This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will explore the top 7 LLM, data science, and AI blogs of 2024 that have been instrumental in disseminating detailed and updated information in these dynamic fields. These blogs stand out as they make deep, complex topics easy to understand for a broader audience.
This blog discusses vector databases, specifically pinecone vector databases. A vector database is a type of database that stores data as mathematical vectors, which represent features or attributes. These vectors have multiple dimensions, capturing complex data relationships.
With the rapidly evolving technological world, businesses are constantly contemplating the debate of traditional vs vector databases. This blog delves into a detailed comparison between the two data management techniques. Hence, databases are important for strategic data handling and enhanced operational efficiency.
Enabling SSL for Database in IBM SPSS CaDS on Liberty ServerPost-Installation Guide If youve recently installed the SPSS Collaboration and Deployment Services (CaDS) on IBM Liberty and are wondering how to securely connect to your database via SSL, this blog is for you. Why Enable SSL for DB Connections? Microsoft SQL Server).
Introduction Source: [link] Welcome to our comprehensive guide on NoSQL databases! In this blog, we will dive deep into the world of NoSQL databases, exploring their features, advantages, and disadvantages. The post Everything You Should Know About NoSQL Databases appeared first on Analytics Vidhya.
Traditional hea l t h c a r e databases struggle to grasp the complex relationships between patients and their clinical histories. This blog delves into the technical details of how vec t o r d a ta b a s e s empower patient sim i l a r i ty searches and pave the path for improved diagnosis.
In the dynamic world of machine learning and natural language processing (NLP), database optimization is crucial for effective data handling. Hence, the pivotal role of vector databases in the efficient storage and retrieval of embeddings has become increasingly apparent.
This article was published as a part of the Data Science Blogathon Image 1 Introduction In this article, I will use the YouTube Trends database and Python programming language to train a language model that generates text using learning tools, which will be used for the task of making youtube video articles or for your blogs. […].
It powers business decisions, drives AI models, and keeps databases running efficiently. Without proper organization, databases become bloated, slow, and unreliable. Essentially, data normalization is a database design technique that structures data efficiently. Think about itdata is everywhere.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
Introduction Structured Query Language (SQL) is a powerful tool for managing and manipulating relational databases. In this blog post, we’ll delve into the intricacies of the SQL DATEDIFF function, exploring its syntax, use cases, and […] The post SQL DATEDIFF function appeared first on Analytics Vidhya.
Introduction SQL, a robust language for managing relational databases, boasts a compelling feature known as the WITH clause. This blog post will delve into the WITH clause in SQL, unraveling its effective usage to enhance […] The post 5 Easy Ways to Use SQL WITH Clause appeared first on Analytics Vidhya.
. “We believe your AI should be personal to you at home, work, or on the go and data connectivity is a key part of everyone’s daily workflows,” Perplexity wrote in a blog post. ” Carbon raised a $1.3 million seed round in 2023.
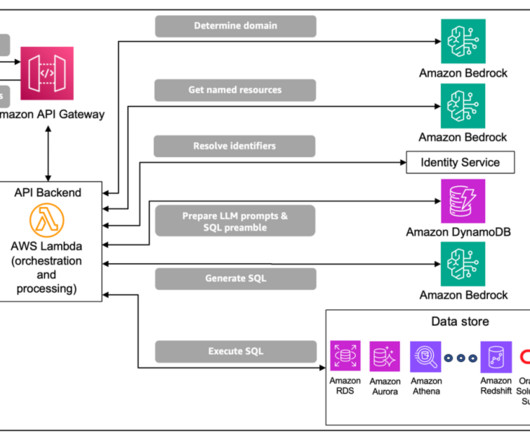
Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. The solution combines data from an Amazon Aurora MySQL-Compatible Edition database and data stored in an Amazon Simple Storage Service (Amazon S3) bucket.
