.ai?
These teams are as follows: Advanced analytics team (data lake and data mesh) – Data engineers are responsible for preparing and ingesting data from multiple sources, building ETL (extract, transform, and load) pipelines to curate and catalog the data, and prepare the necessary historical data for the ML use cases.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed.
However, preparing raw data for ML training and evaluation is often a tedious and demanding task in terms of compute resources, time, and human effort. Datapreparation commonly needs to be integrated from different sources and deal with missing or noisy values, outliers, and so on.
The Snowflake Data Cloud is a leading cloud data platform that provides various features and services for data storage, processing, and analysis. A new feature that Snowflake offers is called Snowpark, which provides an intuitive library for querying and processing data at scale in Snowflake. What is Snowpark?
These connections are used by AWS Glue crawlers, jobs, and development endpoints to access various types of data stores. You can use these connections for both source and target data, and even reuse the same connection across multiple crawlers or extract, transform, and load (ETL) jobs.
Placing functions for plotting, data loading, datapreparation, and implementations of evaluation metrics in plain Python modules keeps a Jupyter notebook focused on the exploratory analysis | Source: Author Using SQL directly in Jupyter cells There are some cases in which data is not in memory (e.g.,
The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring. In this section, I will talk about best practices around building the Data Processing platform. How to set up an ML Platform in eCommerce?
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, data engineering and data analytics. An ETL process was built to take the CSV, find the corresponding text articles and load the data into a SQLite database.
IBM watsonx.data facilitates scalable analytics and AI endeavors by accommodating data from diverse sources, eliminating the need for migration or cataloging through open formats. This approach enables centralized access and sharing while minimizing extract, transform and load (ETL) processes and data duplication.
To handle the log data efficiently, raw logs were centralized into an Amazon Simple Storage Service (Amazon S3) bucket. An Amazon EventBridge schedule checked this bucket hourly for new files and triggered log transformation extract, transform, and load (ETL) pipelines built using AWS Glue and Apache Spark.
Jasper AI Content marketing teams swear by Jasper AI for generating blog posts, social media captions, and even ad copy in seconds. These AI-powered platforms enhance decision-making, automate reporting, and simplify complex data operations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










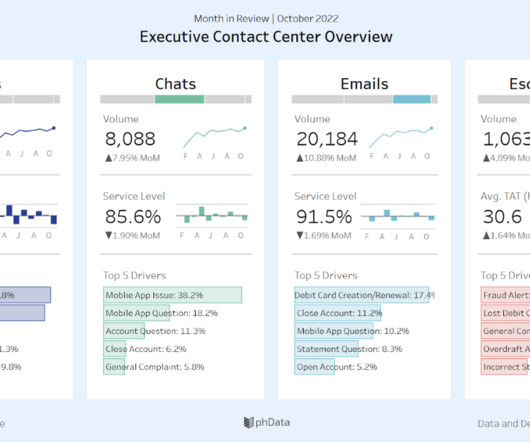


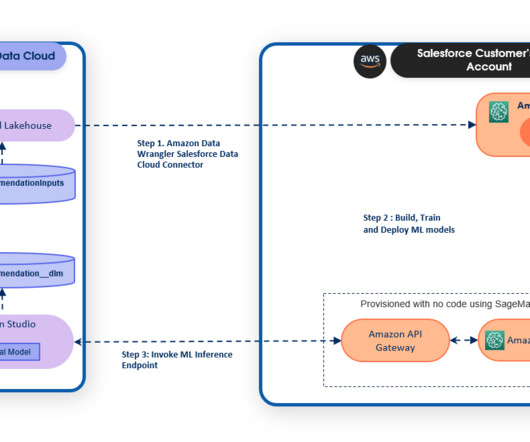








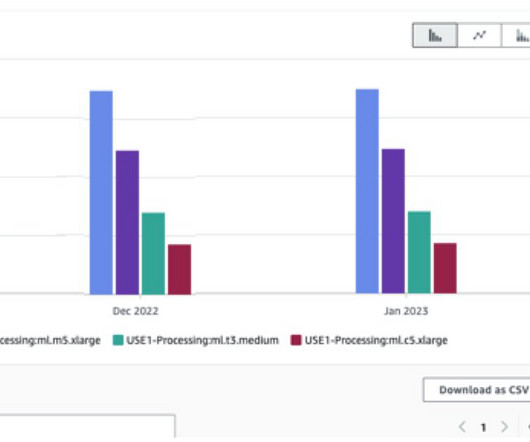















Let's personalize your content