This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Hey Guys, Hope you are doing well. The post K-Means Clustering and Transfer Learning for Image Classification appeared first on Analytics Vidhya. This article will.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. In October 2022, we launched Amazon EC2 Trn1 Instances , powered by AWS Trainium , which is the second generation machine learning accelerator designed by AWS. We use Slurm as the cluster management and job scheduling system.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
As a result, machine learning practitioners must spend weeks of preparation to scale their LLM workloads to large clusters of GPUs. Integrating tensor parallelism to enable training on massive clusters This release of SMP also expands PyTorch FSDP’s capabilities to include tensor parallelism techniques.
Summary: This curated list of 20 Artificial Intelligence books for beginners highlights foundational concepts, coding practices, and ethical insights. This blog highlights the 20 best Artificial Intelligence books tailored for newcomers, offering practical insights, ethical considerations, and real-world applications.
After trillions of linear algebra computations, it can take a new picture and segment it into clusters. Deeplearning multiple– layer artificial neural networks are the basis of deeplearning, a subdivision of machine learning (hence the word “deep”). GIS Random Forest script.
Face Recognition One of the most effective Github Projects on Data Science is a Face Recognition project that makes use of DeepLearning and Histogram of Oriented Gradients (HOG) algorithm. Customer Segmentation using K-Means Clustering One of the most crucial uses of data science is customer segmentation.
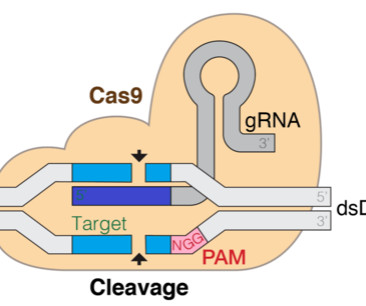
The clustered regularly interspaced short palindromic repeat (CRISPR) technology holds the promise to revolutionize gene editing technologies, which is transformative to the way we understand and treat diseases. DNABERT 6 Dataset For this post, we use the gRNA data released by researchers in a paper about gRNA prediction using deeplearning.
To learn how to develop Face Recognition applications using Siamese Networks, just keep reading. Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deeplearning models tend to develop a bias toward the data distribution on which they have been trained. That’s not the case.
John Holland’s book “ Adaptation in Natural and Artificial Systems ” (1975) further popularized genetic algorithms. Evolutionary computing in data science Evolutionary computing algorithms have been widely used in data science for tasks such as feature selection, data clustering, classification, and regression.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? That’s not the case.
movies, books, videos, or music) for any user. ClusteringClustering is a class of algorithms that segregates the data into a set of definite clusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g.,
Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations?
Note the following calculations: The size of the global batch is (number of nodes in a cluster) * (number of GPUs per node) * (per batch shard) A batch shard (small batch) is a subset of the dataset assigned to each GPU (worker) per iteration BigBasket used the SMDDP library to reduce their overall training time.
This model is deployed using the text-generation-inference (TGI) deeplearning container. Read widely: Reading books, articles, and blogs from different genres and subjects exposes you to new words and phrases. user Thank you for recommending these books to me! Assistant: Certainly! model You’re welcome!
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deeplearning has achieved remarkable success in supervised tasks, especially in image recognition. Similar class labels tend to form clusters, as observed with the Convolutional Autoencoder. That’s not the case.
Jump Right To The Downloads Section Deploying a Custom Image Classifier on an OAK-D Introduction As a deeplearning engineer or practitioner, you may be working in a team building a product that requires you to train deeplearning models on a specific data modality (e.g., computer vision) on a daily basis.
Step-by-Step Guide to Learning AI in 2024 Learning AI can seem daunting at first, but by following a structured approach, you can build a solid foundation and gain the skills needed to thrive in this field. This step-by-step guide will take you through the critical stages of learning AI from scratch. Let’s dive in!
From the earliest days, Amazon has used ML for various use cases such as book recommendations, search, and fraud detection. Similar to the rest of the industry, the advancements of accelerated hardware have allowed Amazon teams to pursue model architectures using neural networks and deeplearning (DL).
Not only is data larger, but models—deeplearning models in particular—are much larger than before. Adapted from the book Effective Data Science Infrastructure. Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge.
nn[”yes”, ”no”] yes question answering Answer based on context:nn The newest and most innovative Kindle yet lets you take notes on millions of books and documents, write lists and journals, and more. He focuses on developing scalable machine learning algorithms.
Clustering — we can cluster our sentences, useful for topic modeling. BERT was pre-trained on a book corpus and on Wikipedia for producing a language model (see the BERT paper). The article is clustering “Fine Food Reviews” dataset. Enables search to be performed on concepts (rather than specific words).
