This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon Image 1In this blog, We are going to talk about some of the advanced and most used charts in Plotly while doing analysis. Table of content Description of Dataset Data Exploration Data Cleaning Data visualization […].
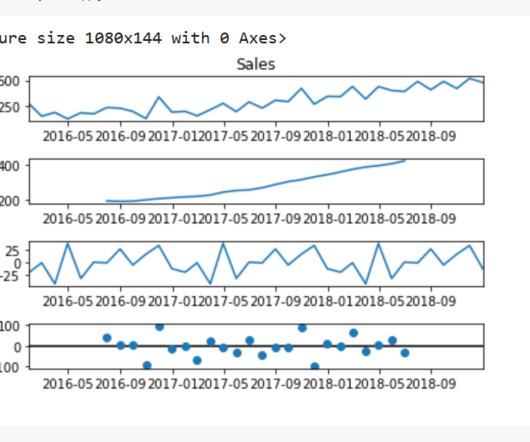
In this blog, we will discuss exploratory data analysis, also known as EDA, and why it is important. EDA is an iterative process of conglomerative activities which include data cleaning, manipulation and visualization. We will also be sharing code snippets so you can try out different analysis techniques yourself.
ChatGPT plugins can be used to extend the capabilities of ChatGPT in a variety of ways, such as: Accessing and processing external data Performing complex computations Using third-party services In this article, we’ll dive into the top 6 ChatGPT plugins tailored for datascience.
Introduction Analytics Vidhya DataHour is designed to provide valuable insights and knowledge to individuals looking to build a career in the data-tech industry. These sessions cover a wide range of topics, from the fields of artificial intelligence, and machine learning, and various topics related to datascience.
This article was published as a part of the DataScience Blogathon. In this blog, we study […]. The post A Detailed Study on COVID 19 Vaccinations Data appeared first on Analytics Vidhya. A considerably low vaccination rate has been observed in low-income countries of the world.
ArticleVideo Book This article was published as a part of the DataScience Blogathon Hi all, this is my first blog hope you all like. The post Performing Exploratory Data Analysis with SAS and Python appeared first on Analytics Vidhya.
This blog explores the amazing AI (Artificial Intelligence) technology called ChatGPT that has taken the world by storm and try to unravel the underlying phenomenon which makes up this seemingly complex technology. Well, fret not we are here to answer those questions in this blog. What is ChatGPT? What purpose does it serve?
Many beginners in datascience and machine learning only focus on the data analysis and model development part, which is understandable, as the other department often does the deployment process. We will walk through it together, from the data analysis to automatic retraining. Establish a DataScience Project2.
Comet is an MLOps platform that offers a suite of tools for machine-learning experimentation and data analysis. It is designed to make it easy to track and monitor experiments and conduct exploratory data analysis (EDA) using popular Python visualization frameworks. Please consider signing up using my referral link.
This is particularly important for relational databases, where data is stored in tables with defined relationships. Another interesting read: Master EDA Importance of Data Normalization So, we defined data normalization, and hopefully, youve got the idea. Most of these challenges have workarounds.
For data scrapping a variety of sources, such as online databases, sensor data, or social media. Cleaning data: Once the data has been gathered, it needs to be cleaned. This involves removing any errors or inconsistencies in the data. This information can be used to inform the design of the model.
DataScience is a popular as well as vast field; till date, there are a lot of opportunities in this field, and most people, whether they are working professionals or students, everyone want a transition in datascience because of its scope. How much to learn? What to do next?
We give recommendations and examples below, with instructors of college or graduate level datascience or applied statistics courses in mind. Variations: For practice with data wrangling, students can find, download, and prepare data for analysis as part of the assignment. from the Snowcast Showdown.
The importance of EDA in the machine learning world is well known to its users. Making visualizations is one of the finest ways for data scientists to explain data analysis to people outside the business. Exploratory data analysis can help you comprehend your data better, which can aid in future data preprocessing.
Embark on Your DataScience Journey through In-Depth Projects and Hands-on Learning Photo by Wes Hicks on Unsplash Datascience, as an emerging field, is constantly evolving and bringing forth innovative solutions to complex problems. I’ve handpicked a few Kaggle projects covering a range of datascience concepts.
