This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
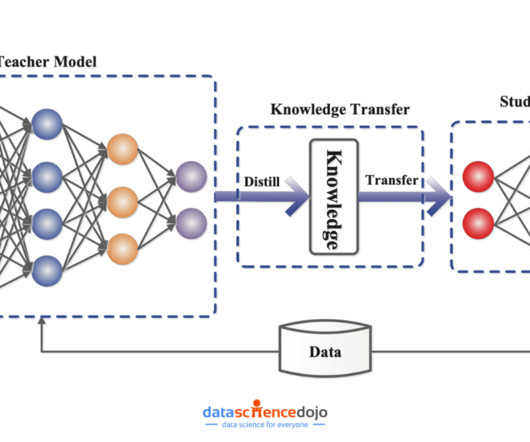
It addresses this issue by enabling a smaller, efficient model to learn from a larger, complex model, maintaining similar performance with reduced size and speed. This blog provides a beginner-friendly explanation of k nowledge distillation , its benefits, real-world applications, challenges, and a step-by-step implementation using Python.
In this blog, we will explore the details of both approaches and navigate through their differences. A visual representation of discriminative AI – Source: Analytics Vidhya Discriminative modeling, often linked with supervisedlearning, works on categorizing existing data. What is Generative AI?
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. The two main approaches of interest for embeddings include unsupervised and supervisedlearning.
1, Data is the new oil, but labeled data might be closer to it Even though we have been in the 3rd AI boom and machine learning is showing concrete effectiveness at a commercial level, after the first two AI booms we are facing a problem: lack of labeled data or data themselves. That is, is giving supervision to adjust via.
Hence, acting as a translator it converts human language into a machine-readable form. These embeddings when particularly used for naturallanguageprocessing (NLP) tasks are also referred to as LLM embeddings. The two main approaches of interest for embeddings include unsupervised and supervisedlearning.
From virtual assistants like Siri and Alexa to personalized recommendations on streaming platforms, chatbots, and language translation services, language models surely are the engines that power it all. If the goal is a creative and informative content generation, Llama 2 is the ideal choice.
Pixabay: by Activedia Image captioning combines naturallanguageprocessing and computer vision to generate image textual descriptions automatically. The CNN is typically trained on a large-scale dataset, such as ImageNet, using techniques like supervisedlearning.
These include image recognition, naturallanguageprocessing, autonomous vehicles, financial services, healthcare, recommender systems, gaming and entertainment, and speech recognition. They are capable of learning and improving over time as they are exposed to more data.
These powerful neural networks learn to compress data into smaller representations and then reconstruct it back to its original form. In this blog, we will explore what autoencoders are, how they work, their various types, and real-world applications. Can I Use Autoencoders for SupervisedLearning Tasks?
And retailers frequently leverage data from chatbots and virtual assistants, in concert with ML and naturallanguageprocessing (NLP) technology, to automate users’ shopping experiences. Semi-supervisedlearning The fifth type of machine learning technique offers a combination between supervised and unsupervised learning.
2022 was a big year for AI, and we’ve seen significant advancements in various areas – including naturallanguageprocessing (NLP), machine learning (ML), and deep learning. Unsupervised and self-supervisedlearning are making ML more accessible by lowering the training data requirements.
In recent years, naturallanguageprocessing and conversational AI have gained significant attention as technologies that are transforming the way we interact with machines and each other. It is a significant initial step towards the objective of supporting 1,000 languages.
At its core, a Large Language Model (LLM) is a sophisticated machine learning entity adept at executing a myriad of naturallanguageprocessing (NLP) activities. This includes tasks like text generation, classification, engaging in dialogue, and even translating text across languages. What is LLM in AI?
Machine learning(ML) is evolving at a very fast pace. I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning? The computer model analyses different features with the label.
The answer lies in the various types of Machine Learning, each with its unique approach and application. In this blog, we will explore the four primary types of Machine Learning: SupervisedLearning, UnSupervised Learning, semi-SupervisedLearning, and Reinforcement Learning.
The core process is a general technique known as self-supervisedlearning , a learning paradigm that leverages the inherent structure of the data itself to generate labels for training. Fine-tuning may involve further training the pre-trained model on a smaller, task-specific labeled dataset, using supervisedlearning.
Word2vec is useful for various naturallanguageprocessing (NLP) tasks, such as sentiment analysis, named entity recognition, and machine translation. Set the learning mode hyperparameter to supervised. BlazingText has both unsupervised and supervisedlearning modes. Start training the model.
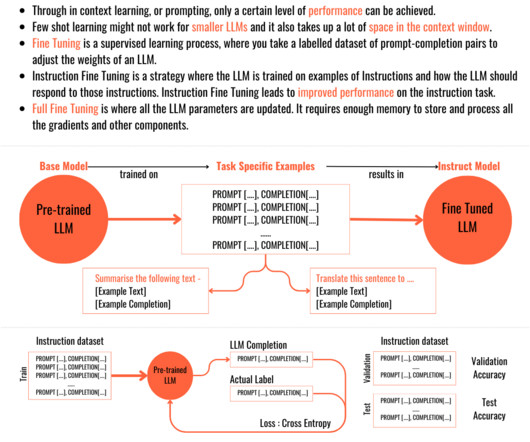
While I post the list in this blog, I’m also maintaining a “live” list that is detailed and will keep on updating. Supervised Fine Tuning Fine Tuning is a supervisedlearningprocess, where you take a labelled dataset of prompt-completion pairs to adjust the weights of an LLM. Examples: GPT 3.5,
This blog post discusses circumstances of youth suicide, which can be upsetting and difficult to discuss. His research focuses on applying naturallanguageprocessing techniques to extract information from unstructured clinical and medical texts, especially in low-resource settings.
