This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this blog, we will discuss exploratorydataanalysis, also known as EDA, and why it is important. We will also be sharing code snippets so you can try out different analysis techniques yourself. So, without any further ado let’s dive right in. DSD got you covered!
ArticleVideo Book This article was published as a part of the Data Science Blogathon Hi all, this is my first blog hope you all like. The post Performing ExploratoryDataAnalysis with SAS and Python appeared first on Analytics Vidhya.
ChatGPT can also use Wolfram Language to create more complex visualizations, such as interactive charts and 3D models. Source: Stephen Wolfram Writings Read this blog to Master ChatGPT cheatsheet 2. Deploy machine learning Models: You can use the plugin to train and deploy machine learning models.
The importance of EDA in the machine learning world is well known to its users. Making visualizations is one of the finest ways for data scientists to explain dataanalysis to people outside the business. Exploratorydataanalysis can help you comprehend your data better, which can aid in future data preprocessing.
For data scrapping a variety of sources, such as online databases, sensor data, or social media. Cleaning data: Once the data has been gathered, it needs to be cleaned. This involves removing any errors or inconsistencies in the data.
I discuss why I went from five to two plot types in my preliminary EDA. I also have created a Github for all code in this blog. The GitHub… Continue reading on MLearning.ai »
Some projects may necessitate a comprehensive LLMOps approach, spanning tasks from data preparation to pipeline production. ExploratoryDataAnalysis (EDA) Data collection: The first step in LLMOps is to collect the data that will be used to train the LLM.
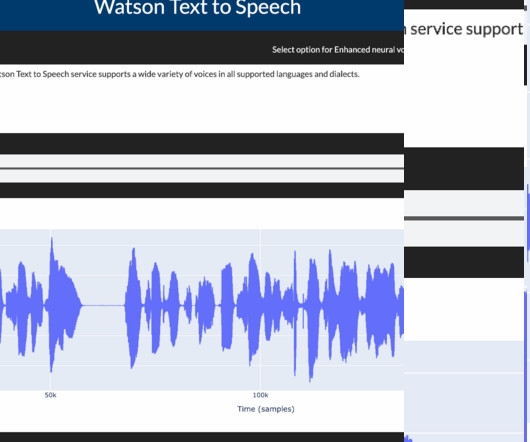
Text to Speech Dash app IBM Watson’s text-to-speech model is built using machine learning techniques and deep neural networks, trained on large amounts of speech and text data. This blog gives an overview of how to convert text data into speech and how to control speech rate & voice pitch using Watson Speech libraries.
According to a report from Statista, the global big data market is expected to grow to over $103 billion by 2027, highlighting the increasing importance of data handling practices. Key Takeaways Data preprocessing is crucial for effective Machine Learning model training. During EDA, you can: Check for missing values.
ExploratoryDataAnalysis(EDA)on Biological Data: A Hands-On Guide Unraveling the Structural Data of Proteins, Part II — ExploratoryDataAnalysis Photo from Pexels In a previous post, I covered the background of this protein structure resolution data set, including an explanation of key data terminology and details on how to acquire the data.
We will carry out some EDA on our dataset, and then we will log the visualizations onto the Comet experimentation website or platform. Time Series Models Time series models are a type of statistical model that are used to analyze and make predictions about data that is collected over time. Without further ado, let’s begin.
And importantly, starting naively annotating data might become a quick solution rather than thinking about how to make uses of limited labels if extracting data itself is easy and does not cost so much. In that case, you tasks have your own problem, and you would have to be careful about your EDA, data cleaning, and labeling.
Today’s question is, “What does a data scientist do.” ” Step into the realm of data science, where numbers dance like fireflies and patterns emerge from the chaos of information. In this blog post, we’re embarking on a thrilling expedition to demystify the enigmatic role of data scientists.