Today’s question is, “What does a data scientist do.” ” Step into the realm of datascience, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of data scientists.
This blog explores the difference between mutable and immutable object in python. Want to start your EDA journey, well you can always get yourself registered at Python for DataScience. Python is a powerful programming language with a wide range of applications in various industries.
How to create a DataScience Project on GitHub? DataScience being the most demanding career fields today with millions of job opportunities flooding in the market. in order to ensure that you have a great career in DataScience, one of the major requirements is to create and have a Github DataScience project.
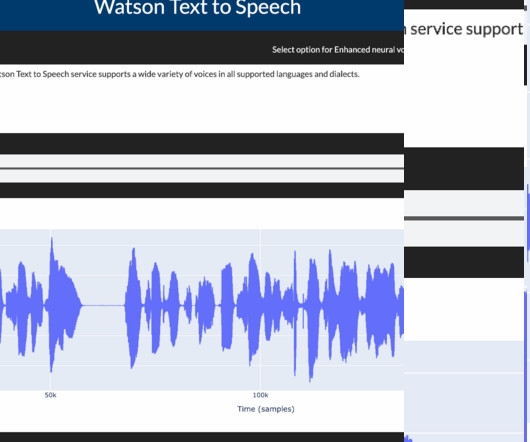
Text to Speech Dash app IBM Watson’s text-to-speech model is built using machine learning techniques and deep neural networks, trained on large amounts of speech and text data. This blog gives an overview of how to convert text data into speech and how to control speech rate & voice pitch using Watson Speech libraries.
Together, data engineers, data scientists, and machine learning engineers form a cohesive team that drives innovation and success in data analytics and artificial intelligence. Their collective efforts are indispensable for organizations seeking to harness data’s full potential and achieve business growth.
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production. Exploratory Data Analysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
And importantly, starting naively annotating data might become a quick solution rather than thinking about how to make uses of limited labels if extracting data itself is easy and does not cost so much. In that case, you tasks have your own problem, and you would have to be careful about your EDA, data cleaning, and labeling.
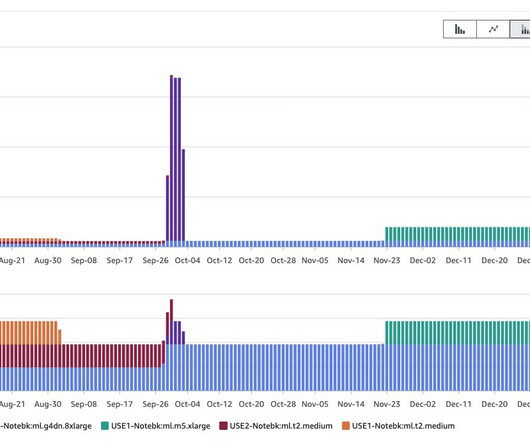
In this blog, I will walk through AWS SageMaker's capabilities in addressing these questions. An MLOps workflow consists of a series of steps from data acquisition and feature engineering to training and deployment. Collaboration] How can multiple data scientists collaborate in real-time on the same dataset?
Exploratory Data Analysis(EDA)on Biological Data: A Hands-On Guide Unraveling the Structural Data of Proteins, Part II — Exploratory Data Analysis Photo from Pexels In a previous post, I covered the background of this protein structure resolution data set, including an explanation of key data terminology and details on how to acquire the data.
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. Stay tuned for updates and discussions on our blog page blog.oceanprotocol.com for progress throughout the year!
I initially conducted detailed exploratory data analysis (EDA) to understand the dataset, identifying challenges like duplicate entries and missing Coordinate Reference System (CRS) information. I consider myself as a machine learning engineer who enjoys taking part in various machine learning competitions.
The early days of the effort were spent on EDA and exchanging ideas with other members of the community. Before models could be built, gaining an understanding of the data, strengths and weaknesses of the dataset and what researchers are looking for out of the CORD-19 dataset was needed.
We will carry out some EDA on our dataset, and then we will log the visualizations onto the Comet experimentation website or platform. Time Series Models Time series models are a type of statistical model that are used to analyze and make predictions about data that is collected over time. Without further ado, let’s begin.
Who This Book Is For This book is for practitioners in charge of building, managing, maintaining, and operationalizing the ML process end to end: Datascience / AI / ML leaders: Heads of DataScience, VPs of Advanced Analytics, AI Lead etc. The book contains a full chapter dedicated to generative AI. Key Takeaways 1.
