This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of the most effective methods to perform ANN search is to use KD-Trees (K-Dimensional Trees). KD-Trees are a type of binary search tree that partitions data points into k-dimensional space, allowing for efficient querying of nearestneighbors. Traditional exact nearestneighbor search methods (e.g.,
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. IoT, Web 3.0,
In this blog, we will discuss one of the feature transformation techniques called feature scaling with examples and see how it will be the game changer for our machine learning model accuracy. It is the process that normalizes the range of input columns and makes it useful for further visualization and machine learning model training.
In this blog, we will explore the details of both approaches and navigate through their differences. These methodologies represent distinct paradigms in AI, each with unique capabilities and applications. Yet the crucial question arises: Which of these emerges as the foremost driving force in AI innovation? What is Generative AI?
We will discuss KNNs, also known as K-Nearest Neighbours and K-Means Clustering. K-NearestNeighbors (KNN) is a supervised ML algorithm for classification and regression. The black line running through the data points is the regression line, which represents the… Read the full blog for free on Medium.
This blog delves into the technical details of how vec t o r d a ta b a s e s empower patient sim i l a r i ty searches and pave the path for improved diagnosis. Nearestneighbor search algorithms : Efficiently retrieving the closest patient vec t o r s to a given query.
This blog explores types of classification tasks, popular algorithms, methods for evaluating performance, real-world applications, and why classifiers are indispensable in Machine Learning. K-NearestNeighbors (KNN) KNN assigns class labels based on the majority vote of nearestneighbors in the dataset.
In this blog post, well dive into the various scenarios for how Cohere Rerank 3.5 It supports advanced features such as result highlighting, flexible pagination, and k-nearestneighbor (k-NN) search for vector and semantic search use cases.
However, after seeing its significant progress, I compiled it as a blog post so everyone else interested can benefit from it. self.index.add(self.embeddings_vec) def topk(self, vector, k = 4): """ A function that takes in a vector and an optional parameter k and returns the indices of the knearestneighbors in the index.
The KNearestNeighbors (KNN) algorithm of machine learning stands out for its simplicity and effectiveness. This blog aims to familiarise you with the fundamentals of the KNN algorithm in machine learning and its importance in shaping modern data analytics methodologies. What are KNearestNeighbors in Machine Learning?
If you haven’t set up a SageMaker Studio domain, see this Amazon SageMaker blog post for instructions on setting up SageMaker Studio for individual users. To search against the database, you can use a vector search, which is performed using the k-nearestneighbors (k-NN) algorithm.
The KNN (KNearestNeighbors) algorithm analyzes all available data points and classifies this data, then classifies new cases based on these established categories. Click to learn more about author Kartik Patel. In this article, we will discuss the KNN Classification method of analysis. What Is the KNN Classification Algorithm?
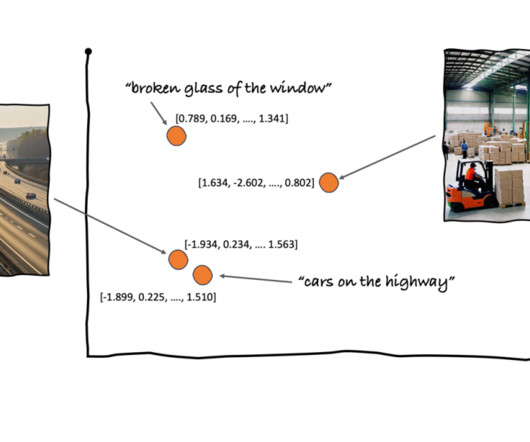
This is the k-nearestneighbor (k-NN) algorithm. In k-NN, you can make assumptions around a data point based on its proximity to other data points. You can use the embedding of an article and check the similarity of the article against the preceding embeddings.
Retrieval (and reranking) strategy FloTorch used a retrieval strategy with a k-nearestneighbor (k-NN) of five for retrieved chunks. Each provisioned node was r7g.4xlarge, 4xlarge, selected for its availability and sufficient capacity to meet the performance requirements. FloTorch used HSNW indexing in OpenSearch Service.
This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples. k-NearestNeighbors (k-NN) k-NN is a simple algorithm that classifies new instances based on the majority class among its knearest neighbours in the training dataset.
