This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
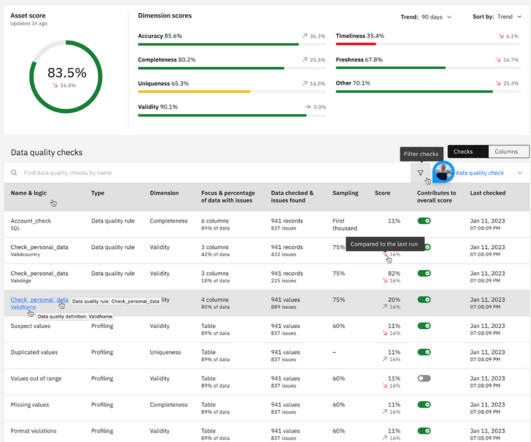
Dataquality issues continue to plague financial services organizations, resulting in costly fines, operational inefficiencies, and damage to reputations. Key Examples of DataQuality Failures — […]
Summary: Datasilos are isolated data repositories within organisations that hinder access and collaboration. Eliminating datasilos enhances decision-making, improves operational efficiency, and fosters a collaborative environment, ultimately leading to better customer experiences and business outcomes.
In fact, it’s been more than three decades of innovation in this market, resulting in the development of thousands of data tools and a global data preparation tools market size that’s set […] The post Why Is DataQuality Still So Hard to Achieve? appeared first on DATAVERSITY.
The key to being truly data-driven is having access to accurate, complete, and reliable data. In fact, Gartner recently found that organizations believe […] The post How to Assess DataQuality Readiness for Modern Data Pipelines appeared first on DATAVERSITY.
In this blog, we explore how the introduction of SQL Asset Type enhances the metadata enrichment process within the IBM Knowledge Catalog , enhancing data governance and consumption. This approach could be time-consuming and resource-intensive, with a significant portion of the analysis focusing on irrelevant data.
Poor dataquality is one of the top barriers faced by organizations aspiring to be more data-driven. Ill-timed business decisions and misinformed business processes, missed revenue opportunities, failed business initiatives and complex data systems can all stem from dataquality issues.
Alation and Soda are excited to announce a new partnership, which will bring powerful data-quality capabilities into the data catalog. Soda’s data observability platform empowers data teams to discover and collaboratively resolve data issues quickly. Does the quality of this dataset meet user expectations?
The Data Rants video blog series begins with host Scott Taylor “The Data Whisperer.” The post The 12 Days of Data Management appeared first on DATAVERSITY. Click to learn more about author Scott Taylor.
Generating actionable insights across growing data volumes and disconnected datasilos is becoming increasingly challenging for organizations. Working across data islands leads to siloed thinking and the inability to implement critical business initiatives such as Customer, Product, or Asset 360.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges, specifically as the growth of data spans multiple formats: structured, semistructured and unstructured.
Simply put, data governance is the process of establishing policies, procedures, and standards for managing data within an organization. It involves defining roles and responsibilities, setting standards for dataquality, and ensuring that data is being used in a way that is consistent with the organization’s goals and values.
Much of his work focuses on democratising data and breaking down datasilos to drive better business outcomes. In this blog, Chris shows how Snowflake and Alation together accelerate data culture. He shows how Texas Mutual Insurance Company has embraced data governance to build trust in data.
At the same time, implementing a data governance framework poses some challenges, such as dataquality issues, datasilos security and privacy concerns. Dataquality issues Positive business decisions and outcomes rely on trustworthy, high-qualitydata.
It’s common for enterprises to run into challenges such as lack of data visibility, problems with data security, and low DataQuality. But despite the dangers of poor data ethics and management, many enterprises are failing to take the steps they need to ensure qualityData Governance.
It’s on Data Governance Leaders to identify the issues with the business process that causes users to act in these ways. Inconsistencies in expectations can create enormous negative issues regarding dataquality and governance. Roadblock #3: Silos Breed Misunderstanding. Picking the Right Data Governance Tools.
The Data Rants video blog series begins with host Scott Taylor “The Data Whisperer.” The post The Little Red Data Hen – A Cautionary Tale appeared first on DATAVERSITY. Click to learn more about author Scott Taylor.
This is a guest blog post written by Nitin Kumar, a Lead Data Scientist at T and T Consulting Services, Inc. Duration of data informs on long-term variations and patterns in the dataset that would otherwise go undetected and lead to biased and ill-informed predictions. Much of this work comes down to the data.”
As a proud member of the Connect with Confluent program , we help organizations going through digital transformation and IT infrastructure modernization break down datasilos and power their streaming data pipelines with trusted data.
In our last blog , we introduced Data Governance: what it is and why it is so important. In this blog, we will explore the challenges that organizations face as they start their governance journey. Organizations have long struggled with data management and understanding data in a complex and ever-growing data landscape.
Organizations seeking responsive and sustainable solutions to their growing data challenges increasingly lean on architectural approaches such as data mesh to deliver information quickly and efficiently.
