This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The goal of data cleaning, the data cleaning process, selecting the best programming language and libraries, and the overall methodology and findings will all be covered in this post. Datawrangling requires that you first clean the data. Getting Started First, we need to import the necessary libraries.
The easiest skill that a Data Science aspirant might develop is SQL. Management and storage of Data in businesses require the use of a Database Management System. This blog would an introduction to SQL for Data Science which would cover important aspects of SQL, its need in Data Science, and features and applications of SQL.
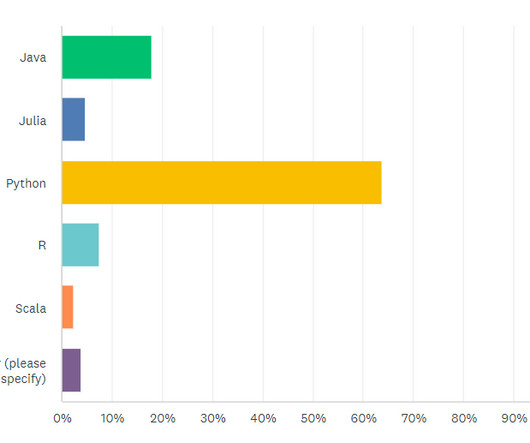
In a series of articles, we’d like to share the results so you too can learn more about what the data science community is doing in machine learning. In the first blog, we’re going to discuss the technical side of things, such as what languages and platforms people are using. What areas of machine learning are you interested in?
A Data Analyst certification builds credibility, validates expertise, and opens doors to advanced career opportunities. This blog explores top certifications, factors to consider when choosing one, and future trends, helping aspiring and experienced analysts navigate their professional growth effectively.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Additionally, data science requires experience in SQL database coding and an ability to work with unstructured data of various types, such as video, audio, pictures and text.
One is a scripting language such as Python, and the other is a Query language like SQL (Structured Query Language) for SQL Databases. Python is a High-level, Procedural, and object-oriented language; it is also a vast language itself, and covering the whole of Python is one the worst mistakes we can make in the data science journey.
So, how to become a Data Scientist after 10th? Let’s find out from the blog! Steps to Become a Data Scientist If you want to pursue a Data Science course after 10th, you need to ensure that you are aware the steps that can help you become a Data Scientist.
There are several courses on Data Science for Non-Technical background aspirants ensuring that they can develop their skills and capabilities to become a Data Scientist. Let’s read the blog to know how can a non-technical person learn Data Science. The post Can someone from Non-IT background become Data Scientist?
Example template for an exploratory notebook | Source: Author How to organize code in Jupyter notebook For exploratory tasks, the code to produce SQL queries, pandas datawrangling, or create plots is not important for readers. in a pandas DataFrame) but in the company’s data warehouse (e.g., documentation.
Here are some important factors to consider to get the most value out of your chosen course: Course Content and Relevance : Ensure the course covers foundational topics like Data Analysis, statistics, and Machine Learning, along with essential tools such as Python and SQL. Data Science Course by Pickl.AI
Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science. Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you. Why learn Python for Data Science? Read below to find out!
If you are a data scientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that data scientists already have that are transferable to data engineering. In this blog post, we will discuss how you can become a data engineer if you are a data scientist.
At the heart of this process lie ETL Tools—Extract, Transform, Load—a trio that extracts data, tweaks it, and loads it into a destination. Choosing the right ETL tool is crucial for smooth data management. This blog will delve into ETL Tools, exploring the top contenders and their roles in modern data integration.
Data Science for CS Students can be an outstanding career choice that you can pursue as a Computer Science Engineer. However, how do you transition to a career in Data Science as a CS student? Let’s find out from the blog! Why Transition from Computer Science to Data Science?
A well-structured syllabus for Big Data encompasses various aspects, including foundational concepts, technologies, data processing techniques, and real-world applications. This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master.
Snowflake excels in efficient data storage and governance, while Dataiku provides the tooling to operationalize advanced analytics and machine learning models. Together they create a powerful, flexible, and scalable foundation for modern data applications.
dbt’s SQL-based approach democratizes data transformation. However, python and other programming languages edge out SQL with its metaprogramming capabilities. dbt’s Jinja integration bridges the gap between the expressiveness of Python and the familiarity of SQL. What is Jinja? Round 11.123 | round(1) 11.1
Rather than locking the data away from those who need it, this approach instead welcomes more users to the data — but adds guardrails to guide use. Deprecation warnings, SQL AutoSuggest, and quality flags are examples of “guardrail features.” Provide as much information as possible to make the data easier to trust.
This blog dives deep into these changes of trends in data science, spotlighting how conference topics mirror the broader evolution of datascience. Tools like Python , R , and SQL were mainstays, with sessions centered around datawrangling, business intelligence, and the growing role of data scientists in decision-making.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

























Let's personalize your content