By analyzing the sentiment of users towards certain products, services, or topics, sentiment analysis provides valuable insights that empower businesses and organizations to make informed decisions, gauge public opinion, and improve customer experiences.
Data Extraction, Preprocessing & EDA & Machine Learning Model development Data collection : Automatically download the stock historical prices data in CSV format and save it to the AWS S3 bucket. Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake.
Comet is an MLOps platform that offers a suite of tools for machine-learning experimentation and dataanalysis. It is designed to make it easy to track and monitor experiments and conduct exploratorydataanalysis (EDA) using popular Python visualization frameworks.
Email classification project diagram The workflow consists of the following components: Model experimentation – Data scientists use Amazon SageMaker Studio to carry out the first steps in the data science lifecycle: exploratorydataanalysis (EDA), data cleaning and preparation, and building prototype models.
Python data visualisation libraries offer powerful visualisation tools , ranging from simple charts to interactive dashboards. In this blog, we aim to explore the most popular Python data visualisation libraries, highlight their unique features, and guide you on how to use them effectively.
Figure 7: Using SageMaker Data Wrangler’s chat for data prep to run SQL statements Check for data quality SageMaker Canvas also provides exploratorydataanalysis (EDA) capabilities that allow you to gain deeper insights into the data prior to the ML model build step.
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. Stay tuned for updates and discussions on our blog page blog.oceanprotocol.com for progress throughout the year!
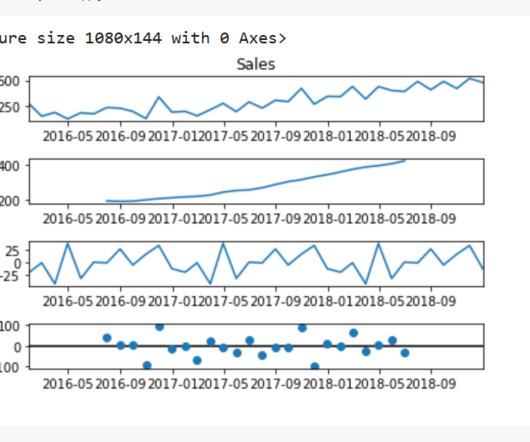
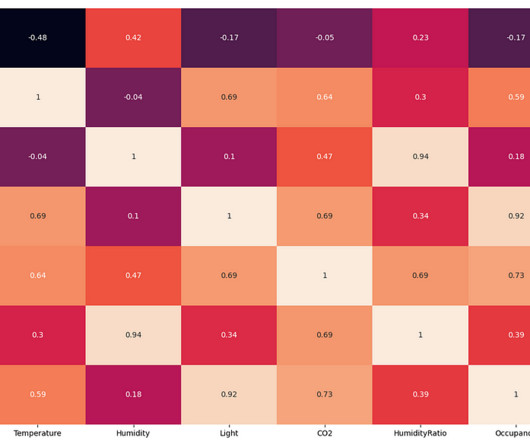
From the above EDA, it is clear that the room's temperature, light, and CO2 levels are good occupancy indicators. The exploratorydataanalysis found that the change in room temperature, CO levels, and light intensity can be used to predict the occupancy of the room in place of humidity and humidity ratio.
I initially conducted detailed exploratorydataanalysis (EDA) to understand the dataset, identifying challenges like duplicate entries and missing Coordinate Reference System (CRS) information.
In order to accomplish this, we will perform some EDA on the Disneyland dataset, and then we will view the visualization on the Comet experimentation website or platform. Another significant aspect of Comet is that it enables us to carry out exploratorydataanalysis. Let’s get started!
We observed during the exploratorydataanalysis (EDA) that as we move from micro-level sales (product level) to macro-level sales (BL level), missing values become less significant.
We use the model preview functionality to perform an initial EDA. This provides us a baseline that we can use to perform data augmentation, generating a new baseline, and finally getting the best model with a model-centric approach using the standard build functionality.
