This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
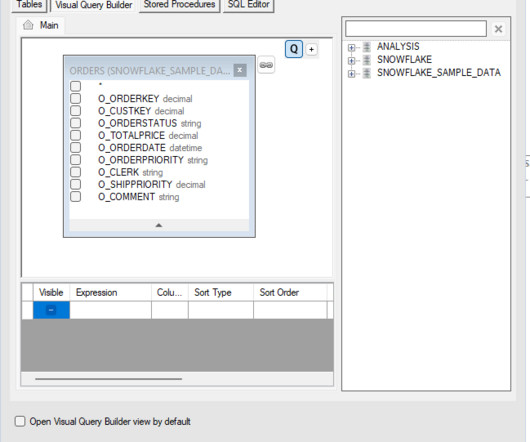
Introduction on Snowflake Architecture This article helps to focus on an in-depth understanding of Snowflake architecture, how it stores and manages data, as well as its conceptual fragmentation concepts. By the end of this blog, you will also be able to understand how Snowflake […].
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their datawarehouse for more comprehensive analysis. Create dbt models in dbt Cloud.
In the contemporary age of Big Data, DataWarehouse Systems and Data Science Analytics Infrastructures have become an essential component for organizations to store, analyze, and make data-driven decisions. So why using IaC for Cloud Data Infrastructures?
Summary : This guide provides an in-depth look at the top datawarehouse interview questions and answers essential for candidates in 2025. Covering key concepts, techniques, and best practices, it equips you with the knowledge needed to excel in interviews and demonstrates your expertise in data warehousing.
Enter AnalyticsCreator AnalyticsCreator, a powerful tool for data management, brings a new level of efficiency and reliability to the CI/CD process. It offers full BI-Stack Automation, from source to datawarehouse through to frontend. It supports a holistic data model, allowing for rapid prototyping of various models.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
Want to create a robust datawarehouse architecture for your business? The sheer volume of data that companies are now gathering is incredible, and understanding how best to store and use this information to extract top performance can be incredibly overwhelming.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
M aintaining the security and governance of data within a datawarehouse is of utmost importance. Data Security: A Multi-layered Approach In data warehousing, data security is not a single barrier but a well-constructed series of layers, each contributing to protecting valuable information.
Data warehousing (DW) and business intelligence (BI) projects are a high priority for many organizations who seek to empower more and better data-driven decisions and actions throughout their enterprises. These groups want to expand their user base for data discovery, BI, and analytics so that their business […].
Summary: This blog explores the key differences between ETL and ELT, detailing their processes, advantages, and disadvantages. Understanding these methods helps organizations optimize their data workflows for better decision-making. What is ETL? ETL stands for Extract, Transform, and Load.
Es bietet vollständige Automatisierung des BI-Stacks und unterstützt ein breites Spektrum an DataWarehouses, analytischen Datenbanken und Frontends. Automatisierung: Erstellt SQL-Code, DACPAC-Dateien, SSIS-Pakete, Data Factory-ARM-Vorlagen und XMLA-Dateien. Data Lakes: Unterstützt MS Azure Blob Storage.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Discover the nuanced dissimilarities between Data Lakes and DataWarehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are Data Lakes and DataWarehouses. It acts as a repository for storing all the data.
In the data analytics processes, choosing the right tools is crucial for ensuring efficiency and scalability. Two popular players in this area are Alteryx Designer and Matillion ETL , both offering strong solutions for handling data workflows with Snowflake Data Cloud integration.
Datawarehouse (DW) testers with data integration QA skills are in demand. Datawarehouse disciplines and architectures are well established and often discussed in the press, books, and conferences. Each business often uses one or more data […]. Each business often uses one or more data […].
Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their […]. The post Avoid These Mistakes on Your DataWarehouse and BI Projects: Part 3 appeared first on DATAVERSITY.
Project sponsors seek to empower more and better data-driven decisions and actions throughout their enterprise; they intend to expand their user base for […]. The post Avoid These Mistakes on Your DataWarehouse and BI Projects: Part 2 appeared first on DATAVERSITY.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
There are advantages and disadvantages to both ETL and ELT. The post Understanding the ETL vs. ELT Alphabet Soup and When to Use Each appeared first on DATAVERSITY. To understand which method is a better fit, it’s important to understand what it means when one letter comes before the other.
Up until recently, feedback forms and […] The post How Reverse ETL Powers Modern Customer Marketing: Concrete Examples appeared first on DATAVERSITY. If you’re part of a customer marketing team, you know that most people would say “not very often.” This is precisely the plight of the average customer marketer.
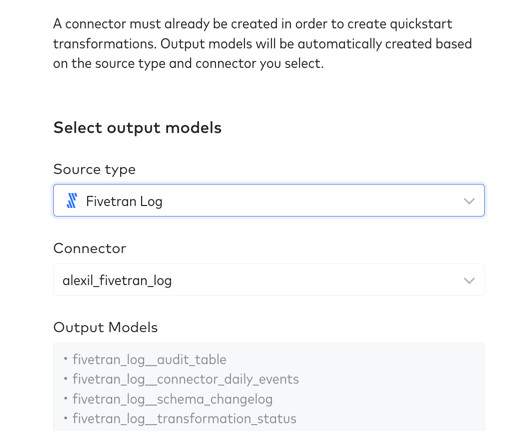
Fivetran, a cloud-based automated data integration platform, has emerged as a leading choice among businesses looking for an easy and cost-effective way to unify their data from various sources. Fivetran is used by businesses to centralize data from various sources into a single, comprehensive datawarehouse.
