This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will explore the top 7 blogs of 2023 that have been instrumental in disseminating detailed and updated information in these dynamic fields. These blogs stand out not just for their depth of content but also for their ability to make complex topics accessible to a broader audience.
The goal of data cleaning, the data cleaning process, selecting the best programming language and libraries, and the overall methodology and findings will all be covered in this post. Datawrangling requires that you first clean the data. Getting Started First, we need to import the necessary libraries.
7 types of statistical distributions with practical examples Statistical distributions help us understand a problem better by assigning a range of possible values to the variables, making them very useful in data science and machine learning. Here are 7 types of distributions with intuitive examples that often occur in real-life data.
This blog explores the capabilities of multi-modal models in image inference, highlighting their ability to integrate visual and textual information for improved analysis This member-only story is on us. The emergence of multimodal AI has significantly transformed the landscape of datawrangling. Upgrade to access all of Medium.
Clipdrop GitHub Stability AI API AWS Sagemaker AWS Bedrock Stable Foundation Discord DreamStudio Here is an example included in the blog post by Stability AI ( Image Credit ) What is new with SDXL 1.0? Custom LoRAs or checkpoints can be generated with less need for datawrangling. Here is how to get started with SDXL 1.0:
This tool alleviates the cumbersome steps of datawrangling, coding, and model selection, offering a lifeline for those who have long wrestled with such intricacies. Step 5 ( Image credit ) For the base prompt, we input: “ Your name will be Alex, and you’ll be stepping into the role of a Blog Writer.
Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machine learning models. Together they create a powerful, flexible, and scalable foundation for modern data applications.
DrivenData Competitions to use: Any competition with open data Skill options: Flexible to fit a huge range of data science or statistical skills Assessment: Grades can be based on model performance, or a submitted report or presentation. Difficulty: All skill levels.
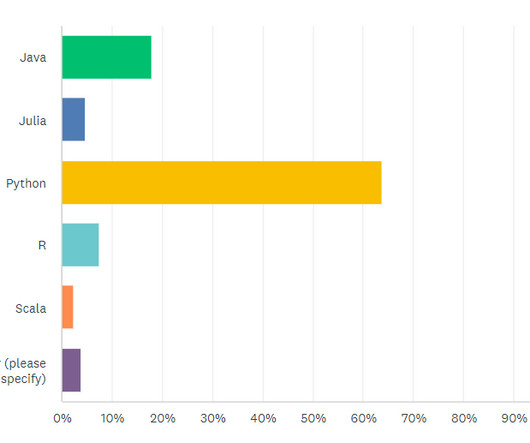
In a series of articles, we’d like to share the results so you too can learn more about what the data science community is doing in machine learning. In the first blog, we’re going to discuss the technical side of things, such as what languages and platforms people are using. What areas of machine learning are you interested in?
Conclusion Migrating your existing SageMaker Data Wrangler flows to SageMaker Canvas is a straightforward process that allows you to use the advanced data preparations you’ve already developed while taking advantage of the end-to-end, low-code no-code ML workflow of SageMaker Canvas.
In the webinar, Leganza will discuss the new imperatives that are defining data exploration, while Kalb will discuss how a data catalog promotes re-use, standardization and answers some of the toughest questions that arise in self-service environments. Subscribe to Alation's Blog.
They may also use tools such as Excel to sort, calculate and visualize data. However, many organizations employ professional data analysts dedicated to datawrangling and interpreting findings to answer specific questions that demand a lot of time and attention.
However, analysis of data may involve partiality or incorrect insights in case the data quality is not adequate. Accordingly, the need for Data Profiling in ETL becomes important for ensuring higher data quality as per business requirements. What is Data Profiling in ETL? How to do data profiling in Excel?
Provide as much information as possible to make the data easier to trust. Free up time for your data analysts and scientists with the catalog, which offloads time-consuming tasks, like datawrangling, so folks have more time for analysis and scientific process. The data will not govern itself.
A Data Analyst certification builds credibility, validates expertise, and opens doors to advanced career opportunities. This blog explores top certifications, factors to consider when choosing one, and future trends, helping aspiring and experienced analysts navigate their professional growth effectively.
So, how to become a Data Scientist after 10th? Let’s find out from the blog! Steps to Become a Data Scientist If you want to pursue a Data Science course after 10th, you need to ensure that you are aware the steps that can help you become a Data Scientist.
There are several courses on Data Science for Non-Technical background aspirants ensuring that they can develop their skills and capabilities to become a Data Scientist. Let’s read the blog to know how can a non-technical person learn Data Science.
However, many aspiring professionals wonder: Is Data Science hard? In this blog, we will explore what makes Data Science seem hard, break down its components, discuss common challenges, compare it to other fields, provide tips for overcoming obstacles, and highlight the rewards of mastering Data Science.
Optionally, you can choose the View all option on the Build tab to get a full list of options to perform feature transformation and datawrangling, such as dropping unimportant columns, dropping duplicate data, replacing missing values, changing data types, and combining columns to create new columns.
The previous blog post, “Data Acquisition & Exploration: Exploring 5 Key MLOps Questions using AWS SageMaker”, explored how AWS SageMaker’s capabilities can help data scientists collaborate and accelerate data exploration and understanding. This section will focus on running transformations on our transaction data.
