This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
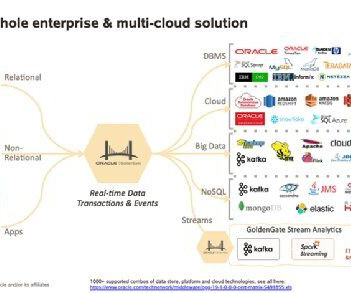
Hadoop is an open-source framework from the Apache Software Foundation and has become one of the leading Big Data management technologies in recent years. This article provides a comprehensive overview of Hadoop and its components. We also examine the underlying architecture and provide practical tips for getting started with it.
Hadoop localhost User Interface. In this article, I will walk you through the simple installation of Hadoop on your local MacBook M1 or M2. Before we get started, I am confident you have a basic awareness of the key terminology in the Hadoop ecosystem. … Read the full blog for free on Medium. Image by the author.
Rockets legacy data science environment challenges Rockets previous data science solution was built around Apache Spark and combined the use of a legacy version of the Hadoop environment and vendor-provided Data Science Experience development tools. This also led to a backlog of data that needed to be ingested.
Hadoop systems and data lakes are frequently mentioned together. Data is loaded into the Hadoop Distributed File System (HDFS) and stored on the many computer nodes of a Hadoop cluster in deployments based on the distributed processing architecture.
Hadoop has become a highly familiar term because of the advent of big data in the digital world and establishing its position successfully. However, understanding Hadoop can be critical and if you’re new to the field, you should opt for Hadoop Tutorial for Beginners. Let’s find out from the blog! What is Hadoop?
Here comes the role of Hive in Hadoop. Hive is a powerful data warehousing infrastructure that provides an interface for querying and analyzing large datasets stored in Hadoop. In this blog, we will explore the key aspects of Hive Hadoop. What is Hadoop ? Thus ensuring optimal performance.
Hadoop emerges as a fundamental framework that processes these enormous data volumes efficiently. This blog aims to clarify Big Data concepts, illuminate Hadoops role in modern data handling, and further highlight how HDFS strengthens scalability, ensuring efficient analytics and driving informed business decisions.
Extract : In this step, data is extracted from a vast array of sources present in different formats such as Flat Files, Hadoop Files, XML, JSON, etc. Here are few best Open-Source ETL tools on the market: Hadoop : Hadoop distinguishes itself as a general-purpose Distributed Computing platform. Conclusion.
One common scenario that we’ve helped many clients with involves migrating data from Hive tables in a Hadoop environment to the Snowflake Data Cloud. In this blog, we’ll explore how to accomplish this task using the Snowflake-Spark connector. Configure security (EC2 key pair). Review settings and launch the cluster.
In this blog post, we will be discussing 7 tips that will help you become a successful data engineer and take your career to the next level. Reading industry blogs, participating in online forums, and attending conferences and meetups are all great ways to stay informed.
Let’s further explore the impact of data in this industry as we count down the top 5 financial services blog posts of 2022. #5 Many institutions need to access key customer data from mainframe applications and integrate that data with Hadoop and Spark to power advanced insights. But what does that look like in practice?
In the next sections of this blog, we will delve deeper into the technical aspects of Distributed Systems in Big Data Engineering, showcasing code snippets to illustrate how these systems work in practice. It provides fault tolerance and high throughput for Big Data storage and processing.
It leverages Apache Hadoop for both storage and processing. select: Projects a… Read the full blog for free on Medium. Apache Spark: Apache Spark is an open-source data processing framework for processing large datasets in a distributed manner. It does in-memory computations to analyze data in real-time.
In this blog, we’ll explore the defining traits, benefits, use cases, and key factors to consider when choosing between SQL and NoSQL databases. Data Storage Systems: Taking a look at Redshift, MySQL, PostGreSQL, Hadoop and others NoSQL Databases NoSQL databases are a type of database that does not use the traditional relational model.
However, a background in data analytics, Hadoop technology or related competencies doesn’t guarantee success in this field. Consider the benefits of blogging. The first tip that he shared was on the benefits of blogging. There are a lot of things that data scientists can blog about.
This blog is about how to configure Single Sign-on(SSO) on IBM SPSS Analytic Server. Together they can provide an integrated predictive analytics platform, using data from Hadoop distributions and Spark applications. Summary This blog provides a detailed explanation of enabling Kerberos authentication on IBM SPSS Analytic Server.
In this blog, we’ll delve deeper into the impact of data analytics on weather forecasting and find out whether it’s worth the hype. Hadoop has also helped considerably with weather forecasting. But if there’s one technology that has revolutionized weather forecasting, it has to be data analytics.
Architecturally the introduction of Hadoop, a file system designed to store massive amounts of data, radically affected the cost model of data. Disruptive Trend #1: Hadoop. More than any other advancement in analytic systems over the last 10 years, Hadoop has disrupted data ecosystems. Subscribe to Alation's Blog.
Prerequisites In this blog, we focus on ingesting data into the Snowflake Data Cloud with GoldenGate and so we will pick up the replication process within GoldenGate. share/hadoop/common/*:hadoop-3.2.1/share/hadoop/common/lib/*:hadoop-3.2.1/share/hadoop/hdfs/*:hadoop-3.2.1/share/hadoop/hdfs/lib/*:hadoop-3.2.1/etc/hadoop/:hadoop-3.2.1/share/hadoop/tools/lib/*
This blog will reveal or show the difference between the data warehouse and the data lake. A big data analytic can work on data lakes with the use of Apache Spark as well as Hadoop. It is vital to know the difference between the two as they serve different principles and need diverse sets of eyes to be adequately optimized.
