This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will explore the details of both approaches and navigate through their differences. A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervisedlearning, works on categorizing existing data. What is Generative AI?
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. This week, we continue that metaphorical (learning) journey with a fun fact. IoT, Web 3.0,
Summary: Machine Learning algorithms enable systems to learn from data and improve over time. Key examples include Linear Regression for predicting prices, Logistic Regression for classification tasks, and DecisionTrees for decision-making. Linear Regression predicts continuous outcomes, like housing prices.
Decisiontrees are a powerful tool for supervisedlearning, and they can be used to solve a wide range of problems, including classification and regression. It is a tree-like model that makes decisions by mapping input data to output labels or numerical values based on a set of rules learned from the training data.
One of the most popular algorithms in Machine Learning are the DecisionTrees that are useful in regression and classification tasks. Decisiontrees are easy to understand, and implement therefore, making them ideal for beginners who want to explore the field of Machine Learning.
Therefore, SupervisedLearning vs Unsupervised Learning is part of Machine Learning. Let’s learn more about supervised and Unsupervised Learning and evaluate their differences. What is SupervisedLearning? What is Unsupervised Learning?
In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the DecisionTree. Image by Author There are other types of learning in Machine Learning, such as semi-supervised and… Read the full blog for free on Medium.
Imagine a world where your business could make smarter decisions, predict customer behavior with astonishing accuracy, and automate tasks that used to take hours of manual labor. That world is not science fiction—it’s the reality of machine learning (ML). Master the machine learning algorithms in this blog 4.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. It identifies hidden patterns in data, making it useful for decision-making across industries. Compared to decisiontrees and SVM, it provides interpretable rules but can be computationally intensive.
Machine learning types Machine learning algorithms fall into five broad categories: supervisedlearning, unsupervised learning, semi-supervisedlearning, self-supervised and reinforcement learning. the target or outcome variable is known). temperature, salary).
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decisiontrees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Machine learning(ML) is evolving at a very fast pace. I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning? The computer model analyses different features with the label.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Let’s dig deeper and learn more about them!
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Let’s dig deeper and learn more about them!
It includes supervised and unsupervised learning. SupervisedLearning deals with labels data and unsupervised learning deals with unlabelled data. Supervisedlearning can be classified into classification and regression where regression deals with continuous values and the former deals with discrete values.
Summary: Entropy in Machine Learning quantifies uncertainty, driving better decision-making in algorithms. It optimises decisiontrees, probabilistic models, clustering, and reinforcement learning. For example, in decisiontree algorithms, entropy helps identify the most effective splits in data.
The remaining features are horizontally appended to the pathology features, and a gradient boosted decisiontree classifier (LightGBM) is applied to achieve predictive analysis. To further improve performance, a self-supervisedlearning-based approach, namely Hierarchical Image Pyramid Transformer (HIPT) ( Chen et al.,
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of data model for Machine Learning, exploring their types. What is Machine Learning?
In this blog, we will delve into the world of classification algorithms, exploring their basics, key algorithms, how they work, advanced topics, practical implementation, and the future of classification in Machine Learning. DecisionTreesDecisionTrees are tree-based models that use a hierarchical structure to classify data.
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. It covers types of Machine Learning, key concepts, and essential steps for building effective models. Common SupervisedLearning tasks include classification (e.g.,
The global Machine Learning market is rapidly growing, projected to reach US$79.29bn in 2024 and grow at a CAGR of 36.08% from 2024 to 2030. This blog aims to clarify the concept of inductive bias and its impact on model generalisation, helping practitioners make better decisions for their Machine Learning solutions.
Solution overview In this post, we demonstrate how to fine-tune a sentence transformer with Amazon product data and how to use the resulting sentence transformer to improve classification accuracy of product categories using an XGBoost decisiontree.
Subcategories of machine learning Some of the most commonly used machine learning algorithms include linear regression , logistic regression, decisiontree , Support Vector Machine (SVM) algorithm, Naïve Bayes algorithm and KNN algorithm. appeared first on IBM Blog.
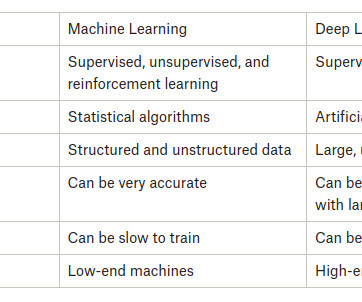
Introduction In todays world of AI, both Machine Learning (ML) and Deep Learning (DL) are transforming industries, yet many confuse the two. This blog explores the difference between Machine Learning and Deep Learning , highlighting their unique characteristics, benefits, and challenges.
Its efficacy may allow kids from a young age to learn Python and explore the field of Data Science. Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you. Why learn Python for Data Science? It includes regression, classification, clustering, decisiontrees, and more.
Summary: The blog discusses essential skills for Machine Learning Engineer, emphasising the importance of programming, mathematics, and algorithm knowledge. Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. The global Machine Learning market was valued at USD 35.80
Graph neural networks (GNNs) have shown great promise in tackling fraud detection problems, outperforming popular supervisedlearning methods like gradient-boosted decisiontrees or fully connected feed-forward networks on benchmarking datasets.
Supervised, unsupervised, and reinforcement learning : Machine learning can be categorized into different types based on the learning approach. Model Complexity Machine Learning : Traditional machine learning models have fewer parameters and a simpler structure than deep learning models.
This comprehensive blog outlines vital aspects of Data Analyst interviews, offering insights into technical, behavioural, and industry-specific questions. It covers essential topics such as SQL queries, data visualization, statistical analysis, machine learning concepts, and data manipulation techniques.
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. Big Data and Machine Learning The intersection of Big Data and Machine Learning is a critical area of focus in a Big Data syllabus.
Summary: The blog explores the synergy between Artificial Intelligence (AI) and Data Science, highlighting their complementary roles in Data Analysis and intelligent decision-making. Introduction Artificial Intelligence (AI) and Data Science are revolutionising how we analyse data, make decisions, and solve complex problems.
Random forest: A tree-based algorithm that uses several decisiontrees on random sub-samples of the data with replacement. The trees are split into optimal nodes at each level. The decisions of each tree are averaged together to prevent overfitting and improve predictions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content