This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom data pipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
What is an online transaction processing database (OLTP)? But the true power of OLTP databases lies beyond the mere execution of transactions, and delving into their inner workings is to unravel a complex tapestry of data management, high-performance computing, and real-time responsiveness.
I’m writing a book on Retrieval Augmented Generation (RAG) for Wiley Publishing, and vector databases are an inescapable part of building a performant RAG system. I selected Qdrant as the vector database for my book and this series. For this series and in my book, I will work strictly in the cloud.
Caching is performed on Amazon CloudFront for certain topics to ease the database load. Amazon Aurora PostgreSQL-Compatible Edition and pgvector Amazon Aurora PostgreSQL-Compatible is used as the database, both for the functionality of the application itself and as a vector store using pgvector. Its hosted on AWS Lambda.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The resulting vectors are stored in OpenSearch Service databases for efficient retrieval and querying.
This NoSQL database is optimized for rapid access, making sure the knowledge base remains responsive and searchable. He’s the author of the bestselling book “Interpretable Machine Learning with Python,” and the upcoming book “DIY AI.”
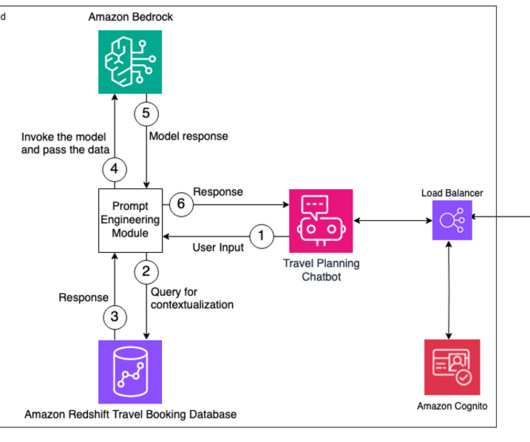
In this post, we discuss how to use the comprehensive capabilities of Amazon Bedrock to perform complex business tasks and improve the customer experience by providing personalization using the data stored in a database like Amazon Redshift. This solution contains two major components. This solution contains two major components.
The SnapLogic Intelligent Integration Platform (IIP) enables organizations to realize enterprise-wide automation by connecting their entire ecosystem of applications, databases, big data, machines and devices, APIs, and more with pre-built, intelligent connectors called Snaps.
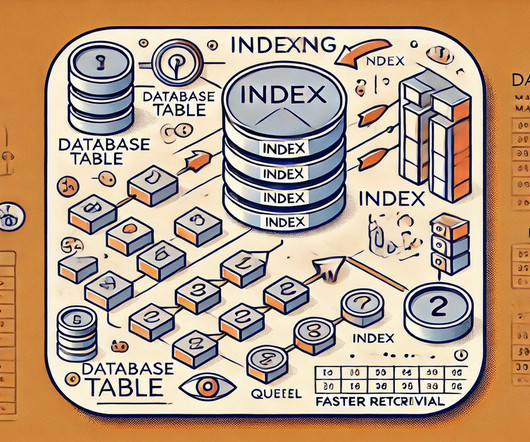
Introduction A Database Management System (DBMS) is essential for efficiently storing, managing, and retrieving application data. As databases grow, performance optimisation becomes critical to ensure quick access to information. One of the most effective techniques for enhancing database performance is indexing in DBMS.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity. Nitin Eusebius is a Sr.
A touchscreen interface that's super laggy, or an appointment booking app that forces you to go in and out of possible dates and fill in all information before it tells you if it's available. The word cluster is an anachronism to an end-user in the cloud! Do you need a database for your test suite? I used to think this was fine!
From structured online courses to insightful books and tutorials and engaging YouTube channels and podcasts, a wealth of content guides you on your journey. Books and Tutorials Books and tutorials are valuable resources for in-depth, self-paced learning. It offers simple and efficient tools for data mining and Data Analysis.
Vectors are typically stored in Vector Databases which are best suited for searching. APIs File Directories Databases And many more The first step is to extract the information present in these source locations. For this we use a special kind of database called the Vector Database. What is a Vector Database?
In this post, we describe how CBRE partnered with AWS Prototyping to develop a custom query environment allowing natural language query (NLQ) prompts by using Amazon Bedrock, AWS Lambda , Amazon Relational Database Service (Amazon RDS), and Amazon OpenSearch Service. Embeddings were generated using Amazon Titan.
A definition from the book ‘Data Mining: Practical Machine Learning Tools and Techniques’, written by, Ian Witten and Eibe Frank describes Data mining as follows: “ Data mining is the extraction of implicit, previously unknown, and potentially useful information from data. Clustering. Data Collection.
As an example, an IT team could easily take the knowledge of database deployment from on-premises and deploy the same solution in the cloud on an always-running virtual machine. Book a strategy session The post What is the Snowflake Data Cloud and How Much Does it Cost?
Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. This process clusters words that often appear together closely in the model’s high-dimensional space. Let’s go back to our history book analogy. That’s how RAG works. president in 1881.
Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. This process clusters words that often appear together closely in the model’s high-dimensional space. Let’s go back to our history book analogy. That’s how RAG works. president in 1881.
Summary: MySQL is a widely used open-source relational database management system known for its reliability and performance. Overview of MySQL MySQL is one of the most popular relational database management systems (RDBMS) in the world, widely used for managing and organizing data.
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. The State of AI Report gives the size and owners of the largest A100 clusters, the top few being Meta with 21,400, Tesla with 16,000, XTX with 10,000, and Stability AI with 5,408.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
Note that this entails a simple way multi-class classification problem for a database with personnel (here, persons or classes). In case of verification, we pre-extract and store the feature representation for all face images in our database, as shown. Figure 3: Face Verification (source: image by the author).