We decided to address these needs for SQL engines over Hadoop in Alation 4.0. Alation Connect previously synced metadata and query logs from data storage systems including the Hive Metastore on Hadoop and databases from Teradata, IBM, Oracle, SqlServer, Redshift, Vertica, SAP Hana and Greenplum. Subscribe to Alation's Blog.
This blog will guide you through essential considerations when selecting the best Data Science program for your needs. Big Data Technologies: Familiarity with tools like Hadoop and Spark is increasingly important. Key Takeaways Over 25,000 Data Science positions available across various industries.
This blog post features a predictive maintenance use case within a connected car infrastructure, but the discussed components and architecture are helpful in any industry. Contact: kai.waehner@confluent.io / Twitter / LinkedIn.
In this blog, we’ll explore seven key strategies to optimize infrastructure for AI workloads, empowering organizations to harness the full potential of AI technologies. Leveraging distributed storage and processing frameworks such as Apache Hadoop, Spark or Dask accelerates data ingestion, transformation and analysis.
This blog was originally written by Keith Smith and updated for 2023 by Nick Goble & Dominick Rocco. In this blog, we’ll explore what Snowpark is, how it’s evolved over the years, why it’s so important, what pain points it solves, and much more! What is Snowflake’s Snowpark?
These Hadoop based tools archive links and keep track of them. Don’t keep building links to the same page of your site over and over; instead, build links to a mixture of different pages, including your homepage, your internal pages, and your blog posts. But if you want to build authority, you need the help of links.
This blog aims to clarify how map reduces architecture, tackles Big Data challenges, highlights its essential functions, and showcases its relevance in real-world scenarios. Hadoop MapReduce, Amazon EMR, and Spark integration offer flexible deployment and scalability. billion in 2023 and will likely expand at a CAGR of 14.9%
Santosh has authored notable IEEE publications and, as a seasoned tech blog author, he has also made significant contributions to the development of computer vision solutions during his tenure at Samsung. Nanda has over 18 years of experience working in Java/J2EE, Spring technologies, and big data frameworks using Hadoop and Apache Spark.
Google’s Hadoop allowed for unlimited data storage on inexpensive servers, which we now call the Cloud. In this blog post, we will discuss the five best server backup software solutions that businesses can consider in 2023. Searching for a topic on a search engine can provide us with a vast amount of information in seconds.
Recently I engaged in a guided “hands-on” evaluation of Infoworks, a “no code” big data engineering solution that expedites and automates Hadoop and cloud workflows. by Jen Underwood. Within four hours of logging. Read More.
In this blog, we will discuss: What is the Open Table format (OTF)? The Hive format helped structure and partition data within the Hadoop ecosystem, but it had limitations in terms of flexibility and performance. Why should we use it? A Brief History of OTF A comparative study between the major OTFs. What is an Open Table Format?
With the year coming to a close, many look back at the headlines that made major waves in technology and big data – from Spark to Hadoop to trends in data science – the list could go on and on. However, most are only deployed over one data store (Hadoop or other various backends). Subscribe to Alation's Blog.
With blogs, anyone can now write and distribute an article and with message boards anyone can post an advertisement. Whether using Tableau, Informatica, Excel, MicroStrategy, Hadoop or Teradata to store or prepare data, data is all over the place. Subscribe to Alation's Blog. Publishing used to be the province of big newspapers.
Alation does a deep parse of the usage logs on the database tables or Hadoop structures that power a MicroStrategy visualization to capture how often those assets have been used and who in the organization are the experts on that resource. Subscribe to Alation's Blog. Get the latest data cataloging news and trends in your inbox.
“Setting up Hadoop on-premises was a huge undertaking. Contrast this with the large on-prem installations of the past: “Nearly every large organization adopted Hadoop and [is now] transitioning away from its pain and expense,” says analyst Daniel Kirsch. Subscribe to Alation's Blog.
Summary: This blog delves into the multifaceted world of Big Data, covering its defining characteristics beyond the 5 V’s, essential technologies and tools for management, real-world applications across industries, challenges organisations face, and future trends shaping the landscape.
Prior to joining AWS, Archana led a migration from traditional siloed data sources to Hadoop at a healthcare company. She has over a decade of cross-industry expertise leading strategic technical initiatives. Archana is an aspiring member of the AI/ML technical field community at AWS.
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
And you should have experience working with big data platforms such as Hadoop or Apache Spark. Your skill set should include the ability to write in the programming languages Python, SAS, R and Scala. Together, watsonx offers organizations the ability to: Train, tune and deploy AI across your business with watsonx.ai
In this blog, well explore the best data engineering tools that make data work easier, faster, and more reliable. Apache Hive Apache Hive is a data warehouse tool that allows users to query and analyse large datasets stored in Hadoop. Hadoop : An open-source framework for processing Big Data across multiple servers.
In this blog, we will explore the arena of data science bootcamps and lay down a guide for you to choose the best data science bootcamp. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. What do Data Science Bootcamps Offer?
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. Big Data Processing: Apache Hadoop, Apache Spark, etc.
Whether you’re a seasoned tech professional looking to switch lanes, a fresh graduate planning your career trajectory, or simply someone with a keen interest in the field, this blog post will walk you through the exciting journey towards becoming a data scientist. It’s time to turn your question into a quest.
And for searching the term you landed on multiple blogs, articles as well YouTube videos, because this is a very vast topic, or I, would say a vast Industry. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ Data Science ’.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content