This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this short blog, we’ll review the process of taking a POC data science pipeline (ML/Deeplearning/NLP) that was conducted on Google Colab, and transforming it into a pipeline that can run parallel at scale and works with Git so the team can collaborate on.
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
This makes it easier to move ML projects between development, cloud, or production environments without worrying about differences in setup. These include tools for development environments, deeplearning frameworks, machine learning lifecycle management, workflow orchestration, and large language models. TensorFlow 6.
Whether you’re a researcher, developer, startup founder, or simply an AI enthusiast, these events provide an opportunity to learn from the best, gain hands-on experience, and discover the future of AI. This event offers cutting-edge discussions, hands-on workshops, and deep dives into AI advancements. Lets dive in!
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. This is usually achieved by providing the right set of parameters when using an Estimator.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. This is where visualizations in ML come in.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing data scientists and ML engineers to build, train, and deploy ML models using geospatial data. SageMaker Processing provisions cluster resources for you to run city-, country-, or continent-scale geospatial ML workloads.
Neuron is the SDK used to run deeplearning workloads on Trainium and Inferentia based instances. Datadog, an observability and security platform, provides real-time monitoring for cloud infrastructure and ML operations. If you don’t already have a Datadog account, you can sign up for a free 14-day trial today.
In other words, we all want to get directly into DeepLearning. But this is really a mistake if you want to take studying Machine Learning seriously and get a job in AI. Machine Learning fundamentals are not 100% the same as DeepLearning fundamentals and are perhaps even more important.
Explaining a black box Deeplearning model is an essential but difficult task for engineers in an AI project. However, the term Black box can be seen frequently in Deeplearning as the Black-box models are the ones that are difficult to interpret. Author(s): Chien Vu Originally published on Towards AI.
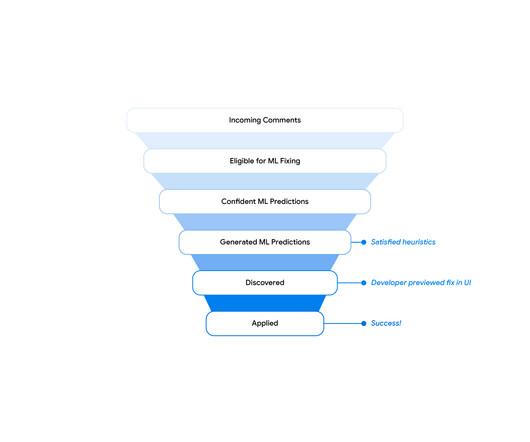
However, with machine learning (ML), we have an opportunity to automate and streamline the code review process, e.g., by proposing code changes based on a comment’s text. As of today, code-change authors at Google address a substantial amount of reviewer comments by applying an ML-suggested edit. 3-way-merge UX in IDE.
Getting Started with Visual Blocks for ML This member-only story is on us. Photo by EJ Strat on Unsplash Visual Blocks for ML is an open-source, visual programming framework developed by Google. ⚡️Continue reading to find out how this framework can help accelerate your ML workflows! Upgrade to access all of Medium.
The explosion in deeplearning a decade ago was catapulted in part by the convergence of new algorithms and architectures, a marked increase in data, and access to greater compute. Top Training efficiency Efficient optimization methods are the cornerstone of modern ML applications and are particularly crucial in large scale settings.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
However, developing and iterating on these ML-based multimedia prototypes can be challenging and costly. It usually involves a cross-functional team of ML practitioners who fine-tune the models, evaluate robustness, characterize strengths and weaknesses, inspect performance in the end-use context, and develop the applications.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
Getting started with SageMaker JumpStart SageMaker JumpStart is a machine learning (ML) hub that can help accelerate your ML journey. About the authors Marc Karp is an ML Architect with the Amazon SageMaker Service team. He focuses on helping customers design, deploy, and manage ML workloads at scale.
In this blog, we will share the list of leading data science conferences across the world to be held in 2023. This will help you to learn and grow your career in data science, AI and machine learning. PAW Climate and DeepLearning World. Top data science conferences 2023 in different regions of the world 1.
Searching for the best AI blog writer to beef up your content strategy? But in this guide, we’ve curated a list of the top 10 AI blog writers to streamline your content creation. From decoding the complex algorithms to highlighting unique features, this article is your one-stop shop for finding the perfect AI blog writer for you.
Challenges in deploying advanced ML models in healthcare Rad AI, being an AI-first company, integrates machine learning (ML) models across various functions—from product development to customer success, from novel research to internal applications. Rad AI’s ML organization tackles this challenge on two fronts.
Now all you need is some guidance on generative AI and machine learning (ML) sessions to attend at this twelfth edition of re:Invent. In addition to several exciting announcements during keynotes, most of the sessions in our track will feature generative AI in one form or another, so we can truly call our track “Generative AI and ML.”
To receive deep insights just like this and more, including top ML papers of the week, job postings, ML tips from real-world experience, and ML stories from researchers and builders, join my newsletter here. This… Read the full blog for free on Medium. Upgrade to access all of Medium.