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. Customers are telling us that Neuron has made it easy for them to switch their existing model training and inference pipelines to Trainium and Inferentia with just a few lines of code.
We used FSx for Lustre and Amazon Relational Database Service (Amazon RDS) for fast parallel data access. Sudhanshu has to his credit a couple of patents; has written 2 books, several papers, and blogs; and has presented his point of view in various forums. Store data in an Amazon Simple Storage Service (Amazon S3) bucket.
Examination of this data is critical for monitoring the state of the power grid, identifying infrastructure anomalies, and updating databases of installed assets, and it allows granular control of the infrastructure down to the material and status of the smallest insulator installed on a given pole.
Adapted from the book Effective Data Science Infrastructure. Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge. The intention behind the examples is not to be comprehensive (perhaps a fool’s errand, anyway!), Foundational Infrastructure Layers.
Like traditional database index, vector index organizes the vectors into a data structure and makes it possible to navigate through the vectors and find the ones that are closest in terms of semantic similarity. Clustering — we can cluster our sentences, useful for topic modeling. The main difference is in the pre-training.
For example, if a data team wants to use an LLM to examine financial documents—something the model may perform poorly on out of the box—the team can fine-tune it on something like the Financial Documents Clustering data set. This information could come from: A vector database such as FAISS or Pinecone. Book a demo today.
Case Study Book in Progress! Below is a link to the book outline, Data Science Observations in a Chaotic World , feel free to let me know what you think! From a modeling and coding perspective, preparing case studies may seem time consuming and boring, but it is important to know how to convey results in a clear and concise manner.
In her book, Data lineage from a business perspective , Dr. Irina Steenbeek introduces the concept of descriptive lineage as “a method to record metadata-based data lineage manually in a repository.” Unfortunately, descriptive lineage doesn’t get the attention or recognition it deserves.
Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL! Orchestration tools automate the scheduling and coordination of containers.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. Stacks of books and scrolls next to him and behind him. Let’s play the comparison game. If classic AI is the wise owl, generative AI is the wiser owl with a paintbrush and a knack for writing. Suprisingly small (7B params).
To understand this, imagine you have a pipeline that extracts weather information from an API, cleans the weather information, and loads it into a database. Airflow has four major components, which are The Scheduler The Worker A Database A web server The four major components work in sync to manage data pipelines in Apache Airflow.
I was able to write a book of manageable size that could pretty much explain the whole system. with all the functionality it contains—one would need a book with perhaps 200,000 pages. And in a similar vein, we can expect LLMs to be useful in making connections to external databases, functions, etc. But for Version 14.0—with
Data is chunked into smaller pieces and stored in a vector database, enabling efficient retrieval based on semantic similarity. They can engage users in natural dialogue, provide customer support, answer FAQs, and assist with booking or shopping decisions. You can automatically manage and monitor your clusters using AWS, GCD, or Azure.
For HPC, it’s possible to use a cluster of powerful workstations or servers, each with multiple processors and large amounts of memory. Users who want to dig much deeper with other sources of text can find several books about data centers on Amazon.com or elsewhere. The 11 most essential books for data center directors, on [link] 11.
As you can see, the ImageNet database revolutionized computer vision and has become a catalyst for computer vision tasks! Tesla, for instance, relies on a cluster of NVIDIA A100 GPUs to train their vision-based autonomous driving algorithms. Therefore, in 2024, you will very much run into apps driven by computer vision.
Image from Wallpaper Flare Let’s say you are in a huge library and you want to find a book with a specific topic like “Machine Learning”. With no help, you’d have to go through every single book in the library, which would take a long time. In a library, there is a catalog that lists all the books and what they’re about.
This line of thought was strengthened, a few months later, by codelike writings in a book that came to be associated with the case. The police asked the public for copies of the book in which the final page had been torn out. A man found such a book in his car, where apparently it had been thrown in through an open window.
Summary: This article explores the fundamental differences between clustered and non-clustered index in database management. Understanding these distinctions is crucial for optimizing data retrieval and ensuring efficient database operations, ultimately leading to improved application performance and user experience.
Indexes enable faster data retrieval, optimize joins, and enhance database efficiency. Introduction In the world of databases, query performance is paramount. One of the most powerful tools in a database administrator’s or developer’s arsenal to combat slow queries is database indexing.
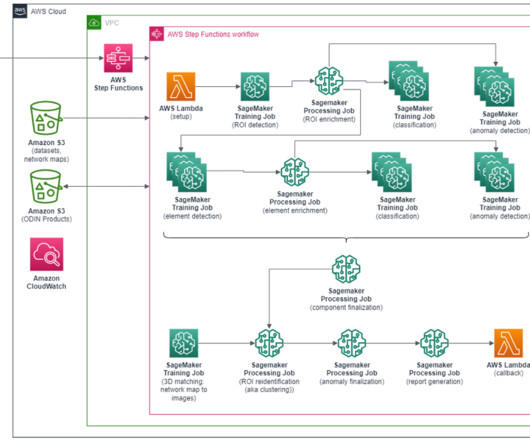
During the training process, our SageMaker HyperPod cluster was connected to this S3 bucket, enabling effortless retrieval of the dataset elements as needed. To take advantage of distributed training, a cluster of interconnected GPUs, often spread across multiple physical nodes, is required.
By employing a multi-modal approach, the solution connects relevant data elements across various databases. The app container is deployed using a cost-optimal AWS microservice-based architecture using Amazon Elastic Container Service (Amazon ECS) clusters and AWS Fargate.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content