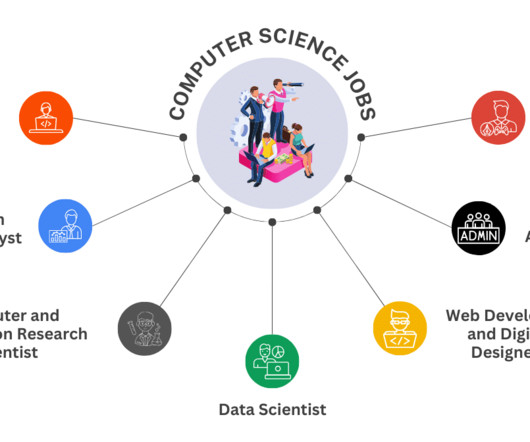
In this blog, we will explore the top computer science major jobs for individuals. Database Administrator A Database Administrator (DBA) is responsible for the performance, integrity, and security of a database. Attention to Detail: Ensuring data accuracy and integrity through meticulous database management practices.
In this blog post, we are going to share the top 10 YouTube videos for learning about LLMs. Any serious applications of LLMs require an understanding of nuances in how LLMs work, embeddings, vector databases, retrieval augmented generation (RAG), orchestration frameworks, and more. What is vector similarity search?
An appropriate data model allows the respective data to be accessible all day long, operate at peak efficiency, and be adjusted to […] The post Data Modeling in Machine Learning Pipelines: Best Practices Using SQL and NoSQL Databases appeared first on DATAVERSITY.
That’s where this blog comes in. In this blog, we’re going to discuss the importance of learning to build your own LLM application, and we’re going to provide a roadmap for becoming a large language model developer. Vector databases: Vector databases are a type of database that stores data in vectors.
This blog post is co-written with Renuka Kumar and Thomas Matthew from Cisco. These tables house complex domain-specific schemas, with instances of nested tables and multi-dimensional data that require complex database queries and domain-specific knowledge for data retrieval.
Learn more about processing snapshots using Delta Live Tables and how you can use the new Apply changes from Snapshshot statement in DLT to build SCD Type 1 or SCD Type 2 target tables delivering incremental data and insights that would typically take months of effort on legacy platforms.
Additionally, we dive into integrating common vector database solutions available for Amazon Bedrock Knowledge Bases and how these integrations enable advanced metadata filtering and querying capabilities. Metadata filtering allows you to segment data inside of an OpenSearch Serverless vector database.
Their information is split between two types of data: unstructured data (such as PDFs, HTML pages, and documents) and structured data (such as databases, data lakes, and real-time reports). An alternative is using an accessible database that QuickSight can connect to. Cross-Region calls arent supported at the time of writing this blog.
It also supports a wide range of data warehouses, analytical databases, data lakes, frontends, and pipelines/ETL. Support for Various Data Warehouses and Databases : AnalyticsCreator supports MS SQL Server 2012-2022, Azure SQL Database, Azure Synapse Analytics dedicated, and more. Data Lakes : It supports MS Azure Blob Storage.
This blog post will walk you through the necessary steps to achieve this using Amazon services and tools. This article was published as a part of the Data Science Blogathon. Introduction Ever wondered how to query and analyze raw data? Also, have you ever tried doing this with Athena and QuickSight?
It works by analyzing the visual content to find similar images in its database. Store embeddings : Ingest the generated embeddings into an OpenSearch Serverless vector index, which serves as the vector database for the solution. To do so, you can use a vector database. The model will then be available for use.
This is the first blog in the series of RAG and finetuning, focusing on providing a better understanding of the two approaches. This blog will walk you through RAG and finetuning, unraveling how they work, why they matter, and how they’re applied to solve real-world problems. But what exactly is a vector database?
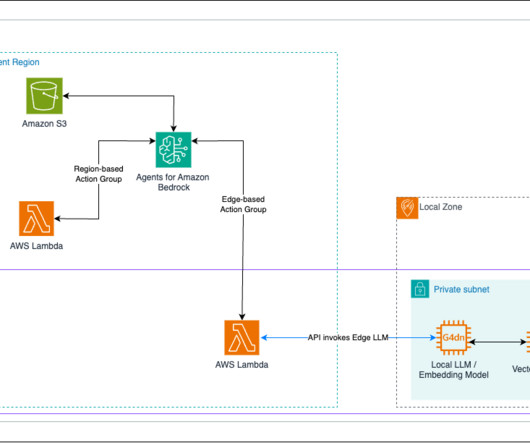
To learn more about opportunities for customers to use SLMs, see Opportunities for telecoms with small language models: Insights from AWS and Meta on our AWS Industries blog. This vector database will store the vector representations of your documents, serving as a key component of your local Knowledge Base.
