This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields. These blogs stand out as they make deep, complex topics easy to understand for a broader audience.
NLP with Transformers introduces readers to transformer architecture for naturallanguageprocessing, offering practical guidance on using Hugging Face for tasks like text classification. If you want… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter.
Development to production workflow LLMs Large Language Models (LLMs) represent a novel category of NaturalLanguageProcessing (NLP) models that have significantly surpassed previous benchmarks across a wide spectrum of tasks, including open question-answering, summarization, and the execution of nearly arbitrary instructions.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Processing unstructured data has become easier with the advancements in naturallanguageprocessing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend. We will be using the Data-Preparation notebook. Choose the notebook Data-Preparation.ipynb.
Fine-tuning is a powerful approach in naturallanguageprocessing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. This process involves updating the model’s weights to improve its performance on targeted applications.
TensorFlow First on the AI tool list, we have TensorFlow which is an open-source software library for numerical computation using data flow graphs. It is used for machine learning, naturallanguageprocessing, and computer vision tasks. Wrapping up In this blog post, we have reviewed the top 6 AI tools for data analysis.
It provides a common framework for assessing the performance of naturallanguageprocessing (NLP)-based retrieval models, making it straightforward to compare different approaches. It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring.
Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for naturallanguageprocessing (NLP) tasks. In this section, we describe the major steps involved in datapreparation and model training.
As AI adoption continues to accelerate, developing efficient mechanisms for digesting and learning from unstructured data becomes even more critical in the future. This could involve better preprocessing tools, semi-supervised learning techniques, and advances in naturallanguageprocessing. Choose your domain.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview.
Genomic language models are a new and exciting field in the application of large language models to challenges in genomics. In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud.
Data preprocessing is a fundamental and essential step in the field of sentiment analysis, a prominent branch of naturallanguageprocessing (NLP). These tools offer a wide range of functionalities to handle complex datapreparation tasks efficiently.
SageMaker Studio is an IDE that offers a web-based visual interface for performing the ML development steps, from datapreparation to model building, training, and deployment. In this section, we cover how to discover these models in SageMaker Studio. He focuses on developing scalable machine learning algorithms.
However, while spend-based commodity-class level data presents an opportunity to help address the difficulties associates with Scope 3 emissions accounting, manually mapping high volumes of financial ledger entries to commodity classes is an exceptionally time-consuming, error-prone process. This is where LLMs come into play.
Given this mission, Talent.com and AWS joined forces to create a job recommendation engine using state-of-the-art naturallanguageprocessing (NLP) and deep learning model training techniques with Amazon SageMaker to provide an unrivaled experience for job seekers.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. You now run the datapreparation step in the notebook. In this post, we show how straightforward it is to build an email spam detector using Amazon SageMaker.
Solution overview This solution uses Amazon Comprehend and SageMaker Data Wrangler to automatically redact PII data from a sample dataset. Amazon Comprehend is a naturallanguageprocessing (NLP) service that uses ML to uncover insights and relationships in unstructured data, with no managing infrastructure or ML experience required.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
Primary activities AIOps relies on big data-driven analytics , ML algorithms and other AI-driven techniques to continuously track and analyze ITOps data. The process includes activities such as anomaly detection, event correlation, predictive analytics, automated root cause analysis and naturallanguageprocessing (NLP).
The Fine-tuning Workflow with LangChain DataPreparation Customize your dataset to fine-tune an LLM for your specific task. LangChain facilitates applications that generate creative and contextually relevant content, like blog articles, product descriptions, and social media posts.
By implementing a modern naturallanguageprocessing (NLP) model, the response process has been shaped much more efficiently, and waiting time for clients has been reduced tremendously. In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail.
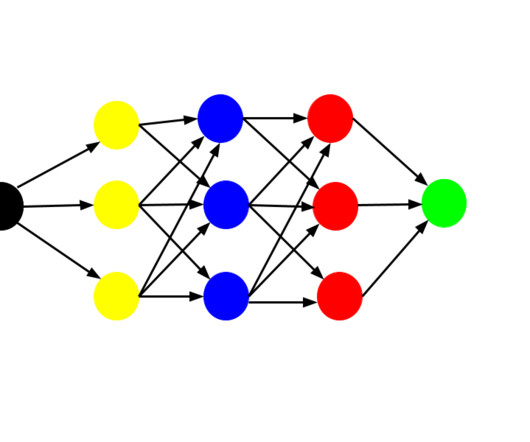
They consist of interconnected nodes that learn complex patterns in data. Different types of neural networks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, NaturalLanguageProcessing, and sequence modelling.