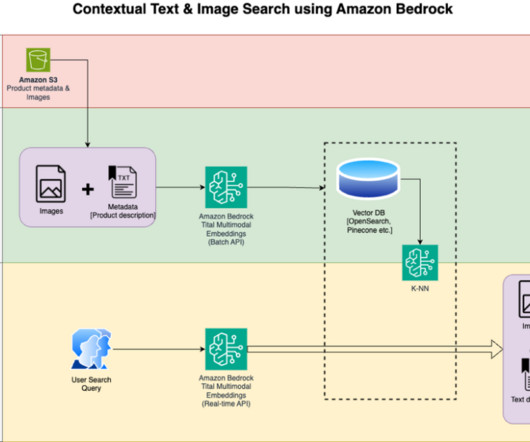
In this two-part blog post series, we explore the key opportunities OfferUp embraced on their journey to boost and transform their existing search solution from traditional lexical search to modern multimodal search powered by Amazon Bedrock and Amazon OpenSearch Service.
The embedded image is stored in an OpenSearch index with a k-nearestneighbors (k-NN) vector field. Example with a multimodal embedding model The following is a code sample performing ingestion with Amazon Titan Multimodal Embeddings as described earlier.
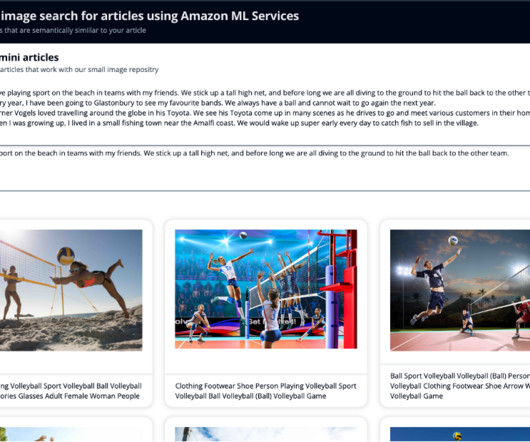
You also generate an embedding of this newly written article, so that you can search OpenSearch Service for the nearest images to the article in this vector space. Using the k-nearestneighbors (k-NN) algorithm, you define how many images to return in your results.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes Support Vector Machines Learning Vector Quantization K-nearestNeighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
A k-NearestNeighbor (k-NN) index is enabled to allow searching of embeddings from the OpenSearch Service. Three separate endpoints using the recommended default SageMaker instance types are deployed.
In this short blog, were diving deep into vector databases what they are, how they work, and, most importantly, how to use them like a pro. But heres the catch scanning millions of vectors one by one (a brute-force k-NearestNeighbors or KNN search) is painfully slow. Traditional databases? They tap out.
Classification algorithms include logistic regression, k-nearestneighbors and support vector machines (SVMs), among others. AI studio The post Five machine learning types to know appeared first on IBM Blog. Naïve Bayes classifiers —enable classification tasks for large datasets. Explore the watsonx.ai
We detail the steps to use an Amazon Titan Multimodal Embeddings model to encode images and text into embeddings, ingest embeddings into an OpenSearch Service index, and query the index using the OpenSearch Service k-nearestneighbors (k-NN) functionality.
In this blog, we will delve into the world of classification algorithms, exploring their basics, key algorithms, how they work, advanced topics, practical implementation, and the future of classification in Machine Learning. Instead, they memorise the training data and make predictions by finding the nearest neighbour.
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
This can be especially useful when recommending blogs, news articles, and other text-based content. K-NearestNeighborK-nearestneighbor (KNN) ( Figure 8 ) is an algorithm that can be used to find the closest points for a data point based on a distance measure (e.g.,
On Line 28 , we sort the distances and select the top knearestneighbors. This demonstrates the efficiency of the LSH in finding nearestneighbors compared to more straightforward, brute-force methods (e.g., -NN Finally, on Lines 32-37 , we measure the time taken to perform the -NN search and print the results.
The function then searches the OpenSearch Service image index for images matching the celebrity name and the k-nearestneighbors for the vector using cosine similarity using Exact k-NN with scoring script. The function generates an embedding of the summarized article using the Amazon Titan Multimodal Embeddings model.
The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. It aims to partition a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean. Hence, it is considered as one of the best-unsupervised learning algorithms.
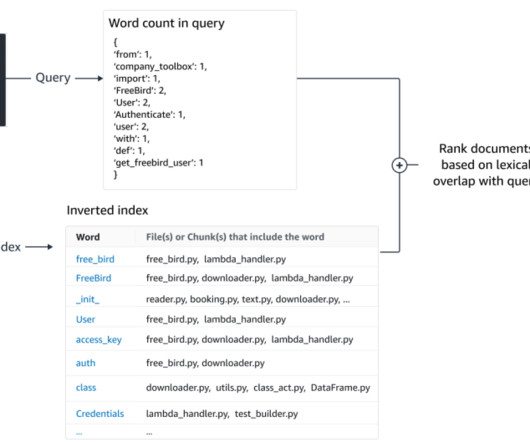
Formally, often k-nearestneighbors (KNN) or approximate nearestneighbor (ANN) search is often used to find other snippets with similar semantics. Semantic retrieval BM25 focuses on lexical matching.