Their primary responsibilities include: Data Collection and Preparation Data Scientists start by gathering relevant data from various sources, including databases, APIs, and online platforms. They clean and preprocess the data to remove inconsistencies and ensure its quality.
For DataAnalysis you can focus on such topics as Feature Engineering , Data Wrangling , and EDA which is also known as ExploratoryDataAnalysis. Because this is the only effective way to learn DataAnalysis. Feature Engineering plays a major part in the process of model building.
Photo by Juraj Gabriel on Unsplash Dataanalysis is a powerful tool that helps businesses make informed decisions. In today’s blog, we will explore the Netflix dataset using Python and uncover some interesting insights.
Vertex AI combines data engineering, data science, and ML engineering into a single, cohesive environment, making it easier for data scientists and ML engineers to build, deploy, and manage ML models. Data Preparation Begin by ingesting and analysing your dataset.
In a typical MLOps project, similar scheduling is essential to handle new data and track model performance continuously. Load and Explore Data We load the Telco Customer Churn dataset and perform exploratorydataanalysis (EDA). Experiment Tracking in CometML (Image by the Author) 2.
This blog will explore the intricacies of AI Time Series Forecasting, its challenges, popular models, implementation steps, applications, tools, and future trends. Making Data Stationary: Many forecasting models assume stationarity. In 2024, the global Time Series Forecasting market was valued at approximately USD 214.6
There are 6 high-level steps in every MLOps project The 6 steps are: Initial data gathering (for exploration). Exploratorydataanalysis (EDA) and modeling. Data and model pipeline development (data preparation, training, evaluation, and so on).
Create DataGrids with image data using Kangas, and load and visualize image data from hugging face Photo by Genny Dimitrakopoulou on Unsplash Visualizing data to carry out a detailed EDA, especially for image data, is critical. We pay our contributors, and we don’t sell ads.
Factor Analysis seeks to identify underlying factors that explain observed correlations among variables, whereas Principal Component Analysis focuses on reducing the dimensionality of data while preserving variance. Read Blog: Statistical Tools for Data-Driven Research. What is Principal Component Analysis?
Central to Pandas is the DataFrame object, a versatile structure for managing and analysing data in tabular form. This blog introduces the Pandas DataFrame.loc method, which is crucial for data selection and manipulation. Data Transformation : Applying functions to columns or rows, and reshaping data.
Blog - Everest Group Requirements gathering: ChatGPT can significantly simplify the requirements gathering phase by building quick prototypes of complex applications. Advise on getting started on topics Recommend get started materials Explain an implementation Explain general concepts in specific industry domain (e.g.
Jump Right To The Downloads Section Scaling Kaggle Competitions Using XGBoost: Part 2 In the previous blog post of this series, we briefly covered concepts like decision trees and gradient boosting, before touching up on the concept of XGBoost. Looking for the source code to this post? Subsequently, we saw how easy it was to use in code. .
As an example for catalogue data, it’s important to check if the set of mandatory fields like product title, primary image, nutritional values, etc. are present in the data. So, we need to build a verification layer that runs based on a set of rules to verify and validate data before preparing it for model training.
In this article, let’s dive deep into the Natural Language Toolkit (NLTK) data processing concepts for NLP data. Before building our model, we will also see how we can visualize this data with Kangas as part of exploratorydataanalysis (EDA). We pay our contributors, and we don’t sell ads.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
We first get a snapshot of our data by visually inspecting it and also performing minimal ExploratoryDataAnalysis just to make this article easier to follow through. In a real-life scenario you can expect to do more EDA, but for the sake of simplicity we’ll do just enough to get a sense of the process.
The reliability of this gold dataset is confirmed through manual validation and extensive ExploratoryDataAnalysis (EDA). Subsequently, LlaMA2 and OpenAI’s GPT-3.5 Then in the second step, we fine-tune a DistilBERT model using the golden dataset to classify severity, action before fall, and reason for fall.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content