Python data visualisation libraries offer powerful visualisation tools , ranging from simple charts to interactive dashboards. In this blog, we aim to explore the most popular Python data visualisation libraries, highlight their unique features, and guide you on how to use them effectively.
In the digital age, the abundance of textual information available on the internet, particularly on platforms like Twitter, blogs, and e-commerce websites, has led to an exponential growth in unstructured data. Integration also helps avoid duplication and redundancy of data, providing a comprehensive view of the information.
But they need a lot of labeled training data, and the dataset could be biased. In order to accomplish this, we will perform some EDA on the Disneyland dataset, and then we will view the visualization on the Comet experimentation website or platform. In this article, we’ll learn how to link Comet with Disneyland Sentiment Analysis.
In this blog post, I’m going to show you how to use the lazypredict library on your dataset. You may need to import more libraries for EDA, preprocessing, and so on depending on the dataset you’re dealing with. Call-To-Action Enjoyed this blog post? Give it a clap and share it with your fellow data enthusiasts!
In a typical MLOps project, similar scheduling is essential to handle new data and track model performance continuously. Load and Explore Data We load the Telco Customer Churn dataset and perform exploratory data analysis (EDA). Experiment Tracking in CometML (Image by the Author) 2.
Introduction Welcome Back, Let's continue with our DataScience journey to create the Stock Price Prediction web application. The scope of this article is quite big, we will exercise the core steps of datascience, let's get started… Project Layout Here are the high-level steps for this project.
Vertex AI combines data engineering, datascience, and ML engineering into a single, cohesive environment, making it easier for data scientists and ML engineers to build, deploy, and manage ML models. Data Preparation Begin by ingesting and analysing your dataset.
We use the model preview functionality to perform an initial EDA. This provides us a baseline that we can use to perform data augmentation, generating a new baseline, and finally getting the best model with a model-centric approach using the standard build functionality.
For ML model development, the size of a SageMaker notebook instance depends on the amount of data you need to load in-memory for meaningful exploratory data analyses (EDA) and the amount of computation required. We recommend starting small with general-purpose instances (such as T or M families) and scaling up as needed.
Create DataGrids with image data using Kangas, and load and visualize image data from hugging face Photo by Genny Dimitrakopoulou on Unsplash Visualizing data to carry out a detailed EDA, especially for image data, is critical. Be sure to explore more on the Kangas repo.
Central to Pandas is the DataFrame object, a versatile structure for managing and analysing data in tabular form. This blog introduces the Pandas DataFrame.loc method, which is crucial for data selection and manipulation.
Photo by Juraj Gabriel on Unsplash Data analysis is a powerful tool that helps businesses make informed decisions. In today’s blog, we will explore the Netflix dataset using Python and uncover some interesting insights. The platform has gained a massive following in recent years, and its popularity shows no signs of slowing down.
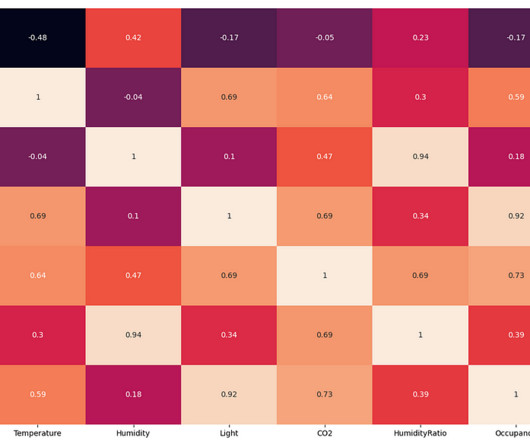
From the above EDA, it is clear that the room's temperature, light, and CO2 levels are good occupancy indicators. The exploratory data analysis found that the change in room temperature, CO levels, and light intensity can be used to predict the occupancy of the room in place of humidity and humidity ratio.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratory data analysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
Now you need to perform some EDA and cleaning on the data after loading it into the notebook. EDA and Data Cleaning First, you will check the frequency of the target variable: Category. This variable denotes the type of emotions represented by the Reddit threads. We pay our contributors, and we don’t sell ads.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content