This new feature enables you to run large datawrangling operations efficiently, within Azure ML, by leveraging Azure Synapse Analytics to get access to an Apache Spark pool. She loves to share her knowledge with others through her Azure ML and machine learning blog.
Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science. Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you. Why learn Python for Data Science? Read below to find out!
Summary: This blog explores attributes in DBMS, exploring their various types (simple, composite, etc.) and their significance in data retrieval, analysis, and security. Learn best practices for attribute design and how they contribute to the evolving data landscape.
Jinja’s usage will significantly empower you to build dynamic and reusable data pipelines , especially when dealing with conditional logic and templatization within dbt. In this blog, we will extract the essence of Jinja in dbt. What is Jinja? Jinja is a powerful and versatile templating engine. Round 11.123 | round(1) 11.1
Dreaming of a Data Science career but started as an Analyst? This guide unlocks the path from Data Analyst to Data Scientist Architect. The Insights This comprehensive guide, updated for 2024, delves into the challenges and strategies associated with scaling Data Science careers.
If you are a data scientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that data scientists already have that are transferable to data engineering. In this blog post, we will discuss how you can become a data engineer if you are a data scientist.
A next huge challenge is data preparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. These tasks can take up to 80% of a data analyst’s time, a well-cited statistic. Registration is now open for The Future of Data-Centric AI 2023.
A next huge challenge is data preparation, or datawrangling tasks, such as identifying and filling in missing values or detecting data entry errors and databases. These tasks can take up to 80% of a data analyst’s time, a well-cited statistic. Registration is now open for The Future of Data-Centric AI 2023.
To keep up with the rapidly growing Insurance industry and its increasing data and compute needs, it’s important to centralize data from multiple sources while maintaining high performance and concurrency. Also today’s volume, variety, and velocity of data, only intensify the data-sharing issues.
Definition, Types & How to Create Ever felt overwhelmed by data but unsure how to translate it into actionable insights? This blog dives deep into the concept of MIS reports, explores different report formats, and equips you with the knowledge to create impactful reports in Excel. What is an MIS Report Meaning?
Let’s look at five benefits of an enterprise data catalog and how they make Alex’s workflow more efficient and her data-driven analysis more informed and relevant. A data catalog replaces tedious request and data-wrangling processes with a fast and seamless user experience to manage and access data products.
Data Science for CS Students can be an outstanding career choice that you can pursue as a Computer Science Engineer. However, how do you transition to a career in Data Science as a CS student? Let’s find out from the blog! Why Transition from Computer Science to Data Science?
Management and storage of Data in businesses require the use of a Database Management System. This blog would an introduction to SQL for Data Science which would cover important aspects of SQL, its need in Data Science, and features and applications of SQL. Wrapping Up!
In manufacturing, data engineering aids in optimizing operations and enhancing productivity while ensuring curated data that is both compliant and high in integrity. The increased efficiency in data “wrangling” means that more accurate modeling and planning may be done, enabling manufacturers to make stronger data-driven decisions.
Step 4: DataWrangling and Visualization Data isn’t always in pristine formats. Learning techniques to clean, preprocess, and visualize data allows you to transform raw information into actionable insights. Read research papers, blogs, and books to keep yourself informed about cutting-edge techniques.
These folks will reference the data dictionary to understand data elements, which allows them to manage, move, merge, and analyze data with clarity. For complex projects, like datawrangling, modeling, or database design, a data dictionary is a helpful resource, especially to new hires.
There is a position called Data Analyst whose work is to analyze the historical data, and from that, they will derive some KPI s (Key Performance Indicators) for making any further calls. For Data Analysis you can focus on such topics as Feature Engineering , DataWrangling , and EDA which is also known as Exploratory Data Analysis.
This blog is your quick guide to mastering percentages in Excel without needing to be a math wizard. Excel makes percentage calculations easy and efficient, from analysing sales growth to adjusting financial data. For aspiring data scientists , understanding these Excel basics is the first step toward more advanced analytics.
Most common R Libraries for Data Science In Data Science, you can find several R Libraries and perform different tasks. Some of the best R libraries are as follows: Dplyr: The dplyr tool is used for performing datawrangling and analysis and make many functions for the data frame in R thus, making it easier to use.
This blog post explores how graph visualization brings digital twins to life. With a little data-wrangling help from Python, I quickly created a powerful network digital twin with real-time infrastructure monitoring and ‘what-if’ simulation capability. Graph visualization SDKs would have been a huge asset to those projects.
Data Science: R Basics by Harvard University on edX Harvard’s Data Science: R Basics on edX uses the R programming language to focus on Data Science. This course covers R commands, datawrangling , and basic data manipulation and is excellent for those who want to gain foundational R skills.
A well-structured syllabus for Big Data encompasses various aspects, including foundational concepts, technologies, data processing techniques, and real-world applications. This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master.
Stay Updated Keep up with the latest advancements in the field of AI by following industry blogs, attending conferences, and engaging in continuous learning. Data Manipulation and Preprocessing Proficiency in data preprocessing techniques, feature engineering, and datawrangling to ensure the quality and reliability of input data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content