This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
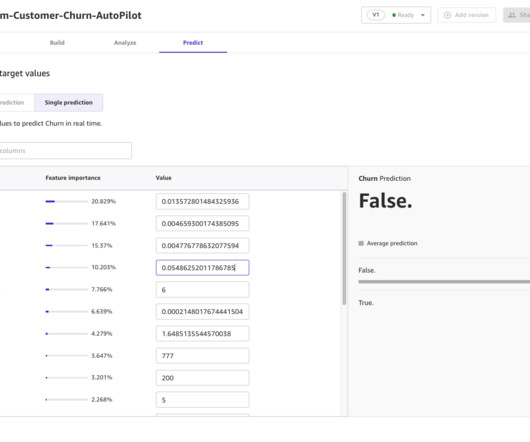
Datapreparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive datapreparation capabilities powered by Amazon SageMaker Data Wrangler.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. Charles holds an MS in Supply Chain Management and a PhD in Data Science.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
It offers industry-leading scalability, data availability, security, and performance. SageMaker Canvas now supports comprehensive datapreparation capabilities powered by SageMaker Data Wrangler. We also demonstrate using the chat for data prep feature in SageMaker Canvas to analyze the data and visualize your findings.
Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machine learning models. Together they create a powerful, flexible, and scalable foundation for modern data applications. One of the standout features of Dataiku is its focus on collaboration.
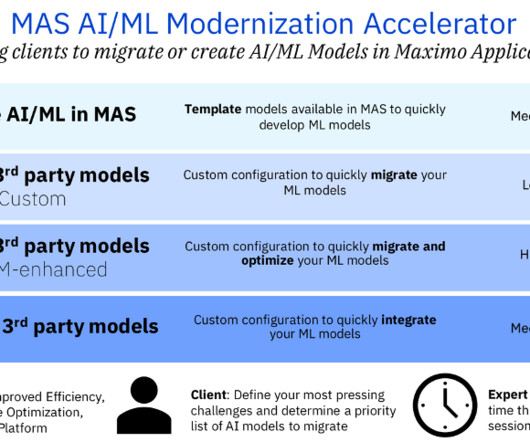
Many businesses are in different stages of their MAS AI/ML modernization journey. In this blog, we delve into 4 different “on-ramps” we created in a MAS Accelerator to offer a straightforward path to harnessing the power of AI in MAS, wherever you may be on your MAS AI/ML modernization journey.
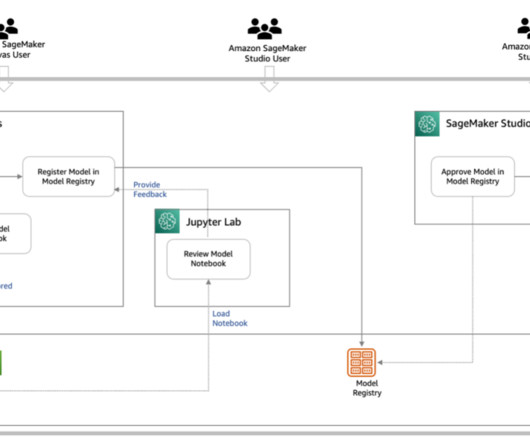
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
We’re excited to announce the release of SageMaker Core , a new Python SDK from Amazon SageMaker designed to offer an object-oriented approach for managing the machine learning (ML) lifecycle. With SageMaker Core, managing ML workloads on SageMaker becomes simpler and more efficient. and above.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
Datapreparation isn’t just a part of the ML engineering process — it’s the heart of it. Photo by Myriam Jessier on Unsplash To set the stage, let’s examine the nuances between research-phase data and production-phase data. Data is a key differentiator in ML projects (more on this in my blog post below).
The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. This is where the AWS suite of low-code and no-code ML services becomes an essential tool.
Artificial intelligence (AI) and machine learning (ML) have seen widespread adoption across enterprise and government organizations. Processing unstructured data has become easier with the advancements in natural language processing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend.
Machine learning (ML) helps organizations generate revenue, reduce costs, mitigate risk, drive efficiencies, and improve quality by optimizing core business functions across multiple business units such as marketing, manufacturing, operations, sales, finance, and customer service. Let’s assume the role of a data scientist.
