This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can now register machine learning (ML) models in Amazon SageMaker Model Registry with Amazon SageMaker Model Cards , making it straightforward to manage governance information for specific model versions directly in SageMaker Model Registry in just a few clicks.
Modern businesses are embracing machine learning (ML) models to gain a competitive edge. Hence, improving the overall efficiency of the business and allow them to make data-driven decisions. Deploying ML models in their day-to-day processes allows businesses to adopt and integrate AI-powered solutions into their businesses.
With the increasing use of large models, requiring a large number of accelerated compute instances, observability plays a critical role in ML operations, empowering you to improve performance, diagnose and fix failures, and optimize resource utilization. This data makes sure models are being trained smoothly and reliably.
Data preparation is a crucial step in any machine learning (ML) workflow, yet it often involves tedious and time-consuming tasks. Amazon SageMaker Canvas now supports comprehensive data preparation capabilities powered by Amazon SageMaker Data Wrangler. Now you have a balanced target column.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
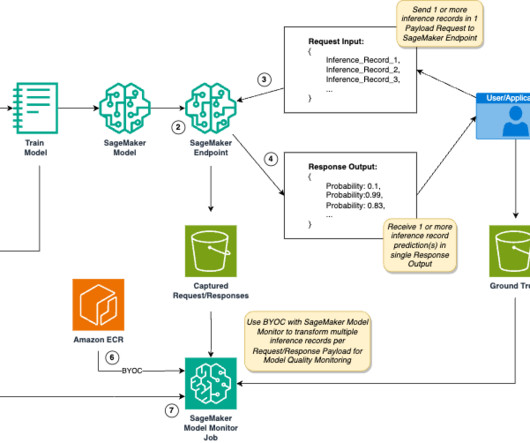
Real-world applications vary in inference requirements for their artificial intelligence and machine learning (AI/ML) solutions to optimize performance and reduce costs. SageMaker Model Monitor monitors the quality of SageMaker ML models in production.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
Do you need help to move your organization’s Machine Learning (ML) journey from pilot to production? Most executives think ML can apply to any business decision, but on average only half of the ML projects make it to production. Challenges Customers may face several challenges when implementing machine learning (ML) solutions.
Edited Photo by Taylor Vick on Unsplash In ML engineering, dataquality isn’t just critical — it’s foundational. Since 2011, Peter Norvig’s words underscore the power of a data-centric approach in machine learning. Yet, this perspective often gets sidelined and there was never a consensus in the ML community about it.
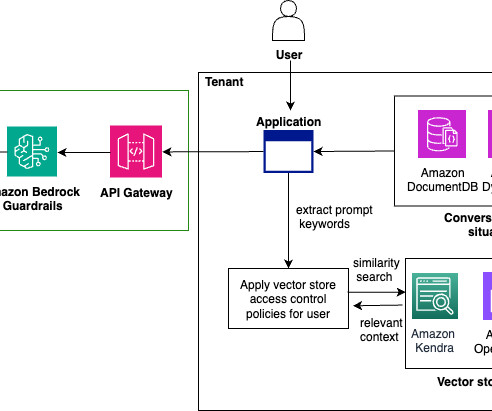
Non-conversational applications offer unique advantages such as higher latency tolerance, batch processing, and caching, but their autonomous nature requires stronger guardrails and exhaustive quality assurance compared to conversational applications, which benefit from real-time user feedback and supervision.
Starting today, you can interactively prepare large datasets, create end-to-end data flows, and invoke automated machine learning (AutoML) experiments on petabytes of data—a substantial leap from the previous 5 GB limit. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
The post When It Comes to DataQuality, Businesses Get Out What They Put In appeared first on DATAVERSITY. The stakes are high, so you search the web and find the most revered chicken parmesan recipe around. At the grocery store, it is immediately clear that some ingredients are much more […].
Posted by Peter Mattson, Senior Staff Engineer, ML Performance, and Praveen Paritosh, Senior Research Scientist, Google Research, Brain Team Machine learning (ML) offers tremendous potential, from diagnosing cancer to engineering safe self-driving cars to amplifying human productivity. Each step can introduce issues and biases.
This reliance has spurred a significant shift across industries, driven by advancements in artificial intelligence (AI) and machine learning (ML), which thrive on comprehensive, high-qualitydata.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
In this post, we share how Axfood, a large Swedish food retailer, improved operations and scalability of their existing artificial intelligence (AI) and machine learning (ML) operations by prototyping in close collaboration with AWS experts and using Amazon SageMaker. This is a guest post written by Axfood AB.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem.
Data has become a driving force behind change and innovation in 2025, fundamentally altering how businesses operate. Across sectors, organizations are using advancements in artificial intelligence (AI), machine learning (ML), and data-sharing technologies to improve decision-making, foster collaboration, and uncover new opportunities.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
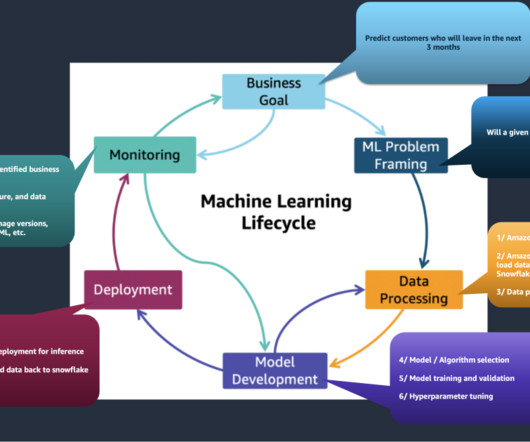
This blog post is co-written with Qaish Kanchwala from The Weather Company. As industries begin adopting processes dependent on machine learning (ML) technologies, it is critical to establish machine learning operations (MLOps) that scale to support growth and utilization of this technology.