This kind of structured setup is common in deeplearning projects to organize outputs and model checkpoints systematically. The chosen optimizer is the Adam optimizer, a popular optimization algorithm in deeplearning. The optimizer requires the model’s parameters ( model.parameters() ) and a learning rate ( config.LR
Nature of Content — Consider whether you are working with lengthy documents, such as articles or books, or shorter content like tweets or instant messages. As a general definition, embeddings are data that has been transformed into n-dimensional matrices for use in deeplearning computations.
Citing the original description: This is the classification based E-commerce text dataset for 4 categories — “Electronics”, “Household”, “Books” and “Clothing & Accessories”, which almost cover 80% of any E-commerce website. […] The dataset has been scraped from Indian e-commerce platform. Thus, let’s download it and explore it!
Tesla, for instance, relies on a cluster of NVIDIA A100 GPUs to train their vision-based autonomous driving algorithms. Selecting robust hardware and infrastructure, incorporating cloud services for scalable resources, and keeping algorithms and models updated with advancements in deeplearning and AI to enhance accuracy is also essential.
Overview of Airflow Architecture (Image from Data Pipelines from Apache Airflow Book) Given that you now understand the core concept behind Airflow and the components that make up Apache Airflow, the next step is a practical hands-on. The celery flower is used for managing the celery cluster, which is not needed for a local executor.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. This doesnt imply that clusters coudnt be highly separable in higher dimensions.
What helped me both in the transition to the data scientist role and then also to the MLOps engineer role was doing a combination of boot camps, and when I was going to the MLOps engineer role, I also took this one workshop that’s pretty well-known called Full Stack DeepLearning. I really enjoyed it. How was my code?”
Now, with today’s announcement, you have another straightforward compute option for workflows that need to train or fine-tune demanding deeplearning models: running them on Trainium. He is also the author of a book, Effective Data Science Infrastructure, published by Manning.
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity. Why do we need an embeddings model?
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Traditional AI can recognize, classify, and cluster, but not generate the data it is trained on. al 600+: Key technological concepts of generative AI 300+: DeepLearning — the core of any generative AI model: Deeplearning is a central concept of traditional AI that has been adopted and further developed in generative AI.
Databricks is getting up to 40% better price-performance with Trainium-based instances to train large-scale deeplearning models. Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. And Amazon Bedrock can help with this challenge.
He focuses on Deeplearning including NLP and Computer Vision domains. Since joining SnapLogic in 2010, Greg has helped design and implement several key platform features including cluster processing, big data processing, the cloud architecture, and machine learning.
books, magazines, newspapers, forms, street signs, restaurant menus) so that they can be indexed, searched, translated, and further processed by state-of-the-art natural language processing techniques. Middle: Illustration of line clustering. Right: Illustration paragraph clustering. Samples from the HierText dataset.
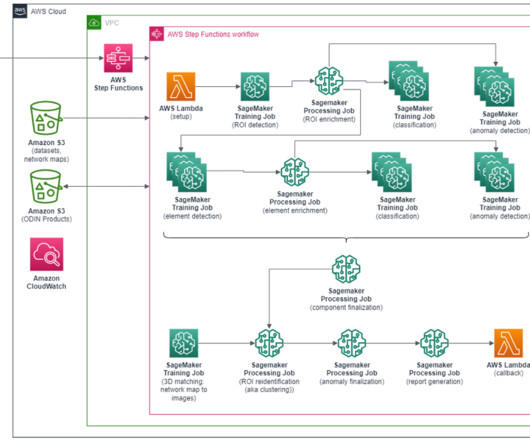
Fortunately, thanks to enormous advances in the world of computer vision and deeplearning and the maturity and democratization of these technologies, it’s possible to automate this expensive process partially or even completely. This allows the clustering of ROIs referring to the same pole.
Redmon and Farhadi (2017) published YOLOv2 at the CVPR Conference and improved the original model by incorporating batch normalization, anchor boxes, and dimension clusters. Do you think learning computer vision and deeplearning has to be time-consuming, overwhelming, and complicated? The authors continued from there.
Course information: 86 total classes • 115+ hours of on-demand code walkthrough videos • Last updated: October 2024 ★★★★★ 4.84 (128 Ratings) • 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning. Or has to involve complex mathematics and equations?
Recent scientific breakthroughs in deeplearning (DL), large language models (LLMs), and generative AI is allowing customers to use advanced state-of-the-art solutions with almost human-like performance. In this post, we show how to run multiple deeplearning ensemble models on a GPU instance with a SageMaker MME.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content