Access to high-qualitydata can help organizations start successful products, defend against digital attacks, understand failures and pivot toward success. Emerging technologies and trends, such as machine learning (ML), artificial intelligence (AI), automation and generative AI (gen AI), all rely on good dataquality.
Open is creating a foundation for storing, managing, integrating and accessing data built on open and interoperable capabilities that span hybrid cloud deployments, data storage, data formats, query engines, governance and metadata. Effective dataquality management is crucial to mitigating these risks.
It introduced Robotic Process Automation (RPA) in pilot scenarios to swiftly enhance process efficiency and quality, integrating system resources cost-effectively and breaking datasilos. The company also recognized data issues and introduced measures to ensure continuous and effective dataquality oversight.
A data mesh is a decentralized approach to data architecture that’s been gaining traction as a solution to the challenges posed by large and complex data ecosystems. It’s all about breaking down datasilos, empowering domain teams to take ownership of their data, and fostering a culture of data collaboration.
But, this data is often stored in disparate systems and formats. Here comes the role of Data Mining. Read this blog to know more about Data Integration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Thereby, improving dataquality and consistency.
Organizations require reliable data for robust AI models and accurate insights, yet the current technology landscape presents unparalleled dataquality challenges. This situation will exacerbate datasilos, increase costs and complicate the governance of AI and data workloads.
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. This phase is crucial for enhancing dataquality and preparing it for analysis.
While this industry has used data and analytics for a long time, many large travel organizations still struggle with datasilos , which prevent them from gaining the most value from their data. What is big data in the travel and tourism industry? Curious to see Alation in action?
What is data fabric Data fabric is a data management architecture that allows you to break down datasilos, improve efficiencies, and accelerate access for users. It provides a unified and consistent data infrastructure across distributed environments, accelerating analytics and decision-making.
These cover managing and protecting cloud data, migrating it securely to the cloud, and harnessing automation and technology for optimised data management. Central to this is a uniform technology architecture, where individuals can access and interpret data for organisational benefit.
For instance, telcos are early adopters of location intelligence – spatial analytics has been helping telecommunications firms by adding rich location-based context to their existing data sets for years.
The software provides an integrated and unified platform for disparate business processes such as supply chain management and human resources , providing a holistic view of an organization’s operations and breaking down datasilos. Dataquality: Ensure migrated data is clean, correct and current.
Businesses face significant hurdles when preparing data for artificial intelligence (AI) applications. The existence of datasilos and duplication, alongside apprehensions regarding dataquality, presents a multifaceted environment for organizations to manage.
The rapid growth of data continues to proceed unabated and is now accompanied by not only the issue of siloeddata but a plethora of different repositories across numerous clouds. From there, it can be easily accessed via dashboards by data consumers or those building into a data product.
In this blog, we aim to demystify generative AI for manufacturing companies , offering a clear path to implementing generative AI use cases in your business. Integration With Existing Systems AI needs a lot of data to give beneficial results, probably from many different sources and systems.
In the realm of Data Intelligence, the blog demystifies its significance, components, and distinctions from Data Information, Artificial Intelligence, and Data Analysis. ” This notion underscores the pivotal role of data in today’s dynamic landscape. What is Data Intelligence in Data Science?
According to Gartner, data fabric is an architecture and set of data services that provides consistent functionality across a variety of environments, from on-premises to the cloud. Data fabric simplifies and integrates on-premises and cloud Data Management by accelerating digital transformation.
In the era of digital transformation, data has become the new oil. Businesses increasingly rely on real-time data to make informed decisions, improve customer experiences, and gain a competitive edge. However, managing and handling real-time data can be challenging due to its volume, velocity, and variety.
Falling into the wrong hands can lead to the illicit use of this data. Hence, adopting a Data Platform that assures complete data security and governance for an organization becomes paramount. In this blog, we are going to discuss more on What are Data platforms & Data Governance.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a data lake, and building an API to extract needed information isn’t working. The post Why Graph Databases Are an Essential Choice for Master Data Management appeared first on DATAVERSITY.
What are the new data governance trends, “Data Fabric” and “Data Mesh”? I decided to write a series of blogs on current topics: the elements of data governance that I have been thinking about, reading, and following for a while. What is Data Mesh? Even though the titles are new, the ideas are not really new.
Information about customers is likely scattered across an assortment of applications and devices ranging from your customer relationship management system to logs from customer-facing applications, […] The post End the Tyranny of Disaggregated Data appeared first on DATAVERSITY. You need to find out why and fast.
This centralization streamlines data access, facilitating more efficient analysis and reducing the challenges associated with siloed information. With all data in one place, businesses can break down datasilos and gain holistic insights.
Summary: Clinical decision support systems (CDSS) are transforming healthcare by providing clinicians with real-time patient data and clinical knowledge at the point of care. This blog explores the power of CDSS in real-world scenarios. Here, we have highlighted the concerning issues like usability, dataquality, and clinician trust.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content