This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) datascience. Digital tech created an abundance of tools, but a simple set can solve everything. Better yet, a riddle.
By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success. In this blog, we focus on machine learning practices—the essential steps that unlock the potential of this transformative technology.
Feature Engineering encompasses a diverse array of techniques, including Feature Transformation, Feature Construction, Feature Selection, Feature Scaling, and Feature Extraction, each playing a crucial role in refining and optimizing the representation of data for machine learning tasks.
In this blog, we will explore the details of both approaches and navigate through their differences. These methodologies represent distinct paradigms in AI, each with unique capabilities and applications. Yet the crucial question arises: Which of these emerges as the foremost driving force in AI innovation? What is Generative AI?
In DataScience, clustering is used to group similar instances together, discovering patterns, hidden structures, and fundamental relationships within a dataset. In this introduction guide, I will formally introduce you to clustering in Machine Learning. As… Read the full blog for free on Medium.
While datascience and machine learning are related, they are very different fields. In a nutshell, datascience brings structure to big data while machine learning focuses on learning from the data itself. What is datascience? What is machine learning?
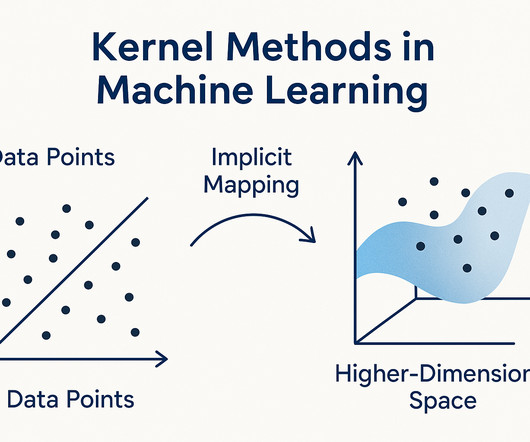
Learn how they work and how to apply them in real-world projects through Pickl.AIs datascience courses. Introduction Machine learning often struggles when the data isnt in a straight lineliterally! This is where kernel methods in machine learning come in like superheroes. Lets dive in!
The field of datascience changes constantly, and some frameworks, tools, and algorithms just can’t get the job done anymore. A few standout topics include model deployment and inferencing, MLOps, and multi-cloud machine learning. Also, as newer fields emerge, it’s not always easy to keep up with everything.
One of its key techniques is associative classification in data mining , which combines association rule mining with classification to improve predictive modelling. This blog aims to explain associative classification in data mining, its applications, and its role in various industries.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and DataScience, highlighting their complementary roles in Data Analysis and intelligent decision-making. This article explores how AI and DataScience complement each other, highlighting their combined impact and potential.
With the expanding field of DataScience, the need for efficient and skilled professionals is increasing. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience. Its efficacy may allow kids from a young age to learn Python and explore the field of DataScience.
In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. While summing up… In conclusion, data mining is a powerful tool that can help businesses and organizations extract valuable insights from their data.
Hey guys, in this blog we will see some of the most asked DataScience Interview Questions by interviewers in [year]. Datascience has become an integral part of many industries, and as a result, the demand for skilled data scientists is soaring. What is DataScience?
It has led to advanced techniques for data management, where each tactic is based on the type of data and the way to handle it. Categorical data is one such form of information that is handled by ML models using different methods. In this blog, we will explore the basics of categorical data.
Gradient boosting also provides a popular ensemble technique that is often used for unbalanced data, which is quite common in attribution data. Moreover, random forest models as well as supportvectormachines (SVMs) are also frequently applied. PLoS ONE 18(1): e0278937. link] pone.0278937
Machine learning(ML) is evolving at a very fast pace. I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning?
What is machine learning? ML is a computer science, datascience and artificial intelligence (AI) subset that enables systems to learn and improve from data without additional programming interventions. AI studio The post Five machine learning types to know appeared first on IBM Blog.
In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. What makes it popular is that it is used in a wide variety of fields, including datascience, machine learning, and computational physics. What’s next for me and these top Python libraries?
Anomalies are not inherently bad, but being aware of them, and having data to put them in context, is integral to understanding and protecting your business. The challenge for IT departments working in datascience is making sense of expanding and ever-changing data points.
⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ? will my data help in this ? ▶ Type of Data : The type of data you have can also affect the choice of the classification algorithm.
Classification algorithms like supportvectormachines (SVMs) are especially well-suited to use this implicit geometry of the data. DataLab is the unit focused on the development of solutions for generating value from the exploitation of data through artificial intelligence.