Dive into this blog as we uncover what is an LLM Bootcamp and how it can benefit your career. It covers a range of topics including generative AI, LLM basics, natural language processing, vector databases, prompt engineering, and much more. But how can you quickly gain expertise in LLMs while juggling a full-time job?
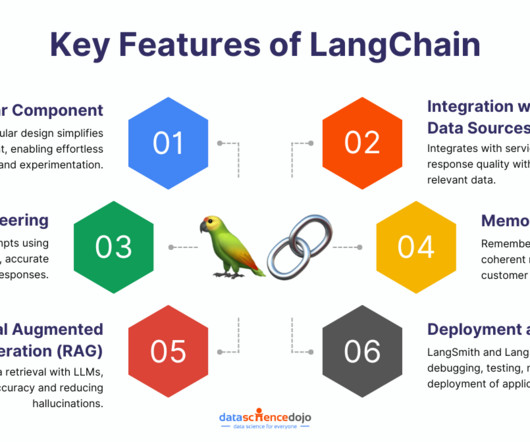
In this blog, we will explore what is LangChain, its key features, benefits, and practical use cases. It also connects effortlessly with collaboration tools like Airtable, Trello, Figma, and Notion, as well as databases including Pandas, MongoDB, and Microsoft databases. All you need to do is configure the necessary connections.
The available data sources are: Stock Prices Database Contains historical stock price data for publicly traded companies. Analyst Notes Database Knowledge base containing reports from Analysts on their interpretation and analyis of economic events. Stock Prices Database The question is about a stock price.
In this blog, we delve into the fundamentals of LlamaIndex, a groundbreaking technology that helps to build applications using LLMs. […] The post Building Natural Language to SQL Applications using LlamaIndex appeared first on Analytics Vidhya.
The recent meltdown of 23andme and what might become of their DNA database got me thinking about this question: What happens to your data when a company goes bankrupt? To say the past year has been a tough one for 23andme is an understatement.
In this blog post, we’ll explore […] The post Multimodal Search Image Application with Titan Embedding appeared first on Analytics Vidhya. One such application is a multimodal image search app, which allows users to search for images using natural language queries.
link] How did you find this blog? This article was published as a part of the Data Science Blogathon. You typed some keywords related to data science in your browser. Then the search engine which you are using has redirected you to here within milliseconds. Have you ever thought about how it worked? The unbeatable power […].
Introduction Welcome to our comprehensive data analysis blog that delves deep into the world of Netflix. As one of the leading streaming platforms globally, Netflix has revolutionized how we consume entertainment. With its vast library of movies and TV shows, it offers an abundance of choices for viewers around the world.
ChatGPT can also use Wolfram Language to create more complex visualizations, such as interactive charts and 3D models. Source: Stephen Wolfram Writings Read this blog to Master ChatGPT cheatsheet 2. It provides access to a vast database of scholarly articles and books, as well as tools for literature review and data analysis.
“The database is unencrypted. Beaumont noted that Recall saves information in a readily accessible database within the user’s AppData folder. Unexpectedly, the database stores this information in plaintext. “It’s a Trojan 2.0 really, built in.”
The following Terraform script will create an Azure Resource Group, a SQL Server, and a SQL Database. appeared first on Data Science Blog. So why using IaC for Cloud Data Infrastructures? administrator_login = "adminUser" administrator_login_password = "adminPassword1234!"
In this blog post, we will explore the potential benefits of generative AI for jobs. You have an idea for a new blog post, but you’re not sure how to get started. For example, a large language model could be used to generate a first draft of a blog post or article, which the content writer could then edit and refine.
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Some are traditional databases, while others emerge from social media, online surveys, and various digital sources. The integration of data is not just about quantity; its… Read the full blog for free on Medium. Each piece represents a different type of data. Join thousands of data leaders on the AI newsletter.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content