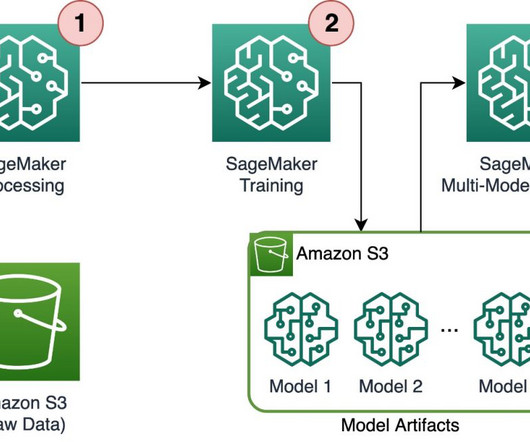
As machine learning (ML) becomes increasingly prevalent in a wide range of industries, organizations are finding the need to train and serve large numbers of ML models to meet the diverse needs of their customers. Here, the checkpoints need to be saved in a pre-specified location, with the default being /opt/ml/checkpoints.
Machine learning operations (MLOps) are a set of practices that automate and simplify machine learning (ML) workflows and deployments. AWS published Guidance for Optimizing MLOps for Sustainability on AWS to help customers maximize utilization and minimize waste in their ML workloads.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
Have an S3 bucket to store your dataprepared for batch inference. Have an AWS Identity and Access Management (IAM) role for batch inference with a trust policy and Amazon S3 access (read access to the folder containing input data and write access to the folder storing output data).
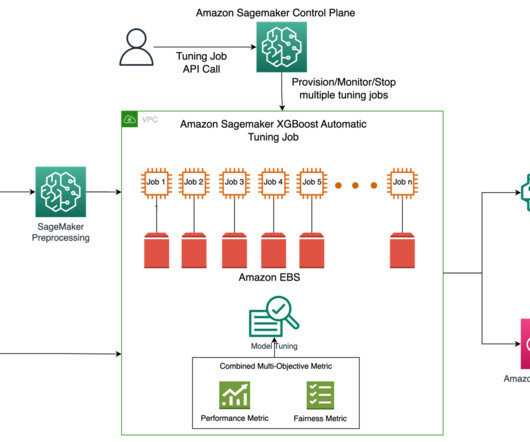
Model tuning is the experimental process of finding the optimal parameters and configurations for a machine learning (ML) model that result in the best possible desired outcome with a validation dataset. Single objective optimization with a performance metric is the most common approach for tuning ML models.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
jpg", "prompt": "Which part of Virginia is this letter sent from", "completion": "Richmond"} SageMaker JumpStart SageMaker JumpStart is a powerful feature within the SageMaker machine learning (ML) environment that provides ML practitioners a comprehensive hub of publicly available and proprietary foundation models (FMs).
In this comprehensive guide, we’ll explore the key concepts, challenges, and best practices for ML model packaging, including the different types of packaging formats, techniques, and frameworks. Best practices for ml model packaging Here is how you can package a model efficiently.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from datapreparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. SageMaker Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity.
Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
Second, because data, code, and other development artifacts like machine learning (ML) models are stored within different services, it can be cumbersome for users to understand how they interact with each other and make changes. With the SQL editor, you can query data lakes, databases, data warehouses, and federated data sources.
It is a powerful tool that can be used to automate many of the tasks involved in data analysis, and it can also help businesses to discover new insights from their data. It has a wide range of machine 6: Tableau Tableau is a data visualization software platform that can be used to create interactive dashboards and reports.
Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and preparedata for machine learning (ML) from weeks to minutes in Amazon SageMaker Studio. Starting today, you can connect to Amazon EMR Hive as a big data query engine to bring in large datasets for ML. LDAP No Auth Choose Next.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
Launched in 2019, Amazon SageMaker Studio provides one place for all end-to-end machine learning (ML) workflows, from datapreparation, building and experimentation, training, hosting, and monitoring. About the Authors Mair Hasco is an AI/ML Specialist for Amazon SageMaker Studio. Get started on SageMaker Studio here.
Best practices for datapreparation The quality and structure of your training data fundamentally determine the success of fine-tuning. Our experiments revealed several critical insights for preparing effective multimodal datasets: Data structure You should use a single image per example rather than multiple images.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring. AI life-cycle tools are essential to productize AI/ML solutions.
Being one of the largest AWS customers, Twilio engages with data and artificial intelligence and machine learning (AI/ML) services to run their daily workloads. ML models don’t operate in isolation. This necessitates considering the entire ML lifecycle during design and development.
MPII is using a machine learning (ML) bid optimization engine to inform upstream decision-making processes in power asset management and trading. This solution helps market analysts design and perform data-driven bidding strategies optimized for power asset profitability. Data comes from disparate sources in a number of formats.
For readers who work in ML/AI, it’s well understood that machine learning models prefer feature vectors of numerical information. In this blog, we propose GraphReduce as an abstraction for these problems. Datapreparation happens at the entity-level first so errors and anomalies don’t make their way into the aggregated dataset.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content