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of data model for Machine Learning, exploring their types. What is Machine Learning?
The surge of digitization and its growing penetration across the industry spectrum has increased the relevance of text mining in DataScience. Text mining is primarily a technique in the field of DataScience that encompasses the extraction of meaningful insights and information from unstructured textual data.
Anomaly detection is the process of identifying data points that deviate significantly from the expected pattern. The main focus of this blog is to explore a range of statistical and machine learning methods that can be utilized for detecting anomalies in data.
Schematic diagram of the overall framework of Emotion Recognition System [ Source ] The models that are used for AI emotion recognition can be based on linear models like SupportVectorMachines (SVMs) or non-linear models like Convolutional Neural Networks (CNNs). Thanks for reading!!
Machine Learning is a subset of Artificial Intelligence and Computer Science that makes use of data and algorithms to imitate human learning and improving accuracy. Being an important component of DataScience, the use of statistical methods are crucial in training algorithms in order to make classification.
NRE is a complex task that involves multiple steps and requires sophisticated machine learning algorithms like Hidden Markov Models (HMMs) , Conditional Random Fields (CRFs), and SupportVectorMachines (SVMs) be present. We’re committed to supporting and inspiring developers and engineers from all walks of life.
Revolutionizing Healthcare through DataScience and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating datascience, machine learning, and information technology.
It is possible to improve the performance of these algorithms with machine learning algorithms such as SupportVectorMachines. We’re committed to supporting and inspiring developers and engineers from all walks of life. Another advantage is that these algorithms are not limited to working independently.
One of the best ways to take advantage of social media data is to implement text-mining programs that streamline the process. Machine learning algorithms like Naïve Bayes and supportvectormachines (SVM), and deep learning models like convolutional neural networks (CNN) are frequently used for text classification.
Bioinformatics: A Haven for Data Scientists and Machine Learning Engineers: Bioinformatics offers an unparalleled opportunity for data scientists and machine learning engineers to apply their expertise in solving complex biological problems. We pay our contributors, and we don’t sell ads.
Editor's Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. We're committed to supporting and inspiring developers and engineers from all walks of life.
The following code snippet demonstrates how to aggregate raster data to administrative vector boundaries: import geopandas as gp import numpy as np import pandas as pd import rasterio from rasterstats import zonal_stats import pandas as pd def get_proportions(inRaster, inVector, classDict, idCols, year): # Reading In Vector File if '.parquet'
Hinge Losses — Another set of losses for classification problems, but commonly used in supportvectormachines. We’re committed to supporting and inspiring developers and engineers from all walks of life. Regression Losses — When our predictions are going to be continuous. We pay our contributors, and we don’t sell ads.
The following blog will emphasise on what the future of AI looks like in the next 5 years. Machine Learning and Neural Networks (1990s-2000s): Machine Learning (ML) became a focal point, enabling systems to learn from data and improve performance without explicit programming.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. They are handy for high-dimensional data.
Supportvectormachine classifiers as applied to AVIRIS data.” Cross Validated] Editor’s Note: Heartbeat is a contributor-driven online publication and community dedicated to providing premier educational resources for datascience, machine learning, and deep learning practitioners. PMLR, 2017. [2]
Its popularity is due to its relatively small size, simple and well-defined task, and high quality of the data. It has been used to train and test a variety of machine learning models, including artificial neural networks, convolutional neural networks, and supportvectormachines, among others.
This blog will explore the basics of the Perceptron, the mathematics behind it, how it is trained, its applications, limitations, and advancements beyond the Perceptron model. More advanced classifiers like supportvectormachines and neural networks have greater representational power and can learn non-linear decision boundaries.
These features can then be used as input to another machine learning model, such as a supportvectormachine (SVM) or a random forest classifier, to perform tasks such as image classification or object detection. We’re committed to supporting and inspiring developers and engineers from all walks of life.
The e1071 package provides a suite of statistical classification functions, including supportvectormachines (SVMs), which are commonly used for spam detection. Naive Bayes, according to Nagesh Singh Chauhan in KDnuggets, is a straightforward machine learning technique that uses Bayes’ theorem to create predictions.
Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models. They typically rely on simpler algorithms like decision trees, supportvectormachines, or linear regression.
A well-structured syllabus for Big Data encompasses various aspects, including foundational concepts, technologies, data processing techniques, and real-world applications. This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content