This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Though machine learning isn’t a relatively new concept, organizations are increasingly switching to big data and ML models to unleash hidden insights from data, scale their operations better, and predict and confront any underlying business challenges.
Building ML infrastructure and integrating ML models with the larger business are major bottlenecks to AI adoption [1,2,3]. IBM Db2 can help solve these problems with its built-in ML infrastructure. In this post, I will show how to develop, deploy, and use a decisiontree model in a Db2 database.
That world is not science fiction—it’s the reality of machine learning (ML). In this blog post, we’ll break down the end-to-end ML process in business, guiding you through each stage with examples and insights that make it easy to grasp. Formatting the data in a way that ML algorithms can understand.
Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples.
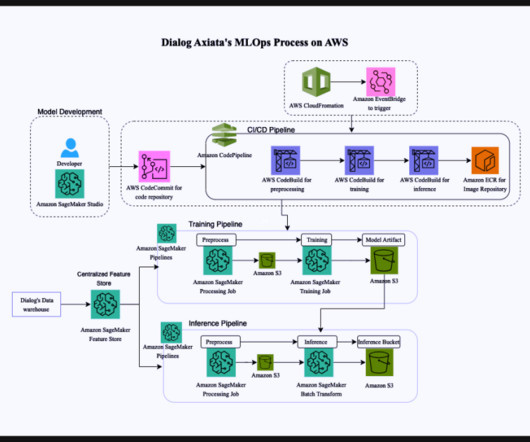
They focused on improving customer service using data with artificial intelligence (AI) and ML and saw positive results, with their Group AI Maturity increasing from 50% to 80%, according to the TM Forum’s AI Maturity Index. Amazon SageMaker Pipelines – Amazon SageMaker Pipelines is a CI/CD service for ML.
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. Machine learning(ML) is evolving at a very fast pace. Machine learning(ML) is evolving at a very fast pace.
With the growing use of machine learning (ML) models to handle, store, and manage data, the efficiency and impact of enterprises have also increased. Categorical data is one such form of information that is handled by ML models using different methods. In this blog, we will explore the basics of categorical data.
The secrets no one tells you but make learning ML a lot easier and enjoyable. Back when I started learning ML, some of my professors would simply throw a formula on the screen and tell us “This is the loss function for a decisiontree” and that was it. It can be very hard! Most of my peers and I were confused.
value_counts()[:10] So, in this blog post, we’ve been digging into EDA steps like dealing with missing values, feature conversion and multicollinearity. Submission Suggestions Predicting the Protein Structure Resolution Using DecisionTree was originally published in MLearning.ai
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
Hey guys in this very short blog we will see how we can train and test multiple models using Lazypredict which is an amazing open-source python package. LazyPredict supports a wide range of supervised machine-learning algorithms, including linear regression, decisiontrees, random forests, gradient boosting, neural networks, and more.
Evaluating ML model performance is essential for ensuring the reliability, quality, accuracy and effectiveness of your ML models. In this blog post, we dive into all aspects of ML model performance: which metrics to use to measure performance, best practices that can help and where MLOps fits in.
⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ? ✔ how to reduce the complexity and computational expensiveness of ML models ? will my data help in this ?
The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem. Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a Data Lake ,” there!
Light & Wonder teamed up with the Amazon ML Solutions Lab to use events data streamed from LnW Connect to enable machine learning (ML)-powered predictive maintenance for slot machines. Predictive maintenance is a common ML use case for businesses with physical equipment or machinery assets.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Luckily, we have tried and trusted tools and architectural patterns that provide a blueprint for reliable ML systems. In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. But what is an ML pipeline?
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decisiontree.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression DecisionTrees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? The information from previous decisions is analyzed via the decisiontree.
Vitaly Bondar: ML Team lead in theMind (formerly Neuromation) company with 6 years of experience in ML/AI and almost 20 years of experience in the industry. There are two model architectures underlying the solution, both based on the Catboost implementation of gradient boosting on decisiontrees.
Machine learning (ML) and deep learning (DL) form the foundation of conversational AI development. ML algorithms understand language in the NLU subprocesses and generate human language within the NLG subprocesses. DL, a subset of ML, excels at understanding context and generating human-like responses.
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. DecisionTreesDecisionTrees are non-linear model unlike the logistic regression which is a linear model. Consequently, each brand of the decisiontree will yield a distinct result.
In the last 10 years, AI and ML models have become bigger and more sophisticated — they’re deeper, more complex, with more parameters, and trained on much more data, resulting in some of the most transformative outcomes in the history of machine learning. sub-quadratic with relation to the input sequence length).
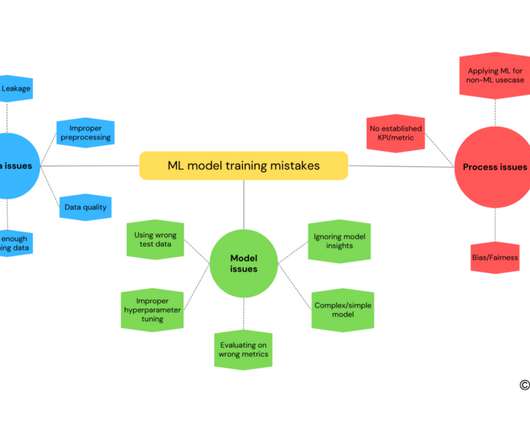
Mind Map: Mistakes in ML model training This blog highlights some important mistakes that one can make while training a machine learning model. What can go wrong in ML model training? It’s important to be aware of these potential issues and take steps to avoid them when training ML models.