In today’s rapidly evolving landscape of artificial intelligence, deeplearning models have found themselves at the forefront of innovation, with applications spanning computer vision (CV), natural language processing (NLP), and recommendation systems. If not, refer to Using the SageMaker Python SDK before continuing.
read()) print(json.dumps(response_body, indent=2)) response = requests.get("[link] blog = response.text chat_with_document(blog, "What is the blog writing about?") For the subsequent request, we can ask a different question: chat_with_document(blog, "what are the use cases?")
Model server overview A model server is a software component that provides a runtime environment for deploying and serving machine learning (ML) models. The primary purpose of a model server is to allow effortless integration and efficient deployment of ML models into production systems. For MMEs, each model.py The full model.py
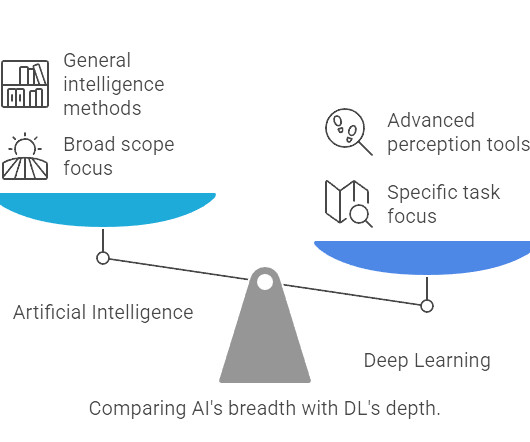
Summary: Artificial Intelligence (AI) and DeepLearning (DL) are often confused. AI vs DeepLearning is a common topic of discussion, as AI encompasses broader intelligent systems, while DL is a subset focused on neural networks. Is DeepLearning just another name for AI? Is all AI DeepLearning?
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. Create a custom container image for ML model training and push it to Amazon ECR.
It’s one of the prerequisite tasks to prepare training data to train a deeplearning model. Specifically, for deeplearning-based autonomous vehicle (AV) and Advanced Driver Assistance Systems (ADAS), there is a need to label complex multi-modal data from scratch, including synchronized LiDAR, RADAR, and multi-camera streams.
By taking care of the undifferentiated heavy lifting, SageMaker allows you to focus on working on your machine learning (ML) models, and not worry about things such as infrastructure. These two crucial parameters influence the efficiency, speed, and accuracy of training deeplearning models.
Open-source packages ¶ While some of the packages below overlap with tools for upstream tasks like diarization and speech recognition, this list focuses on extracting features from speech that are useful for machine learning. Overall, we recommend openSMILE for general ML applications. Journal of Modern Science.
It uses deeplearning to convert audio to text quickly and accurately. Amazon Transcribe offers deeplearning capabilities, which can handle a wide range of speech and acoustic characteristics, in addition to its scalability to process anywhere from a few hundred to over tens of thousands of calls daily, also played a pivotal role.
These improvements are available across a wide range of SageMaker’s DeepLearning Containers (DLCs), including Large Model Inference (LMI, powered by vLLM and multiple other frameworks), Hugging Face Text Generation Inference (TGI), PyTorch (Powered by TorchServe), and NVIDIA Triton.
ONNX ( Open Neural Network Exchange ) is an open-source standard for representing deeplearning models widely supported by many providers. ONNX provides tools for optimizing and quantizing models to reduce the memory and compute needed to run machine learning (ML) models.
Many practitioners are extending these Redshift datasets at scale for machine learning (ML) using Amazon SageMaker , a fully managed ML service, with requirements to develop features offline in a code way or low-code/no-code way, store featured data from Amazon Redshift, and make this happen at scale in a production environment.
For example, marketing and software as a service (SaaS) companies can personalize artificial intelligence and machine learning (AI/ML) applications using each of their customer’s images, art style, communication style, and documents to create campaigns and artifacts that represent them.
Intuitivo, a pioneer in retail innovation, is revolutionizing shopping with its cloud-based AI and machine learning (AI/ML) transactional processing system. Our AI/ML research team focuses on identifying the best computer vision (CV) models for our system. Inferentia has been shown to reduce inference costs significantly.
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. This provides a major flexibility advantage over the majority of ML frameworks, which require neural networks to be defined as static objects before runtime.
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. Arun Kumar Lokanatha is a Senior ML Solutions Architect with the Amazon SageMaker team.
These techniques utilize various machine learning (ML) based approaches. In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience.
Amazon Rekognition people pathing is a machine learning (ML)–based capability of Amazon Rekognition Video that users can use to understand where, when, and how each person is moving in a video. This post discusses an alternative solution to Rekognition people pathing and how you can implement this solution in your applications.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machine learning (ML), and computational science. Given the importance of Jupyter to data scientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
Leverage the Watson NLP library to build the best classification models by combining the power of classic ML, DeepLearning, and Transformed based models. link] Text classification is one of the most used NLP tasks for several use cases like email spam filtering, tagging, and classifying content, blogs, metadata, etc.
Building upon a previous Machine LearningBlog post to create personalized avatars by fine-tuning and hosting the Stable Diffusion 2.1 To learn more, visit our Neuron documentation. James Wu is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content