With the addition of forecasting, you can now access end-to-end ML capabilities for a broad set of model types—including regression, multi-class classification, computer vision (CV), naturallanguageprocessing (NLP), and generative artificial intelligence (AI)—within the unified user-friendly platform of SageMaker Canvas.
While both these tools are powerful on their own, their combined strength offers a comprehensive solution for data analytics. In this blog post, we will show you how to leverage KNIME’s Tableau Integration Extension and discuss the benefits of using KNIME for datapreparation before visualization in Tableau.
In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 Software Development Kit (SDK). SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment.
LLMs are one of the most exciting advancements in naturallanguageprocessing (NLP). We will explore how to better understand the data that these models are trained on, and how to evaluate and optimize them for real-world use. LLMs rely on vast amounts of text data to learn patterns and generate coherent text.
Large language models (LLMs) have achieved remarkable success in various naturallanguageprocessing (NLP) tasks, but they may not always generalize well to specific domains or tasks. This is where MLflow can help streamline the ML lifecycle, from datapreparation to model deployment.
An intelligent document processing (IDP) project usually combines optical character recognition (OCR) and naturallanguageprocessing (NLP) to read and understand a document and extract specific entities or phrases. His focus is naturallanguageprocessing and computer vision.
Learn how Data Scientists use ChatGPT, a potent OpenAI language model, to improve their operations. ChatGPT is essential in the domains of naturallanguageprocessing, modeling, data analysis, data cleaning, and data visualization.
In this blog, I will cover: What is watsonx.ai? This allows users to accomplish different NaturalLanguageProcessing (NLP) functional tasks and take advantage of IBM vetted pre-trained open-source foundation models. Encoder-decoder and decoder-only large language models are available in the Prompt Lab today.
It can be difficult to find insights from this data, particularly if efforts are needed to classify, tag, or label it. Amazon Comprehend is a natural-languageprocessing (NLP) service that uses machine learning to uncover valuable insights and connections in text. Now, we encourage you, our readers, to test these tools.
Amazon Comprehend is a managed AI service that uses naturallanguageprocessing (NLP) with ready-made intelligence to extract insights about the content of documents. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
First and foremost, Studio makes it easier to share notebook assets across a large team of data scientists like the one at Boomi. Boomi’s analysts were free to use SageMaker Data Wrangler for datapreparation tasks, while Boomi’s data scientists could continue to use Jupyter notebooks.
With the introduction of EMR Serverless support for Apache Livy endpoints , SageMaker Studio users can now seamlessly integrate their Jupyter notebooks running sparkmagic kernels with the powerful dataprocessing capabilities of EMR Serverless. In his free time, he enjoys playing chess and traveling. You can find Pranav on LinkedIn.
This blog post is co-written with Tuana Çelik from deepset. With the advent of large language models (LLMs), we can implement conversational experiences in providing the results to users. Often, to get an NLP application working for production use cases, we end up having to think about datapreparation and cleaning.
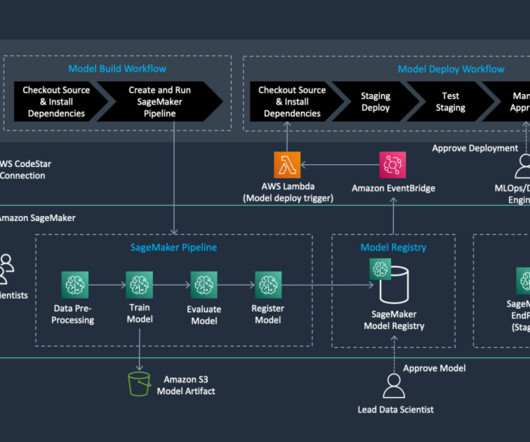
We create an automated model build pipeline that includes steps for datapreparation, model training, model evaluation, and registration of the trained model in the SageMaker Model Registry. Romina’s areas of interest are naturallanguageprocessing, large language models, and MLOps.