However, once deployed in a real-world setting, its performance plummeted due to dataquality issues and unforeseen biases. This scenario highlights a common reality in the Machine Learning landscape: despite the hype surrounding ML capabilities, many projects fail to deliver expected results due to various challenges.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
Dataquality plays a significant role in helping organizations strategize their policies that can keep them ahead of the crowd. Hence, companies need to adopt the right strategies that can help them filter the relevant data from the unwanted ones and get accurate and precise output.
SageMaker JumpStart is a machine learning (ML) hub that provides a wide range of publicly available and proprietary FMs from providers such as AI21 Labs, Cohere, Hugging Face, Meta, and Stability AI, which you can deploy to SageMaker endpoints in your own AWS account. It’s serverless so you don’t have to manage the infrastructure.
The solution uses the following AWS data stores and analytics services: Unstructured data Amazon Simple Storage Service (Amazon S3) buckets are used to store the JSON-based social media feedback data, quality report PDFs (specific to OEMs), and the vehicle and its features images.
With that data, organizations in this sector are able to better understand customers and improve experiences, fight financial crimes, reduce compliance risks, optimize branch performance, and stay ahead of the competition. That represents a huge opportunity, especially as advanced analytics, AI, and machine learning (ML) gain momentum.
What is DataQuality? Dataquality is defined as: the degree to which data meets a company’s expectations of accuracy, validity, completeness, and consistency. By tracking dataquality , a business can pinpoint potential issues harming quality, and ensure that shared data is fit to be used for a given purpose.
Amazon DataZone makes it straightforward for engineers, data scientists, product managers, analysts, and business users to access data throughout an organization so they can discover, use, and collaborate to derive data-driven insights.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. On the Analyses tab, choose DataQuality and Insights Report.
In addition to traditional custom-tailored deep learning models, SageMaker Ground Truth also supports generative AI use cases, enabling the generation of high-quality training data for artificial intelligence and machine learning (AI/ML) models. To learn more, see Use Amazon SageMaker Ground Truth Plus to Label Data.
If you are a returning user to SageMaker Studio, in order to ensure Salesforce Data Cloud is enabled, upgrade to the latest Jupyter and SageMaker Data Wrangler kernels. This completes the setup to enable data access from Salesforce Data Cloud to SageMaker Studio to build AI and machine learning (ML) models.
Dataquality is ownership of the consuming applications or data producers. Governance The two key areas of governance are model and data: Model governance Monitor model for performance, robustness, and fairness. Since 2013 he has helped AWS customers adopt AI/ML technology as a Solutions Architect.
The ability to quickly build and deploy machine learning (ML) models is becoming increasingly important in today’s data-driven world. However, building ML models requires significant time, effort, and specialized expertise. This is where the AWS suite of low-code and no-code ML services becomes an essential tool.
In an effort to better understand where data governance is heading, we spoke with top executives from IT, healthcare, and finance to hear their thoughts on the biggest trends, key challenges, and what insights they would recommend. This blog is a collection of those insights, but for the full trendbook, we recommend downloading the PDF.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
TL;DR Feedback integration is crucial for ML models to meet user needs. A robust ML infrastructure gives teams a competitive advantage. I started my ML journey as an analyst back in 2016. Mailchimp’s ML Platform: genesis, challenges, and objectives Mailchimp is a 20-year-old bootstrapped email marketing company.
The post DataQuality Best Practices to Discover the Hidden Potential of Dirty Data in Health Care appeared first on DATAVERSITY. Health plans will […].
Evaluating ML model performance is essential for ensuring the reliability, quality, accuracy and effectiveness of your ML models. In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in.
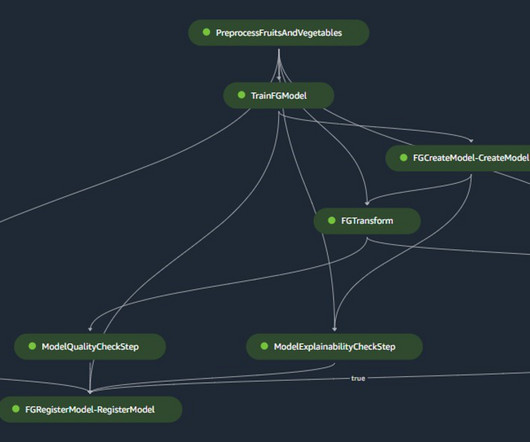
This is a joint blog with AWS and Philips. Amazon SageMaker provides purpose-built tools for machine learning operations (MLOps) to help automate and standardize processes across the ML lifecycle. In this post, we describe how Philips partnered with AWS to develop AI ToolSuite—a scalable, secure, and compliant ML platform on SageMaker.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. The company aims to integrate additional data sources, including other mission-critical systems, into ODAP.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content