A lot of people are building truly new things with Large Language Models (LLMs), like wild interactive fiction experiences that weren’t possible before. But if you’re working on the same sort of NaturalLanguageProcessing (NLP) problems that businesses have been trying to solve for a long time, what’s the best way to use them?
Fine-tuning large language models (LLMs) has become a powerful technique for achieving impressive performance in various naturallanguageprocessing tasks. Additionally, few-shot learning requires maintaining a large context window, which can be resource-intensive and impractical for memory-constrained environments.
Transformers made self-supervisedlearning possible, and AI jumped to warp speed,” said NVIDIA founder and CEO Jensen Huang in his keynote address this week at GTC. Transformers are in many cases replacing convolutional and recurrent neural networks (CNNs and RNNs), the most popular types of deep learning models just five years ago.
Foundation models are large AI models trained on enormous quantities of unlabeled data—usually through self-supervisedlearning. This process results in generalized models capable of a wide variety of tasks, such as image classification, naturallanguageprocessing, and question-answering, with remarkable accuracy.
They consist of interconnected nodes that learn complex patterns in data. Different types of neural networks, such as feedforward, convolutional, and recurrent networks, are designed for specific tasks like image recognition, NaturalLanguageProcessing, and sequence modelling.
With a foundation model, often using a kind of neural network called a “transformer” and leveraging a technique called self-supervisedlearning, you can create pre-trained models for a vast amount of unlabeled data. But that’s all changing thanks to pre-trained, open source foundation models.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
This innovative approach is transforming applications in computer vision, NaturalLanguageProcessing, healthcare, and more. Introduction Zero-Shot Learning (ZSL) is revolutionising Artificial Intelligence by enabling models to classify new categories without prior training data.
Foundation models are AI models trained with machine learning algorithms on a broad set of unlabeled data that can be used for different tasks with minimal fine-tuning. The model can apply information it’s learned about one situation to another using self-supervisedlearning and transfer learning.
As technology continues to impact how machines operate, Machine Learning has emerged as a powerful tool enabling computers to learn and improve from experience without explicit programming. In this blog, we will delve into the fundamental concepts of data model for Machine Learning, exploring their types.
Summary: This blog delves into five prominent AI models: foundation models, Large Language Models, multimodal models, diffusion models, and generative adversarial networks. This blog explores five prominent AI models, detailing their functions, applications, and real-world examples. How do Large Language Models Work?
Summary: This blog covers 15 crucial artificial intelligence interview questions, ranging from fundamental concepts to advanced techniques. In this blog post, we will explore 15 essential artificial intelligence interview questions that cover a range of topics, from fundamental principles to cutting-edge techniques.
While artificial intelligence (AI), machine learning (ML), deep learning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. This blog post will clarify some of the ambiguity. Learn more about watsonx.ai
Large language models (LLMs) are a class of foundational models (FM) that consist of layers of neural networks that have been trained on these massive amounts of unlabeled data. Large language models (LLMs) have taken the field of AI by storm.
This supervisedlearning algorithm supports transfer learning for all pre-trained models available on Hugging Face. He has experience in working on a diverse range of machine learning problems within the domain of naturallanguageprocessing, computer vision, and time series analysis.
Text annotation Text annotation is the process of adding structured information to unstructured text data in order to make it more understandable and useful for downstream applications. The resulting annotated text data can then be used to train and improve the accuracy of LLM models for specific naturallanguageprocessing tasks.
This blog will delve into deep belief network examples, highlighting their role in feature extraction and dimensionality reduction. DBNs learn to represent data by modelling complex distributions through a hierarchical structure. The network learns from labelled data during fine-tuning to minimise the prediction error.
Large language models A large language model refers to any model that undergoes training on extensive and diverse datasets, typically through self-supervisedlearning at a large scale, and is capable of being fine-tuned to suit a wide array of specific downstream tasks.
They require human expertise to tell a machine about the different data types to help Artificial Intelligence learn it. Both labeled and unlabeled data are used in Machine Learning for different purposes. Read the blog below to learn more about how data labeling works and gain an understanding of the use cases.
Foundation models can be trained to perform tasks such as data classification, the identification of objects within images (computer vision) and naturallanguageprocessing (NLP) (understanding and generating text) with a high degree of accuracy. The platform comprises three powerful products: The watsonx.ai
There are two types of Machine Learning techniques, including supervised and unsupervised learning. The following blog will focus on Unsupervised Machine Learning Models focusing on the algorithms and types with examples. Unsupervised learning is preferable as it is easier to get unlabeled data than labeled data.
Train an ML model on the preprocessed images, using a supervisedlearning approach to teach the model to distinguish between different skin types. Jake Wen is a Solutions Architect at AWS, driven by a passion for Machine Learning, NaturalLanguageProcessing, and Deep Learning.
Summary: Data annotation is crucial for training Machine Learning models by adding meaningful labels to raw data. This blog covers the importance, types, techniques, best practices, and challenges, highlighting its role in enhancing AI accuracy and decision-making across various industries.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Let’s take a closer look at their purposes briefly.
Reminder : Training data refers to the data used to train an AI model, and commonly there are three techniques for it: Supervisedlearning: The AI model learns from labeled data, which means that each data point has a known output or target value. Let’s take a closer look at their purposes briefly.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content