This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As we delve into 2023, the realms of DataScience, Artificial Intelligence (AI), and Large Language Models (LLMs) continue to evolve at an unprecedented pace. In this blog, we will explore the top 7 blogs of 2023 that have been instrumental in disseminating detailed and updated information in these dynamic fields.
7 types of statistical distributions with practical examples Statistical distributions help us understand a problem better by assigning a range of possible values to the variables, making them very useful in datascience and machine learning. Here are 7 types of distributions with intuitive examples that often occur in real-life data.
Though you may encounter the terms “datascience” and “data analytics” being used interchangeably in conversations or online, they refer to two distinctly different concepts. Meanwhile, data analytics is the act of examining datasets to extract value and find answers to specific questions.
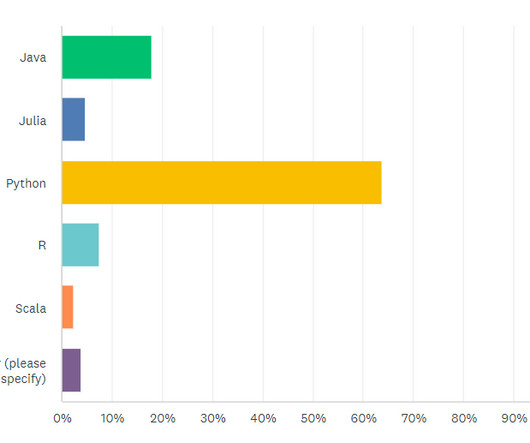
In a series of articles, we’d like to share the results so you too can learn more about what the datascience community is doing in machine learning. In the first blog, we’re going to discuss the technical side of things, such as what languages and platforms people are using. What areas of machine learning are you interested in?
We give recommendations and examples below, with instructors of college or graduate level datascience or applied statistics courses in mind. Variations: For practice with datawrangling, students can find, download, and prepare data for analysis as part of the assignment. Difficulty: All skill levels.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
Summary: DataScience appears challenging due to its complexity, encompassing statistics, programming, and domain knowledge. However, aspiring data scientists can overcome obstacles through continuous learning, hands-on practice, and mentorship. However, many aspiring professionals wonder: Is DataScience hard?
One of the most demanding fields in the business world today is of DataScience. With numerous job opportunities, DataScience skills have become essential in the market. The easiest skill that a DataScience aspirant might develop is SQL. What is SQL?
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience.
Summary: This guide highlights the best free DataScience courses in 2024, offering a practical starting point for learners eager to build foundational DataScience skills without financial barriers. Introduction DataScience skills are in high demand. billion in 2021 and projected to reach $322.9
If you are a data scientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that data scientists already have that are transferable to data engineering. In this blog post, we will discuss how you can become a data engineer if you are a data scientist.
What is R in DataScience? As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. How is R Used in DataScience? R is a popular programming language and environment widely used in the field of datascience.
With technological developments occurring rapidly within the world, Computer Science and DataScience are increasingly becoming the most demanding career choices. Moreover, with the oozing opportunities in DataScience job roles, transitioning your career from Computer Science to DataScience can be quite interesting.
What is DataScience? DataScience is the field of extracting data from large volumes of datasets and transformed into meaningful insights so that effective decision-making takes place. Based on the lucrative opportunities, many of you are aspiring to become DataScience experts and want to learn DataScience.
DataScience has emerged as one of the most prominent and demanding prospects in the with millions of job roles coming up in the market. Pursuing a career in DataScience can be highly promising and you can become a DataScience even without having prior knowledge on technical concepts.
A Data Analyst certification builds credibility, validates expertise, and opens doors to advanced career opportunities. This blog explores top certifications, factors to consider when choosing one, and future trends, helping aspiring and experienced analysts navigate their professional growth effectively.