Yet most FP&A analysts & management spend the vast majority of their time on that preliminary work—reconciliation, analysis, cleansing, and standardization, which I’ll refer to here collectively as datapreparation. That’s because Microsoft Excel is still the go-to tool for performing all of that data prep. The easy way.
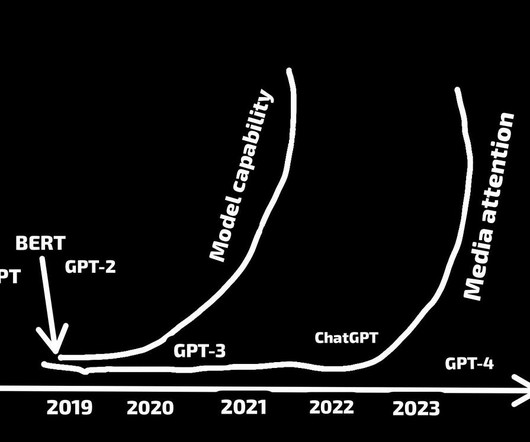
Large language models have emerged as ground-breaking technologies with revolutionary potential in the fast-developing fields of artificial intelligence (AI) and naturallanguageprocessing (NLP). The way we create and manage AI-powered products is evolving because of LLMs. ." BERT and GPT are examples.
PyTorch For tasks like computer vision and naturallanguageprocessing, Using the Torch library as its foundation, PyTorch is a free and open-source machine learning framework that comes in handy. spaCy When it comes to advanced and intermedeate naturallanguageprocessing, spaCy is an open-source library workin in Python.
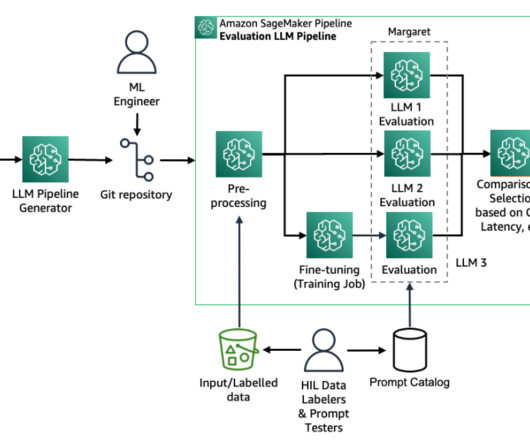
They have deep end-to-end ML and naturallanguageprocessing (NLP) expertise and data science skills, and massive data labeler and editor teams. Additions are required in historical datapreparation, model evaluation, and monitoring. The following figure illustrates their journey.
SageMaker pipeline steps The pipeline is divided into the following steps: Train and test datapreparation – Terabytes of raw data are copied to an S3 bucket, processed using AWS Glue jobs for Spark processing, resulting in data structured and formatted for compatibility.
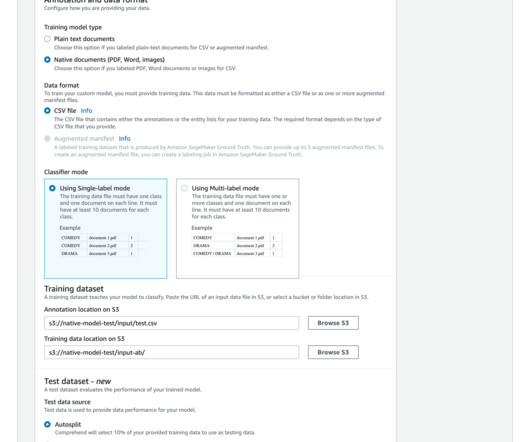
At AWS re:Invent 2022, Amazon Comprehend , a naturallanguageprocessing (NLP) service that uses machine learning (ML) to discover insights from text, launched support for native document types. This new feature gave you the ability to classify documents in native formats (PDF, TIFF, JPG, PNG, DOCX) using Amazon Comprehend.
Training a Convolutional Neural Networks Training a convolutional neural network (CNN) involves several steps: DataPreparation : This method entails gathering, cleaning, and preparing the data that will be utilized to train the CNN. The data should be split into training, validation, and testing sets.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content