
Visualization for Clustering Methods, Gen AI & the Law, and Examples of Doman-Specific LLMS
ODSC - Open Data Science
AUGUST 31, 2023
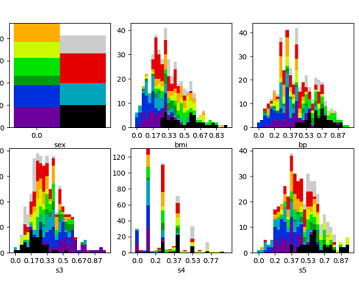
Visualization for Clustering Methods Clustering methods are a big part of data science, and here’s a primer on how you can visualize them. When choosing a data structure, it may benefit you to see which has all the components of the CAP theorem and which best suits your needs. Drowning in Data? Professor Mark A.














Let's personalize your content