As part of its goal to help people live longer, healthier lives, Genomics England is interested in facilitating more accurate identification of cancer subtypes and severity, using machine learning (ML). We provide insights on interpretability, robustness, and best practices of architecting complex ML workflows on AWS with Amazon SageMaker.
ML forms the underlying platform for several new developments. Hence, it has also triggered the demand for ML experts. However, if you are new to the tech domain and want to learn Machine Learning for free, then in this blog, we will take you through the 3 best options to start your ML learning journey. Is ML Coding Hard?
In this blog, I will explain how financial institutions leverage ML to improve their credit risk models and its effect on the outcome. How Does ML Benefit Credit Risk Modelling? Expected Loss: EAD x PD x LGD This entire calculation can be offloaded to ML models, without compromising speed, accuracy or agility.
As Data Scientists, we all have worked on an ML classification model. In this article, we will talk about feasible techniques to deal with such a large-scale ML Classification model. In this article, you will learn: 1 What are some examples of large-scale ML classification models? Let’s take a look at some of them.
Before continuing, revisit the lesson on decisiontrees if you need help understanding what they are. We can compare the performance of the Bagging Classifier and a single DecisionTree Classifier now that we know the baseline accuracy for the test dataset. Bagging is a development of this idea.
The following blog revolves around Regression in Machine Learning and its types. What is Regression in ML? There are various types of regression models ML , each designed for specific scenarios and data types. We want to use decisiontree regression to predict the price of a new house based on its features.
A separate blog post describes the results and winners of the Hindcast Stage , all of whom won prizes in subsequent phases. This blog post presents the winners of all remaining stages: Forecast Stage where models made near-real-time forecasts for the 2024 forecast season.
Multiple models are typically developed as the training proceeds when performing ML and AI tasks, making it challenging to keep track of them. The development of ML and AI benefits greatly from team collaborations. In this article, we’ll show you how to use the R SDK for Comet to build a simple NLP project.
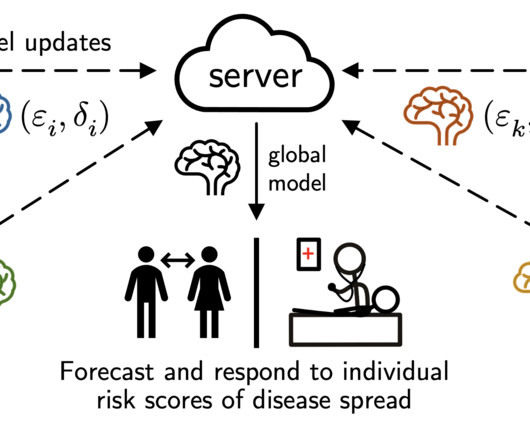
Graphs generally complicate DP : we are often used to ML settings where we can clearly define the privacy granularity and how it relates to an actual individual (e.g. It also preserves the explainability of the underlying ML algorithm as we don’t obfuscate the model weights, updates, or predictions. medical images of patients).
Whether you’re a seasoned tech professional looking to switch lanes, a fresh graduate planning your career trajectory, or simply someone with a keen interest in the field, this blog post will walk you through the exciting journey towards becoming a data scientist. It’s time to turn your question into a quest.
Hence, in this blog, we are going to discuss how to avoid underfitting and overfitting. Training data plays an important role in deciding the effectiveness of an ML model. Most of the time, to avoid the underfitting issue, the ML expert ends up adding too many features to it, leading to overfitting. Thus, impacting the output.
This is where visualizations in ML come in. Graphical representations of structures and data flow within a deep learning model make its complexity easier to comprehend and enable insight into its decision-making process. Data scientists and ML engineers: Creating and training deep learning models is no easy feat.
ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. Introduction In todays world of AI, both Machine Learning (ML) and Deep Learning (DL) are transforming industries, yet many confuse the two. What is Machine Learning?
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. billion in 2022 and is expected to grow to USD 505.42
Apparently, ML algorithms ensure to train of the data enabling the new data input to make compelling predictions and deliver accurate results. Accordingly, Examples of Supervised learning include linear regression, logistic regression , decisiontrees, random forests and neural networks.
Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on learning from what the data science comes up with. Some examples of data science use cases include: An international bank uses ML-powered credit risk models to deliver faster loans over a mobile app. appeared first on IBM Blog.
SageMaker provides containers for its built-in algorithms and prebuilt Docker images for some of the most common machine learning (ML) frameworks, such as Apache MXNet, TensorFlow, PyTorch, and Chainer. This option provides you additional low latency guarantees for ML applications that can’t tolerate cold start latencies.
This article delves into using deep learning to enhance the effectiveness of classic ML models. Background Information Decisiontrees, random forests, and linear regression are just a few examples of classic machine-learning models that have been used extensively in business for years. .
In this blog post, we explore a comprehensive approach to time series forecasting using the Amazon SageMaker AutoMLV2 Software Development Kit (SDK). Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities. .
The road to getting the best-performing hyperparameters includes several trials and experiments, trying new decisions, and analyzing and comparing the results from multiple experiments. With these several trials, it is quite common to lose track of all the combinations that you might have tried out in pursuit of a better ML model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content