This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By following best practices in algorithm selection, data preprocessing, model evaluation, and deployment, we unlock the true potential of machine learning and pave the way for innovation and success. In this blog, we focus on machine learning practices—the essential steps that unlock the potential of this transformative technology.
Fitting a SupportVectorMachine (SVM) Model - Learn how to fit a supportvectormachine model and use your model to score new data In Part 6, Part 7, Part 9, Part 10, and Part 11 of this series, we fit a logistic regression, decision tree, random forest, gradient [.]
Image Credit: Pinterest – Problem solving tools In last week’s post , DS-Dojo introduced our readers to this blog-series’ three focus areas, namely: 1) software development, 2) project-management, and 3) data science. Digital tech created an abundance of tools, but a simple set can solve everything. IoT, Web 3.0,
Feature Engineering encompasses a diverse array of techniques, including Feature Transformation, Feature Construction, Feature Selection, Feature Scaling, and Feature Extraction, each playing a crucial role in refining and optimizing the representation of data for machine learning tasks.
In this blog, we will explore the details of both approaches and navigate through their differences. These methodologies represent distinct paradigms in AI, each with unique capabilities and applications. Yet the crucial question arises: Which of these emerges as the foremost driving force in AI innovation? What is Generative AI?
Clustering in Machine Learning stands as a fundamental unsupervised learning task, different from its supervised counterparts due to the lack of labeled data. As… Read the full blog for free on Medium. Join thousands of data leaders on the AI newsletter.
These intelligent predictions are powered by various Machine Learning algorithms. This blog explores various types of Machine Learning algorithms, illustrating their functionalities and applications with relevant examples. Key Takeaways Machine Learning enables systems to learn from data without explicit programming.
This blog aims to explain associative classification in data mining, its applications, and its role in various industries. Comparison with Other Classification Techniques Associative classification differs from traditional classification methods like decision trees and supportvectormachines (SVM).
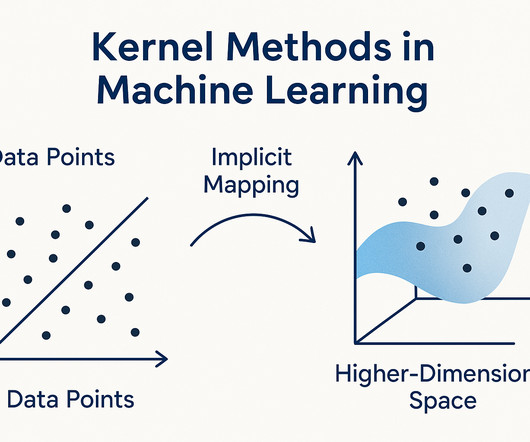
This is where kernel methods in machine learning come in like superheroes. Think of them as magic glasses that help machines see patterns better. In this blog, Ill walk you through these methods, how they work, and why they matterall in simple words. Frequently Asked Questions What are kernel methods in machine learning?
In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering. For beginners, it can seem daunting to dive into the world of data mining, but by following the tips outlined in this blog post, they can start their journey on the right foot.
A few standout topics include model deployment and inferencing, MLOps, and multi-cloud machine learning. These videos are a part of the ODSC/Microsoft AI learning journe y which includes videos, blogs, webinars, and more. It is particularly good at image classification, for instance, deciding whether a picture contains a cat.
Machine learning(ML) is evolving at a very fast pace. I am starting a series with this blog, which will guide a beginner to get the hang of the ‘Machine learning world’. Photo by Andrea De Santis on Unsplash So, What is Machine Learning?
In this blog, we will explore the basics of categorical data. Machine Learning Models: Algorithms like linear regression, decision trees, and supportvectormachines can benefit from the ordered numerical representation of ordinal features. What is Categorical Data?
Machine Learning models play a crucial role in this process, serving as the backbone for various applications, from image recognition to natural language processing. In this blog, we will delve into the fundamental concepts of data model for Machine Learning, exploring their types. What is Machine Learning?
⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ? For larger datasets, more complex algorithms such as Random Forest, SupportVectorMachines (SVM), or Neural Networks may be more suitable.
Classification algorithms include logistic regression, k-nearest neighbors and supportvectormachines (SVMs), among others. AI studio The post Five machine learning types to know appeared first on IBM Blog. Naïve Bayes classifiers —enable classification tasks for large datasets. Explore the watsonx.ai
In this blog we’ll go over how machine learning techniques, powered by artificial intelligence, are leveraged to detect anomalous behavior through three different anomaly detection methods: supervised anomaly detection, unsupervised anomaly detection and semi-supervised anomaly detection.
Summary: This blog highlights ten crucial Machine Learning algorithms to know in 2024, including linear regression, decision trees, and reinforcement learning. Introduction Machine Learning (ML) has rapidly evolved over the past few years, becoming an integral part of various industries, from healthcare to finance.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
One of the most fundamental and widely used techniques in Machine Learning is classification. In this blog, we will delve into the world of classification algorithms, exploring their basics, key algorithms, how they work, advanced topics, practical implementation, and the future of classification in Machine Learning.
The main focus of this blog is to explore a range of statistical and machine learning methods that can be utilized for detecting anomalies in data. In this blog, we covered various statistical and machine learning methods for identifying outliers in your data, and also implemented these methods using Python code.