KNearest Neighbour is an algorithm that stores all the available observations and classifies the new data based on a similarity measure. The post Using KNearest Neighbours algorithm in scenario tuning appeared first on SAS Blogs.
You store the embeddings of the video frame as a k-nearestneighbors (k-NN) vector in your OpenSearch Service index with the reference to the video clip and the frame in the S3 bucket itself (Step 3). You split the video files into frames and save them in a S3 bucket (Step 1).
In this post, we present a solution to handle OOC situations through knowledge graph-based embedding search using the k-nearestneighbor (kNN) search capabilities of OpenSearch Service. The IMDb-Knowledge-Graph-Blog/part3-out-of-catalog/run_imdb_demo.py Solution overview.
Instead of treating each input as entirely unique, we can use a distance-based approach like k-nearestneighbors (k-NN) to assign a class based on the most similar examples surrounding the input. To make this work, we need to transform the textual interactions into a format that allows algebraic operations.
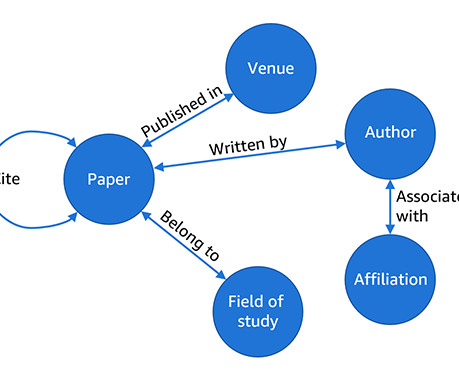
To solve the problem of finding the field of study for any given paper, simply perform a k-nearestneighbor search on the embeddings. In this case, the model reaches an MRR of 0.31 on the test set of the constructed graph. python3 -m graphstorm.run.gs_link_prediction --inference --num_trainers 8 --part-config /data/oagv2.1/mag_bert_constructed/mag.json
We perform a k-nearestneighbor (k=1) search to retrieve the most relevant embedding matching the user query. Setting k=1 retrieves the most relevant slide to the user question. The user input is converted into embeddings using the Titan Multimodal Embeddings model accessed via Amazon Bedrock.
⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ? In contrast, for datasets with low dimensionality, simpler algorithms such as Naive Bayes or K-NearestNeighbors may be sufficient.
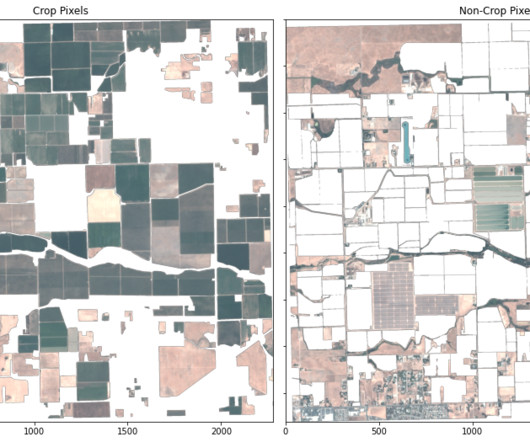
In this analysis, we use a K-nearestneighbors (KNN) model to conduct crop segmentation, and we compare these results with ground truth imagery on an agricultural region. For more information about Planet, including its existing data products and upcoming product releases, visit [link].
We perform a k-nearestneighbor (k-NN) search to retrieve the most relevant embeddings matching the user query. The user input is converted into embeddings using the Amazon Titan Text Embeddings model accessed using Amazon Bedrock. An OpenSearch Service vector search is performed using these embeddings.
Hey guys, we will see some of the Best and Unique Machine Learning Projects for final year engineering students in today’s blog. This is going to be a very interesting blog, so without any further due, let’s do it… 1. Self-Organizing Maps In this blog, we will see how we can implement self-organizing maps in Python.
Hey guys, we will see some of the Best and Unique Machine Learning Projects with Source Codes in today’s blog. Youtube Comments Extraction and Sentiment Analysis Flask App Hey, guys in this blog we will implement Youtube Comments Extraction and Sentiment Analysis in Python using Flask. This is going to be a very short blog.
In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. Python is still one of the most popular programming languages that developers flock to. Some are well-known names, and others are known within their communities.
The indexing process consists of the following stages: Document preprocessing – Clean and normalize text from various sources Chunking – Break documents into manageable pieces (1,200 tokens with 50-token overlap) Vectorization – Convert text chunks into vector representations using an embeddings model Storage – Index vectors and metadata in the database (..)
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content