If you’ve been watching how Snowflake Data Cloud has been growing and changing over the years, you’ll see that two tools have made very large impacts on the Modern Data Stack: Fivetran and dbt. This is unlike the more traditional ETL method, where data is transformed before loading into the datawarehouse.
However, to harness the full potential of Snowflake’s performance capabilities, it is essential to adopt strategies tailored explicitly for data vault modeling. Hash keys provide all key types’ best data load performance, consistency, and audibility.
In this blog, we will cover the best practices for developing jobs in Matillion, an ETL/ELT tool built specifically for cloud database platforms. The blog will be divided into three broad sections: Design, SDLC, and Security, each with its best practices. What Are Matillion Jobs and Why Do They Matter?
Organizations are building data-driven applications to guide business decisions, improve agility, and drive innovation. Many of these applications are complex to build because they require collaboration across teams and the integration of data, tools, and services. Big Data Architect. option("multiLine", "true").option("header",
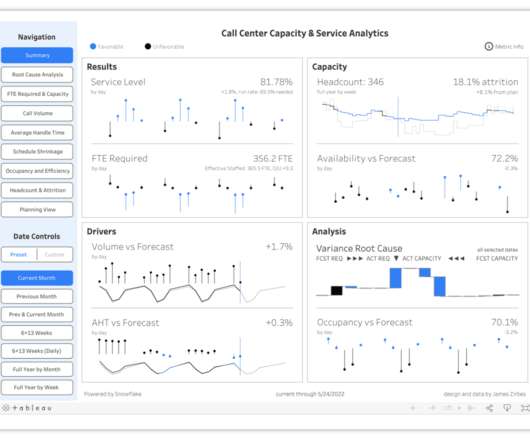
More and more businesses are looking to better leverage their outsourced call center data to make more data-driven decisions. To do this on your own, you would need to create a datawarehouse, optimize the reporting performance, and very clearly visualize the data. Another way to think of it is as Data Activation.
A flexible approach that enables tooling coexistence as well as flexibility with locality of pipeline execution with targeted data planes or pushdown of transformation logic to datawarehouses or lakehouses decreases unnecessary data movement to reduce or eliminate data egress charges.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. A Note on the Shift from ETL to ELT.
Over the past few decades, the corporate data landscape has changed significantly. The shift from on-premise databases and spreadsheets to the modern era of cloud datawarehouses and AI/ LLMs has transformed what businesses can do with data. This is where Fivetran and the Modern Data Stack come in.
Db2 Warehouse fully supports open formats such as Parquet, Avro, ORC and Iceberg table format to share data and extract new insights across teams without duplication or additional extract, transform, load (ETL). This allows you to scale all analytics and AI workloads across the enterprise with trusted data.
Marketing and business professionals must effectively manage and leverage their customer data to stay competitive. In this blog, we will explore how marketing professionals have approached the challenge of effectively using their vast amount of customer data using Composable CDPs. Why use Fivetran for Composable CDP?
TR has a wealth of data that could be used for personalization that has been collected from customer interactions and stored within a centralized datawarehouse. The user interactions data from various sources is persisted in their datawarehouse. The following diagram illustrates the ML training pipeline.
In our previous blog, Top 5 Fivetran Connectors for Financial Services , we explored Fivetran’s capabilities that address the data integration needs of the finance industry. Now, let’s cover the healthcare industry, which also has a surging demand for data and analytics, along with the underlying processes to make it happen.
But, this data is often stored in disparate systems and formats. Here comes the role of Data Mining. Read this blog to know more about Data Integration in Data Mining, The process encompasses various techniques that help filter useful data from the resource. Thereby, improving data quality and consistency.
Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. The following blog will provide you with complete information and in-depth understanding on what is data profiling and its benefits and the various tools used in the method.
Using Amazon Redshift ML for anomaly detection Amazon Redshift ML makes it easy to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift datawarehouses. To capture unanticipated, less obvious data patterns, you can enable anomaly detection.
They defined it as : “ A data lakehouse is a new, open data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of datawarehouses, enabling business intelligence (BI) and machine learning (ML) on all data. ”.
Typically, this data is scattered across Excel files on business users’ desktops. Snowflake can not natively read files on these services, so an ETL service is needed to upload the data. ETL applications are often expensive and require some level of expertise to run.
In this blog, we will show you how easy it is to get your Data Productivity Cloud environment up and running and how you can start your studies on the platform. What is Matillion Data Productivity Cloud? Now, you can start to develop your own Matillion job using the Data Productivity Cloud connected to your datawarehouse.
By employing robust data modeling techniques, businesses can unlock the true value of their data lake and transform it into a strategic asset. With many data modeling methodologies and processes available, choosing the right approach can be daunting. Want to learn more about data governance?
The raw data is processed by an LLM using a preconfigured user prompt. The processed output is stored in a database or datawarehouse, such as Amazon Relational Database Service (Amazon RDS). The stored data is visualized in a BI dashboard using QuickSight. The LLM generates output based on the user prompt.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content