Moreover, random forest models as well as supportvectormachines (SVMs) are also frequently applied. Langen H, Huber M (2023) How causal machine learning can leverage marketing strategies: Assessing and improving the performance of a coupon campaign. PLoS ONE 18(1): e0278937. link] pone.0278937
Model Training We train multiple machine learning models, including Logistic Regression, Random Forest, Gradient Boosting, and SupportVectorMachine. SupportVectorMachine (svm): Versatile model for linear and non-linear data. These models serve as the basis for our ensemble approach.
Machine Learning algorithms, including Naive Bayes, SupportVectorMachines (SVM), and deep learning models, are commonly used for text classification. Gather a dataset of customer support tickets with different categories, such as billing, technical issues, or product inquiries. What is a text mining algorithm?
Classification algorithms like supportvectormachines (SVMs) are especially well-suited to use this implicit geometry of the data. The previous visualization of the embeddings space displayed only a 2D transformation of this space. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. The blog will take you on a journey to know more about these algorithms and unfold a comparison of Classification vs. Clustering. What is Classification? Hence, the assumption causes a problem.
NRE is a complex task that involves multiple steps and requires sophisticated machine learning algorithms like Hidden Markov Models (HMMs) , Conditional Random Fields (CRFs), and SupportVectorMachines (SVMs) be present. synonyms). We pay our contributors, and we don’t sell ads.
Schematic diagram of the overall framework of Emotion Recognition System [ Source ] The models that are used for AI emotion recognition can be based on linear models like SupportVectorMachines (SVMs) or non-linear models like Convolutional Neural Networks (CNNs). We pay our contributors, and we don’t sell ads.
Subcategories of machine learning Some of the most commonly used machine learning algorithms include linear regression , logistic regression, decision tree , SupportVectorMachine (SVM) algorithm, Naïve Bayes algorithm and KNN algorithm. appeared first on IBM Blog.
With the global Machine Learning market projected to grow from USD 26.03 This blog explores their types, tuning techniques, and tools to empower your Machine Learning models. They vary significantly between model types, such as neural networks , decision trees, and supportvectormachines.
The next step is to use the supportvectormachines (SVMs) method to further improve the accuracy of the identified stops and also to distinguish stops with engagements with a POI vs. stops without one (such as home or work).
Summary: Linear Algebra is foundational to Machine Learning, providing essential operations such as vector and matrix manipulations. By understanding Linear Algebra operations, practitioners can better grasp how Machine Learning models work, optimize their performance, and implement various algorithms effectively.
Machine learning for text extraction with Python is one of the best combos out there for this task. In this blog post, we’ll talk about how one can use Machine learning and Python to perform text extraction with the highest level of accuracy. With it, we can extract textual material from unstructured data quite effortlessly.
In this blog, we’re going to take a look at some of the top Python libraries of 2023 and see what exactly makes them tick. Python is still one of the most popular programming languages that developers flock to. Some are well-known names, and others are known within their communities.
It is possible to improve the performance of these algorithms with machine learning algorithms such as SupportVectorMachines. Another advantage is that these algorithms are not limited to working independently. One critical factor when using a model is whether it can easily be interpreted and tweaked accordingly.
Machine learning algorithms like Naïve Bayes and supportvectormachines (SVM), and deep learning models like convolutional neural networks (CNN) are frequently used for text classification.
In our previous vision blog , we playfully, and accurately, described the volume of global AI research publications as a firehose — of incredibly high volume, but a medium which prevents one from quenching their thirst properly. They represent the vernacular of papers generally.
The following code snippet demonstrates how to aggregate raster data to administrative vector boundaries: import geopandas as gp import numpy as np import pandas as pd import rasterio from rasterstats import zonal_stats import pandas as pd def get_proportions(inRaster, inVector, classDict, idCols, year): # Reading In Vector File if '.parquet'
You can also sign up to receive our weekly newsletter ( Deep Learning Weekly ), check out the Comet blog , join us on Slack , and follow Comet on Twitter and LinkedIn for resources, events, and much more that will help you build better ML models, faster. If you'd like to contribute, head on over to our call for contributors.
This blog will explore the basics of the Perceptron, the mathematics behind it, how it is trained, its applications, limitations, and advancements beyond the Perceptron model. More advanced classifiers like supportvectormachines and neural networks have greater representational power and can learn non-linear decision boundaries.
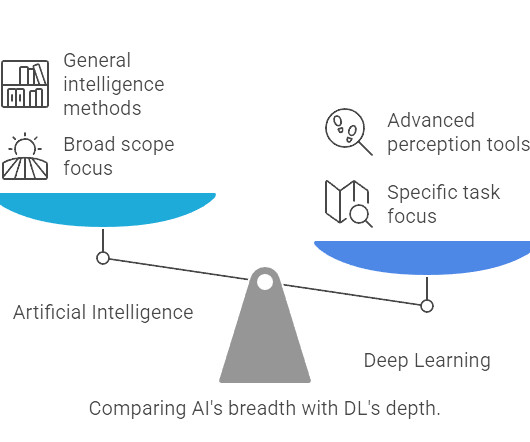
This blog post aims to demystify these powerful concepts. We’ll break down Artificial Intelligence as the overarching goal, introduce its key subset Machine Learning , and then dive deep into Deep Learning , explaining its unique capabilities and how it relates to the others. Is Deep Learning just another name for AI?
Hinge Losses — Another set of losses for classification problems, but commonly used in supportvectormachines. Here is the difference between the different types of losses: Probabilistic Losses — Will be used on classification problems where the output is between 0 and 1. We pay our contributors, and we don’t sell ads.
Some of the top Data Science courses for Kids with Python have been mentioned in this blog for you. Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Read below to find out! Why learn Python for Data Science?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content