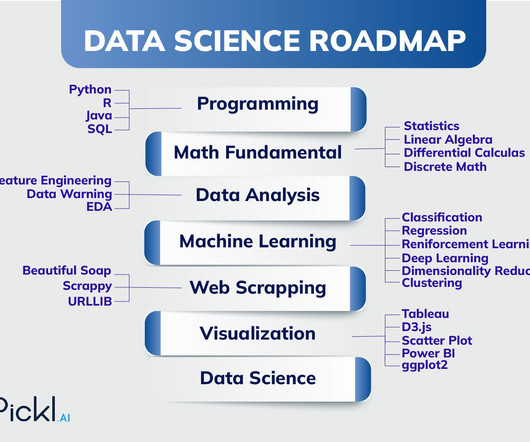
Companies are looking forward to hiring crème de la crème Data Scientists. This guide throws light on the roadmap to becoming a Data Scientist. Key Takeaways: DataScience is a multidisciplinary field bridging statistics, mathematics, and computer science to extract insights from data.
Conclusion Migrating your existing SageMaker Data Wrangler flows to SageMaker Canvas is a straightforward process that allows you to use the advanced data preparations you’ve already developed while taking advantage of the end-to-end, low-code no-code ML workflow of SageMaker Canvas.
This new feature enables you to run large datawrangling operations efficiently, within Azure ML, by leveraging Azure Synapse Analytics to get access to an Apache Spark pool. She loves to share her knowledge with others through her Azure ML and machine learning blog.
However, analysis of data may involve partiality or incorrect insights in case the data quality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. What is Data Profiling in ETL? How to do data profiling in Excel?
In manufacturing, data engineering aids in optimizing operations and enhancing productivity while ensuring curated data that is both compliant and high in integrity. The increased efficiency in data “wrangling” means that more accurate modeling and planning may be done, enabling manufacturers to make stronger data-driven decisions.
Stay Updated Keep up with the latest advancements in the field of AI by following industry blogs, attending conferences, and engaging in continuous learning. Data Manipulation and Preprocessing Proficiency in data preprocessing techniques, feature engineering, and datawrangling to ensure the quality and reliability of input data.
Summary: This blog explores attributes in DBMS, exploring their various types (simple, composite, etc.) and their significance in data retrieval, analysis, and security. Learn best practices for attribute design and how they contribute to the evolving data landscape.
Summary: This article discusses the interoperability of Python, MATLAB, and R, emphasising their unique strengths in DataScience, Engineering, and Statistical Analysis. It highlights the importance of combining these languages for efficient workflows while addressing challenges such as data compatibility and performance bottlenecks.
Choosing the right ETL tool is crucial for smooth data management. This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration. Let’s unlock the power of ETL Tools for seamless data handling. Also Read: Top 10 DataScience tools for 2024. What is ETL?
Jupyter notebooks have been one of the most controversial tools in the datascience community. Nevertheless, many data scientists will agree that they can be really valuable – if used well. I’ll show you best practices for using Jupyter Notebooks for exploratory data analysis. documentation.
A well-structured syllabus for Big Data encompasses various aspects, including foundational concepts, technologies, data processing techniques, and real-world applications. This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master.
The Anaconda distribution includes several valuable libraries for datascience. Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. Prerequisite Python 3.8
With its decoupled compute and storage resources, Snowflake is a cloud-native data platform optimized to scale with the business. Dataiku is an advanced analytics and machine learning platform designed to democratize datascience and foster collaboration across technical and non-technical teams.
Dreaming of a DataScience career but started as an Analyst? This guide unlocks the path from Data Analyst to Data Scientist Architect. So if you are looking forward to a DataScience career , this blog will work as a guiding light.
Over the past decade, datascience has undergone a remarkable evolution, driven by rapid advancements in machine learning, artificial intelligence, and big data technologies. This blog dives deep into these changes of trends in datascience, spotlighting how conference topics mirror the broader evolution of datascience.
Allen Downey, PhD, Principal Data Scientist at PyMCLabs Allen is the author of several booksincluding Think Python, Think Bayes, and Probably Overthinking Itand a blog about datascience and Bayesian statistics. in computer science from the University of California, Berkeley; and Bachelors and Masters degrees fromMIT.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content